Bug #6480
closedlibrbd crashed qemu-system-x86_64
0%
Description
Running Ceph 0.67.3 and qemu 1.5.2
- Error in `qemu-system-x86_64': invalid fastbin entry (free): 0x00007fab795cce40 ***
======= Backtrace: =========
/lib/x86_64-linux-gnu/libc.so.6(+0x80a46)[0x7faeab8b1a46]
/usr/lib/librbd.so.1(_ZNSt10_List_baseIN4ceph6buffer3ptrESaIS2_EE8_M_clearEv+0x27)[0x7faeb1896747]
/usr/lib/librados.so.2(_Z21encode_encrypt_enc_blIN4ceph6buffer4listEEvP11CephContextRKT_RK9CryptoKeyRS2_RSs+0x10f)[0x7faeb0bd164f]
/usr/lib/librados.so.2(_Z14encode_encryptIN4ceph6buffer4listEEiP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xa2)[0x7faeb0bd1772]
/usr/lib/librados.so.2(_ZN19CephxSessionHandler12sign_messageEP7Message+0x242)[0x7faeb0bd0c42]
/usr/lib/librados.so.2(_ZN4Pipe6writerEv+0x92b)[0x7faeb0cf19bb]
/usr/lib/librados.so.2(_ZN4Pipe6Writer5entryEv+0xd)[0x7faeb0cfc68d]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x7f8e)[0x7faeabc00f8e]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7faeab92ae1d] ======= Memory map: ========
<snip>
2013-10-07 16:27:41.105+0000: shutting down
I do not have any rbd logs.
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Updated by Samuel Just over 10 years ago
- Project changed from Ceph to rbd
- Category deleted (
librbd) - Priority changed from Normal to High
Updated by Sage Weil over 10 years ago
- Status changed from New to Need More Info
- Source changed from other to Community (user)
is there anything you can share about the workload that triggered this? we haven't seen this one before.
Updated by Mike Dawson over 10 years ago
I have only seen it once in over 6-months of running a dozen VMs that run video surveillance workloads. These are Windows boxes with about a 95% write to 5% read ratio. The writes average ~16KB each in the guest. RBD writeback cache is enabled.
Sorry there isn't more to go on.
Updated by Mike Dawson over 10 years ago
Hit a similar crash with a slightly different backtrace this today. Different host and vm. Both hosts have similar configurations and the vm's run similar workloads.
This time the backtrace was:
- Error in `qemu-system-x86_64': invalid fastbin entry (free): 0x00007f86c4d2afe0 ***
======= Backtrace: =========
/lib/x86_64-linux-gnu/libc.so.6(+0x80a46)[0x7f898546ba46]
/usr/lib/x86_64-linux-gnu/libnss3.so(PK11_GetAllTokens+0x1d8)[0x7f89849afbd8]
/usr/lib/x86_64-linux-gnu/libnss3.so(PK11_GetBestSlotMultipleWithAttributes+0x24d)[0x7f89849b002d]
/usr/lib/x86_64-linux-gnu/libnss3.so(PK11_GetBestSlot+0x1f)[0x7f89849b009f]
/usr/lib/librados.so.2(+0x29e231)[0x7f898a78d231]
/usr/lib/librados.so.2(_ZNK9CryptoKey7encryptEP11CephContextRKN4ceph6buffer4listERS4_RSs+0x71)[0x7f898a78c4c1]
/usr/lib/librados.so.2(_Z21encode_encrypt_enc_blIN4ceph6buffer4listEEvP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xfe)[0x7f898a78b63e]
/usr/lib/librados.so.2(_Z14encode_encryptIN4ceph6buffer4listEEiP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xa2)[0x7f898a78b772]
/usr/lib/librados.so.2(_ZN19CephxSessionHandler12sign_messageEP7Message+0x242)[0x7f898a78ac42]
/usr/lib/librados.so.2(_ZN4Pipe6writerEv+0x92b)[0x7f898a8ab9bb]
/usr/lib/librados.so.2(_ZN4Pipe6Writer5entryEv+0xd)[0x7f898a8b668d]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x7f8e)[0x7f89857baf8e]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7f89854e4e1d
Full qemu log with memory map attached.
Updated by Mike Dawson over 10 years ago
One more crash today. Again, different host and guest with similar config and workloads.
- Error in `qemu-system-x86_64': invalid fastbin entry (free): 0x00007f5a307c7f50 ***
======= Backtrace: =========
/lib/x86_64-linux-gnu/libc.so.6(+0x80a46)[0x7f5c8f864a46]
/usr/lib/librados.so.2(_ZN4ceph6buffer8raw_charD0Ev+0x20)[0x7f5c94d15d40]
/usr/lib/librados.so.2(_ZN4ceph6buffer3ptr7releaseEv+0x3e)[0x7f5c94d1152e]
/usr/lib/librbd.so.1(_ZNSt10_List_baseIN4ceph6buffer3ptrESaIS2_EE8_M_clearEv+0x1c)[0x7f5c9584973c]
/usr/lib/librados.so.2(_ZN19CephxSessionHandler23check_message_signatureEP7Message+0x162)[0x7f5c94b82822]
/usr/lib/librados.so.2(_ZN4Pipe12read_messageEPP7Message+0xdcc)[0x7f5c94c9a62c]
/usr/lib/librados.so.2(_ZN4Pipe6readerEv+0xa5c)[0x7f5c94cabe7c]
/usr/lib/librados.so.2(_ZN4Pipe6Reader5entryEv+0xd)[0x7f5c94caf7ad]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x7f8e)[0x7f5c8fbb3f8e]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7f5c8f8dde1d
Full log attached.
Updated by Mike Dawson over 10 years ago
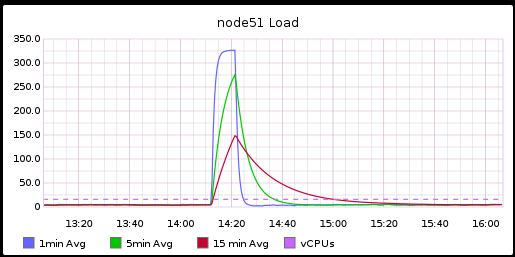
Just discovered that the load on the host spikes when the crash occurs. I don't have info on the first, but the past two crashes show load spiking up to a 1-minute average of around 325 on the hypervisor host. These are boxes have 2x Intel E5520s.
Updated by Sage Weil over 10 years ago
Mike Dawson wrote:
Just discovered that the load on the host spikes when the crash occurs. I don't have info on the first, but the past two crashes show load spiking up to a 1-minute average of around 325 on the hypervisor host. These are boxes have 2x Intel E5520s.
interesting. is there a memory or network spike or anything else obvious going on at the same time?
Updated by Mike Dawson over 10 years ago
Memory usage on the host looks stable. Traffic on the host dips because it loses the crashed guest's traffic. Disk util is a bit elevated on the OS drive (I believe that is writing the core dump).
Updated by Andrey Korolyov over 10 years ago
- File daily-workload.png daily-workload.png added
- File hourly-workload.png hourly-workload.png added
- File weekly-workload.png weekly-workload.png added
The same on cuttlefish. Attached graphs are for the problematic VM for different periods.
Updated by Igor Lukyanov over 10 years ago
In addition to comment posted by Andrey:
The disk workload of the VM was very peaky: http://imgur.com/SLFdJvv
VM crashed as soon as filesystem run out of free space http://imgur.com/e7SI7B5
- glibc detected * /usr/bin/kvm: invalid fastbin entry (free): 0x00007fd520001500 *
======= Backtrace: =========
/lib/x86_64-linux-gnu/libc.so.6(+0x7e566)[0x7fd6289e4566]
/usr/lib/librados.so.2(_ZNSt8_Rb_treeImSt4pairIKmSt4listIS0_IjN13DispatchQueue9QueueItemEESaIS5_EEESt10_Select1stIS8_ESt4lessImESaIS8_EE12_M_erase_auxESt23_Rb_tree_const_iteratorIS8_E+0x31)[0x7fd62bf56a01]
/usr/lib/librados.so.2(_ZN16PrioritizedQueueIN13DispatchQueue9QueueItemEmE7dequeueEv+0x913)[0x7fd62bf57333]
/usr/lib/librados.so.2(_ZN13DispatchQueue5entryEv+0x1c7)[0x7fd62bf53f07]
/usr/lib/librados.so.2(_ZN13DispatchQueue14DispatchThread5entryEv+0xd)[0x7fd62bfbc60d]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x7e9a)[0x7fd628d2ae9a]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7fd628a583dd]
Updated by Igor Lukyanov over 10 years ago
They say there was a bug in malloc in libc 2.15 (we have the same major version)
https://jira.mongodb.org/browse/SERVER-5174
https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=5f24d53acb2cd02ffb4ac925c0244e4f1f854499;hp=d84acf388ed8b3f162dda0512139095bfc268beb
so it might be a reason of the crash in our case too. Though i'm not familiar with neither libc nor ceph internals so this analogue may be irrelevant.
Updated by Igor Lukyanov over 10 years ago
Igor Lukyanov wrote:
They say there was a bug in malloc in libc 2.15 (we have the same major version)
https://jira.mongodb.org/browse/SERVER-5174
https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=5f24d53acb2cd02ffb4ac925c0244e4f1f854499;hp=d84acf388ed8b3f162dda0512139095bfc268bebso it might be a reason of the crash in our case too. Though i'm not familiar with neither libc nor ceph internals so this assumption may be irrelevant.
Updated by Ian Colle about 10 years ago
- Status changed from Need More Info to Can't reproduce
Updated by Josh Durgin about 10 years ago
- Status changed from Can't reproduce to Need More Info
...and now there's a new similar instance, this time on rhel:
Program terminated with signal 11, Segmentation fault. #0 0x00007fa0d2ddb7cb in ceph::buffer::ptr::release (this=0x7f987a5e3070) at common/buffer.cc:370 370 common/buffer.cc: No such file or directory. in common/buffer.cc (gdb) bt #0 0x00007fa0d2ddb7cb in ceph::buffer::ptr::release (this=0x7f987a5e3070) at common/buffer.cc:370 #1 0x00007fa0d2ddec00 in ~ptr (this=0x7f989c03b830) at ./include/buffer.h:171 #2 ceph::buffer::list::rebuild (this=0x7f989c03b830) at common/buffer.cc:817 #3 0x00007fa0d2ddecb9 in ceph::buffer::list::c_str (this=0x7f989c03b830) at common/buffer.cc:1045 #4 0x00007fa0d2ea4dc2 in Pipe::connect (this=0x7fa0c4307340) at msg/Pipe.cc:907 #5 0x00007fa0d2ea7d73 in Pipe::writer (this=0x7fa0c4307340) at msg/Pipe.cc:1518 #6 0x00007fa0d2eb44dd in Pipe::Writer::entry (this=<value optimized out>) at msg/Pipe.h:59 #7 0x00007fa0e0f5f9d1 in start_thread (arg=0x7f987a5e4700) at pthread_create.c:301 #8 0x00007fa0de560b6d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:115
Updated by Andrey Korolyov about 10 years ago
Just a note, bug itself is very unlikely to reproduce in a short times (one crash per 1k VM instances per month or so).
Updated by Mike Dawson about 10 years ago
Still getting these crashes multiple times a week across a dozen guests on separate hosts. These guests are video surveillance DVRs, so they tend to have full drives that are constantly overwriting the oldest data with new video. Writes average ~16KB each, with each guest taking a max of about 5MB/s of write throughput. We're using RBD writeback cache.
- head -100 qemu/instance-00000027.log
- Error in `qemu-system-x86_64': invalid fastbin entry (free): 0x00007ff12887ff20 ***
======= Backtrace: =========
/lib/x86_64-linux-gnu/libc.so.6(+0x80a46)[0x7ff3dea1fa46]
/usr/lib/librados.so.2(+0x29eb03)[0x7ff3e3d43b03]
/usr/lib/librados.so.2(_ZNK9CryptoKey7encryptEP11CephContextRKN4ceph6buffer4listERS4_RSs+0x71)[0x7ff3e3d42661]
/usr/lib/librados.so.2(_Z21encode_encrypt_enc_blIN4ceph6buffer4listEEvP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xfe)[0x7ff3e3d417de]
/usr/lib/librados.so.2(_Z14encode_encryptIN4ceph6buffer4listEEiP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xa2)[0x7ff3e3d41912]
/usr/lib/librados.so.2(_ZN19CephxSessionHandler12sign_messageEP7Message+0x242)[0x7ff3e3d40de2]
/usr/lib/librados.so.2(_ZN4Pipe6writerEv+0x92b)[0x7ff3e3e61b2b]
/usr/lib/librados.so.2(_ZN4Pipe6Writer5entryEv+0xd)[0x7ff3e3e6c7fd]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x7f8e)[0x7ff3ded6ff8e]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7ff3dea99a0d] ======= Memory map: ========
...
- Error in `qemu-system-x86_64': invalid fastbin entry (free): 0x00007ff12887ff20 ***
======= Backtrace: =========
Updated by Ian Colle about 10 years ago
- Status changed from Need More Info to 12
- Assignee set to Josh Durgin
- Priority changed from High to Urgent
Updated by Mike Dawson about 10 years ago
One more:
*** Error in `qemu-system-x86_64': invalid fastbin entry (free): 0x00007f42a4002de0 *** ======= Backtrace: ========= /lib/x86_64-linux-gnu/libc.so.6(+0x80a46)[0x7f452f1f3a46] /usr/lib/x86_64-linux-gnu/libnss3.so(PK11_FreeSymKey+0xa8)[0x7f452e72ff98] /usr/lib/librados.so.2(+0x2a18cd)[0x7f453451a8cd] /usr/lib/librados.so.2(_ZNK9CryptoKey7encryptEP11CephContextRKN4ceph6buffer4listERS4_RSs+0x71)[0x7f4534519421] /usr/lib/librados.so.2(_Z21encode_encrypt_enc_blIN4ceph6buffer4listEEvP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xfe)[0x7f453451859e] /usr/lib/librados.so.2(_Z14encode_encryptIN4ceph6buffer4listEEiP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xa2)[0x7f45345186d2] /usr/lib/librados.so.2(_ZN19CephxSessionHandler23check_message_signatureEP7Message+0x246)[0x7f4534516866] /usr/lib/librados.so.2(_ZN4Pipe12read_messageEPP7Message+0xdcc)[0x7f453462ecbc] /usr/lib/librados.so.2(_ZN4Pipe6readerEv+0xa5c)[0x7f453464059c] /usr/lib/librados.so.2(_ZN4Pipe6Reader5entryEv+0xd)[0x7f4534643ecd] /lib/x86_64-linux-gnu/libpthread.so.0(+0x7f8e)[0x7f452f543f8e] /lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7f452f26da0d] ======= Memory map: ======== ...
Josh, What can I do here to get you more information?
Updated by Josh Durgin about 10 years ago
- Status changed from 12 to In Progress
Mike provided a core dump in which structures appear to be normal, though it's hard to tell with the ceph::buffer::raw buffer holding the session key since that type isn't included in the debug info. It's possible it's corrupted, but it's difficult to tell since it's supposed to be random.
Looking through the related code, it looks like there's at least one potential unsafe use of the session key:
The Pipe::writer thread assigns to the session_security object (containing the session key) while holding the pipe_lock in connect().
At the same time the Pipe::reader uses the session_security object (and the session key) while it is not holding the pipe_lock (it's dropped while read_message() is called).
I'm not too familiar with the messenger, so this race might be impossible for some other reason, but I suspect there's more than one bug here.
Updated by Josh Durgin about 10 years ago
I found another source of race conditions, and hopefully fixed them in the wip-6480-0.67.7 branch. I'm running tests to make sure it doesn't break anything (the most likely regression is a hang). Mike, could you try upgrading librbd and librados to that branch and running some test vms on them? I think this addresses all the races in this bug, but there may be more.
Updated by Andrey Korolyov about 10 years ago
This may help somehow - recently I`ve started to collect perf samples via endless loop on selected hosts and some hosts threw out gfp allocation error due to low memory condition on the lowest NUMA node. Those hosts also tended to produce same errors as in this bug(qemu processes w/o strict NUMA pinning), so it is almost clearly a race. Just FYI.
Updated by Mike Dawson about 10 years ago
Josh, I am now running wip-6480-0.67.7 across our whole infrastructure. No issues yet. Because the race is rare, I think a week or two will be needed to have more certainty that the issue is resolved.
Andrey, could you test this branch, too?
Updated by Sage Weil about 10 years ago
- Status changed from 7 to Pending Backport
Updated by Mike Dawson about 10 years ago
I've run wip-6480-0.67.7 across our infrastructure for 10 days now without any qemu crashes. Thanks Josh!
Updated by Josh Durgin about 10 years ago
- Status changed from Pending Backport to Resolved
Thanks for the update Mike! Backported the fixes to dumpling (commit:2b4b00b76b245b1ac6f95e4537b1d1a4656715d5 commit:c049967af829497f8a62e0cbbd6031f85ead8a59) and emperor (commit:f6d1d922ff8afc2634a20711710f9fb34c735827 commit:27d6032ef6dbaa521176be71758609448db1fca9).
Updated by Andrey Korolyov over 9 years ago
- File vm90277.bt.txt vm90277.bt.txt added
Hi, another cephx crash (vm90277.bt.txt). Lines are related to latest cuttlefish and this crash appears for a first time over one hundred of thousands of VM spawns.
- glibc detected * qemu-system-x86_64: invalid fastbin entry (free): 0x00007fd49800ad80 *
======= Backtrace: =========
/lib/x86_64-linux-gnu/libc.so.6(+0x7e566)[0x7fd7f70be566]
/usr/lib/x86_64-linux-gnu/libnssutil3.so(SECITEM_FreeItem_Util+0x21)[0x7fd7f5622201]
/usr/lib/x86_64-linux-gnu/libnss3.so(PK11_DestroyContext+0x56)[0x7fd7f5870bf6]
/usr/lib/librados.so.2(+0x21c994)[0x7fd7fadda994]
/usr/lib/librados.so.2(_ZNK9CryptoKey7encryptEP11CephContextRKN4ceph6buffer4listERS4_RSs+0x71)[0x7fd7fadd9711]
/usr/lib/librados.so.2(_Z21encode_encrypt_enc_blIN4ceph6buffer4listEEvP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xfe)[0x7fd7fadd8c2e]
/usr/lib/librados.so.2(_Z14encode_encryptIN4ceph6buffer4listEEiP11CephContextRKT_RK9CryptoKeyRS2_RSs+0xa2)[0x7fd7fadd8d52]
/usr/lib/librados.so.2(_ZN19CephxSessionHandler23check_message_signatureEP7Message+0x246)[0x7fd7fadd6ec6]
/usr/lib/librados.so.2(_ZN4Pipe12read_messageEPP7Message+0x19b2)[0x7fd7faeb7eb2]
/usr/lib/librados.so.2(_ZN4Pipe6readerEv+0xa7c)[0x7fd7faec88bc]
/usr/lib/librados.so.2(_ZN4Pipe6Reader5entryEv+0xd)[0x7fd7faecc14d]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x7e9a)[0x7fd7f7404e9a]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x6d)[0x7fd7f71323dd]
Updated by Josh Durgin over 9 years ago
Hi Andrey, that does look like this bug on cuttlefish. We haven't been backporting anything to cuttlefish for a long time now (including the fix for this bug). I'd suggest upgrading to dumpling or firefly.
Updated by Andrey Korolyov over 9 years ago
Yes, I had no assumption to make a fix for a cuttlefish on purpose. I asked Mike (as he running newer release) to compare his occasional after-6480 crashes with backtrace above. As I have received none of cephx-related crashes after backporting this fix to cuttlefish, there is a chance that we may face the same issue.
Updated by Josh Durgin about 8 years ago
- Related to Backport #14620: hammer: unsafe use of libnss PK11_GetBestSlot() added
Updated by Josh Durgin about 8 years ago
This resurfaced in a similar form on a hammer cluster. After some analysis of the core file, it appeared that some of the libnss functions we use in this path are not threadsafe (in particular PK11_GetBestSlot()).
Post-hammer, these functions had already been refactored to be called once from a single thread as an optimization, so I backported that to hammer. #14620 tracks this backport.
Updated by wb song over 6 years ago
IMHO, it was an issue in glibc: https://bugzilla.redhat.com/show_bug.cgi?id=1305406