Bug #18041
closedperiodically kernel crashes with CephFS
0%
Description
Hi,
last few days we are having ~5-15 kernel crashes according to:
Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: ------------[ cut here ]------------ Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: kernel BUG at fs/ceph/inode.c:1272! Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: invalid opcode: 0000 [#1] SMP Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: Modules linked in: veth ip6t_REJECT nf_reject_ipv6 ipt_REJECT nf_reject_ipv4 ebtable_filter ebtables tun rpcsec_gss_krb5 nfsv4 ceph dns_resolver l Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: acpi_pad nfsd auth_rpcgss nfs_acl lockd grace sunrpc ip_tables xfs libcrc32c sd_mod crc32c_intel ast drm_kms_helper syscopyarea sysfillrect sysim Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: CPU: 3 PID: 41021 Comm: kworker/3:2 Not tainted 4.8.4-1.el7.elrepo.x86_64 #1 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: Hardware name: Supermicro SYS-2028TR-H72R/X10DRT-H, BIOS 2.0a 03/08/2016 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: Workqueue: ceph-msgr ceph_con_workfn [libceph] Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: task: ffff881e33dada00 task.stack: ffff881a1100c000 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: RIP: 0010:[<ffffffffa07cb729>] [<ffffffffa07cb729>] ceph_fill_trace+0x889/0x890 [ceph] Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: RSP: 0018:ffff881a1100fb78 EFLAGS: 00010283 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: RAX: ffff883b4816b8c0 RBX: 0000000000000000 RCX: 0000000100220002 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: RDX: ffff881fc0ee6800 RSI: ffffea00734e7500 RDI: ffff883fef953a10 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: RBP: ffff881a1100fbe8 R08: ffff881cd39d4ca8 R09: 0000000100220002 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: R10: 00000000d39d4b01 R11: ffff881cd39d4ca8 R12: ffff881c7ed95128 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: R13: ffff8817ad2f8348 R14: ffff88171ecbbb00 R15: ffff881fe80e2c00 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: FS: 0000000000000000(0000) GS:ffff881fff8c0000(0000) knlGS:0000000000000000 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: CR2: 00007fd19f407000 CR3: 0000000001c06000 CR4: 00000000003406e0 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: Stack: Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: ffff881fe80e2f68 ffff881a1100fc48 ffff881fc0ee6a69 ffff883ff11df100 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: ffff883ff13b9000 ffff883ff0712000 ffff881a1100fba8 ffff881a1100fba8 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: 00000000a21363b4 ffff883fef953800 ffff8818a9f83500 ffff881fe80e2c90 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: Call Trace: Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffffa07eb2af>] handle_reply+0x46f/0xbb0 [ceph] Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffffa07ed4e8>] dispatch+0xd8/0xa60 [ceph] Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffffa072ee3e>] try_read+0x9be/0x11a0 [libceph] Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff810b936d>] ? set_next_entity+0x4d/0x7c0 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff810ba865>] ? put_prev_entity+0x35/0x380 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff810b8b25>] ? pick_next_entity+0xa5/0x160 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffffa072f6ca>] ceph_con_workfn+0xaa/0x5d0 [libceph] Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff8109ad42>] process_one_work+0x152/0x400 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff8109b635>] worker_thread+0x125/0x4b0 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff8109b510>] ? rescuer_thread+0x380/0x380 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff810a1128>] kthread+0xd8/0xf0 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff8173ad3f>] ret_from_fork+0x1f/0x40 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: [<ffffffff810a1050>] ? kthread_park+0x60/0x60 Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: Code: 00 00 48 c7 c7 ed f7 7f a0 c6 05 d3 71 04 00 01 e8 7d 61 8b e0 49 8b 97 60 01 00 00 31 db 0f b6 42 0e e9 3b f8 ff ff 0f 0b 0f 0b <0f> 0b 0f Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: RIP [<ffffffffa07cb729>] ceph_fill_trace+0x889/0x890 [ceph] Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: RSP <ffff881a1100fb78> Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: ---[ end trace 6c925a3b3290a20f ]--- Nov 25 12:14:01 us-imm-node1a.000webhost.io kernel: Kernel panic - not syncing: Fatal exception -- Reboot --
Kernel version is: 4.8.4-1.el7.elrepo.x86_64
/etc/ceph/ceph.conf (client side):
[root@us-imm-node1a ~]# cat /etc/ceph/ceph.conf [global] fsid = fc43f491-9693-48d3-91be-d5bb2b7a085e mon initial members = v6.us-imm-cephmon1.000webhost.io,v6.us-imm-cephmon2.000webhost.io,v6.us-imm-cephmon3.000webhost.io mon host = v6.us-imm-cephmon1.000webhost.io,v6.us-imm-cephmon2.000webhost.io,v6.us-imm-cephmon3.000webhost.io auth cluster required = cephx auth service required = cephx auth client required = cephx ms bind ipv6 = true [osd] osd crush update on start = false
Any comments?
If you miss something more here, do not hesitate!
Files
{kind=link}
{kind=link}
Updated by John Spray over 7 years ago
- Assignee changed from John Spray to Zheng Yan
Any more clues about what else might have changed in the last few days?
Updated by Aurimas Lapiene over 7 years ago
- File ceph-mds.v6.us-imm-cephmon1.log ceph-mds.v6.us-imm-cephmon1.log added
- File ceph-mds.v6.us-imm-cephmon2.log ceph-mds.v6.us-imm-cephmon2.log added
More info about the incident.
Topology:
2 osd nodes with 24 total osds
3 monitor/mds nodes
6 cephfs kernel clients
Earlier before kernel panic cephmon2 was master mds. About an hour before slow requests started to grow, then mds stopped responding and master respawned on cephmon1. Kernel panic happened after cephfs clients reconnected to new mds master cephmon1.
Yesterday we enabled cronjob
echo 2 > /proc/sys/vm/drop_cachesevery 2h to get rid of
mds0: Client <client> failing to respond to cache pressurewarning. Before this cronjob this warning was on for all 6 clients.
See attached logs for more details from cephmon1 and cephmon2.
Updated by Ilya Dryomov over 7 years ago
- Project changed from CephFS to Linux kernel client
Updated by Donatas Abraitis over 7 years ago
[root@us-imm-cephmon1 ~]# ceph -s
cluster fc43f491-9693-48d3-91be-d5bb2b7a085e
health HEALTH_WARN
nodeep-scrub,sortbitwise flag(s) set
monmap e4: 3 mons at {us-imm-cephmon1=[2a02:4780:bad:c0de::d]:6789/0,us-imm-cephmon2=[2a02:4780:bad:c0de::17]:6789/0,us-imm-cephmon3=[2a02:4780:bad:c0de::18]:6789/0}
election epoch 140, quorum 0,1,2 us-imm-cephmon1,us-imm-cephmon2,us-imm-cephmon3
fsmap e154905: 1/1/1 up {0=v6.us-imm-cephmon1=up:active}, 2 up:standby
osdmap e4228: 27 osds: 27 up, 27 in
flags nodeep-scrub,sortbitwise
pgmap v4950900: 768 pgs, 3 pools, 2181 GB data, 114 Mobjects
5874 GB used, 127 TB / 133 TB avail
759 active+clean
9 active+clean+scrubbing
client io 2025 kB/s rd, 3252 kB/s wr, 191 op/s rd, 832 op/s wr
Updated by Aurimas Lapiene over 7 years ago
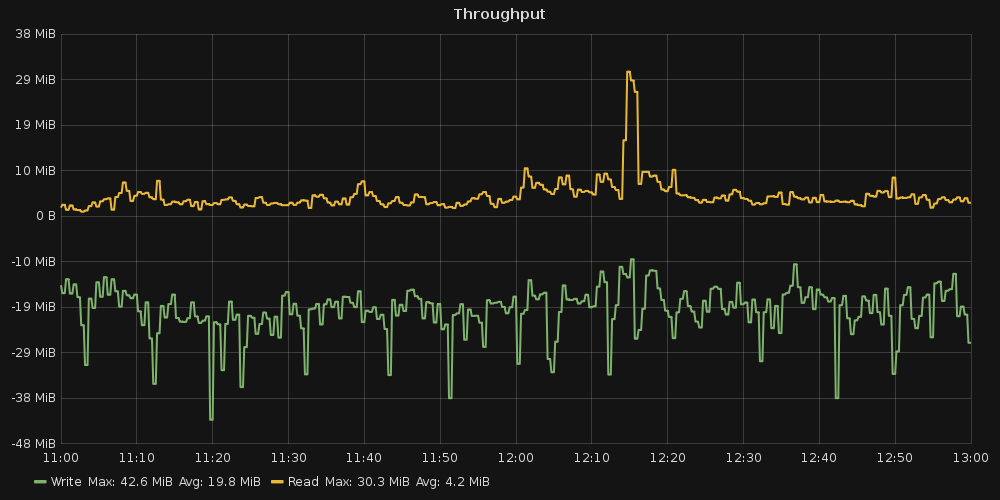
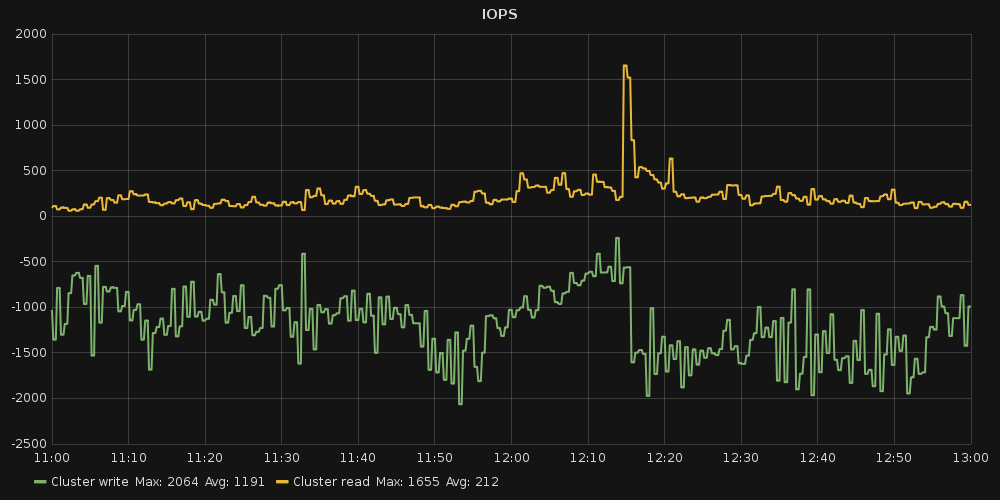
- File throughput.png throughput.png added
- File iops.png iops.png added
It was quite regular load. Graphs attached.
Updated by Zheng Yan over 7 years ago
could you please check if this issue exists in 4.5 kernel
Updated by Zheng Yan over 7 years ago
fs/ceph/inode.c:1272 is BUG_ON(d_inode(dn->d_parent) != dir); For cephfs case, I think only thing that can change d_parent is d_splice_alias(). Maybe d_splice_alias() modifies lookup request's r_dentry while waiting for reply
Jeff, could you take a look
Updated by Jeff Layton over 7 years ago
Sure...
First, does this kernel have any patches beyond what went into v4.8.4 ? There are some other BUG_ONs in that area so anything that adds or removes lines before that point in the file could affect which BUG_ON actually got tripped.
Also, what sort of workload is this -- are there multiple clients running and thrashing the filesystem concurrently? Single client?
Assuming that it is a stock v4.8.4 kernel:
struct inode *dir = req->r_locked_dir;
struct dentry *dn = req->r_dentry;
bool have_dir_cap, have_lease;
BUG_ON(!dn);
BUG_ON(!dir);
BUG_ON(d_inode(dn->d_parent) != dir);
So basically that just means that we got a different dentry/parent pair in the reply traces than we expected?
While that seems like it's non-ideal, BUG'ing here seems like the wrong way to handle it. Just because the vfs holds the i_rwsem for write, that doesn't prohibit other clients (for instance) from doing namespace changes, right? Also, we could end up with a broken or malicious MDS here, and I don't think we want to crash the client for that. We should probably change those BUG_ONs to handle this situation more gracefully. In NFS, we'd probably just invalidate the relevant cache objects here under the assumption that something changed on the server. I'm not sure what we'd need to do in Ceph.
Now all of that said, a big VFS layer change in v4.8 was the change of the i_mutex to i_rwsem to enable parallel lookups. splice_dentry does use d_splice_alias, and we don't necessarily hold a write lock on the i_rwsem in those codepaths anymore even though the comments say that we must hold i_mutex for that to be safe.
One theory: before v4.8 we'd hold the mutex over a lookup, so even if something changed on the server, only one task could call d_splice_alias at a time. Now though, we can potentially have multiple tasks calling it, processing traces that involve the same directory in parallel. So Zheng may be on to something here...one way to try and confirm that would be to have the lookup and readdir codepaths upgrade the i_rwsem to a rw lock.
It'll slow things down but may let us know whether we're on the right track here.
Updated by Jeff Layton over 7 years ago
- Assignee changed from Zheng Yan to Jeff Layton
That BUG_ON also looks suspicious. We may need to hold the rcu_read_lock there to ensure that dn->d_parent doesn't vanish while we're dereferencing it to get to the inode pointer. Furthermore, I'm not sure why we really care whether the namespace has changed concurrently here. Just because we're processing a reply that reflects an old directory layout, I don't think that's necessarily a bug. In fact, we should probably take a hard look at the whole r_locked_dir field handling in general. I'm not sure it's really doing the right thing now that the inode mutex has been converted to a rwsem.
Maybe we should just removing that BUG_ON now in light of the fact that parallel lookups are now possible? If not, then I think we might want to consider turning that BUG_ON into a set of log messages that give us some more info here. For instance, I'd be interested to see what sort of reply we're processing here (req->rq_op), as that should tell us what sort of lock we have on the i_rwsem. I'll see if I can cook up a patch.
Updated by Aurimas Lapiene over 7 years ago
There are 6 nodes that have mounted the same cephfs directory and 4 of them doing active R/W requests on same paths (load balanced), so your theory makes sense in this case.
Kernel is stock, no patches.
Just tried to upgrade kernel to v4.8.11 - nothing's changed, 3 out of 3 nodes had kernel panics in first hour (kernel: kernel BUG at fs/ceph/inode.c:1272!).
Currently downgrading kernel to v4.5.4.
Updated by Jeff Layton over 7 years ago
Ok, thanks. I see that you had written that in the original description too. If you have the time, then it might be good to test out the latest v4.9-rc kernel as well, but I suspect you'll hit the same problem there.
I got Al Viro to take a peek:
<viro> but there's a problem with ->d_revalidate() <viro> it had always been callable without parent locked <viro> before RCU work, even <viro> if we find it on plain dcache lookup, we call ->d_revalidate() <viro> ceph_d_revalidate() does <viro> req->r_locked_dir = dir; <viro> and it's not guaranteed to be locked at all <viro> never had been <viro> worse, the same method _can_ be called with parent locked by caller <viro> so it can't go and lock the sucker itself <viro> X-broken-by: commit 200fd27c8fa2ba8bb4529033967b69a7cbfa2c2e <viro> Author: Yan, Zheng <zyan@redhat.com> <viro> Date: Thu Mar 17 14:41:59 2016 +0800 <viro> ceph: use lookup request to revalidate dentry
We should take a hard look at that. That may or may not be the culprit here, but it's at least a problem if not the problem.
It may be sufficient to simply to set r_locked_dir to NULL in d_revalidate. I don't think we specifically care about the parent dentry for d_revalidate, do we?
I'll plan to test out a patch with that and see whether it breaks anything.
Updated by Jeff Layton over 7 years ago
From ceph_d_revalidate:
req = ceph_mdsc_create_request(mdsc, op, USE_ANY_MDS);
if (!IS_ERR(req)) {
req->r_dentry = dget(dentry);
req->r_num_caps = 2;
mask = CEPH_STAT_CAP_INODE | CEPH_CAP_AUTH_SHARED;
if (ceph_security_xattr_wanted(dir))
mask |= CEPH_CAP_XATTR_SHARED;
req->r_args.getattr.mask = mask;
req->r_locked_dir = dir;
err = ceph_mdsc_do_request(mdsc, NULL, req);
if (err == 0 || err == -ENOENT) {
if (dentry == req->r_dentry) {
valid = !d_unhashed(dentry);
} else {
d_invalidate(req->r_dentry);
err = -EAGAIN;
}
}
ceph_mdsc_put_request(req);
dout("d_revalidate %p lookup result=%d\n",
dentry, err);
}
The result handling after ceph_mdsc_do_request looks fishy. We do the same thing if we get err 0 as we do if we get err -ENOENT, regardless of whether the original dentry was negative or not?
OTOH, I'm still trying to understand the logic in ceph_fill_trace, so that may be correct depending on what sort of dcache shenanigans it does.
Updated by Zheng Yan over 7 years ago
Jeff Layton wrote:
From ceph_d_revalidate:
[...]
The result handling after ceph_mdsc_do_request looks fishy. We do the same thing if we get err 0 as we do if we get err -ENOENT, regardless of whether the original dentry was negative or not?
OTOH, I'm still trying to understand the logic in ceph_fill_trace, so that may be correct depending on what sort of dcache shenanigans it does.
The reason I wrote this code is that the dentry was spliced, no matter original dentry was negative or not, request->r_dentry should be valid.
Updated by Zheng Yan over 7 years ago
Jeff Layton wrote:
Ok, thanks. I see that you had written that in the original description too. If you have the time, then it might be good to test out the latest v4.9-rc kernel as well, but I suspect you'll hit the same problem there.
I got Al Viro to take a peek:
[...]
We should take a hard look at that. That may or may not be the culprit here, but it's at least a problem if not the problem.
It may be sufficient to simply to set r_locked_dir to NULL in d_revalidate. I don't think we specifically care about the parent dentry for d_revalidate, do we?
I'll plan to test out a patch with that and see whether it breaks anything.
I'm little worry about that d_revalidate does sleep lookup while parent is not locked. I think the dentry can get spliced while waiting for the reply. I think the better solution is make vfs tell us if parent is locked. handle the unlocked case as rcu case.
Updated by Aurimas Lapiene over 7 years ago
- File node1b_dmesg.log node1b_dmesg.log added
With kernel v4.5.4 there's no kernel panics, but CPUs started to soft lockup on one node every few hours (one node so far). Full dmesg log attached with soft lockup traces.
Now we disabled load balancing and left 1 node which actively reads/writes to same cephfs paths. We'll see if this would be more stable.
Updated by Jeff Layton over 7 years ago
Zheng Yan wrote:
I'm little worry about that d_revalidate does sleep lookup while parent is not locked. I think the dentry can get spliced while waiting for the reply. I think the better solution is make vfs tell us if parent is locked. handle the unlocked case as rcu case.
I don't think that will work. The VFS only locks the parent's rwsem if it's going to do a "real" lookup. lookup_fast won't take it (since it doesn't need it), and that's the main caller of d_revalidate. We could somehow communicate to the VFS that we require the parent to be locked (that was one of Al's suggestions), but I'm not sure I like that.
Alternately, do we really need to set r_locked_dir at all? What we really want to know here is whether the dentry still points to the same inode (or is still negative). We don't really need the parent's info to satisfy d_revalidate.
The main problem there (AFAICT) is that I don't see how to communicate those results back from ceph_fill_trace when r_locked_dir isn't set. We rely that function manipulating the dcache for that now, and that requires the parent's mutex.
Updated by Zheng Yan over 7 years ago
- File d_reval.patch d_reval.patch added
Aurimas, If you can compile kernel from source. The detach patch (for 4.8.x kernel) workaround this issue.
Updated by Jeff Layton over 7 years ago
I think the thing we want to do here is to not set r_locked_dir, and pass a reference to the inode that was the result of the lookup back to the d_revalidate function. Then we can do something like this in ceph_d_revalidate:
if (d_inode(dentry) == inode)
valid = 1;
...and that sidesteps the whole problem.
The question is how to pass an inode reference back to it there. There is a req->r_inode field that we could try to use for that purpose, but other codepaths use that field as an argument not as a result container.
What's the right way to do that? Alternately, we could pass back just enough info to ID the inode (e.g. i_ino and i_generation).
Updated by Zheng Yan over 7 years ago
Jeff Layton wrote:
Zheng Yan wrote:
I'm little worry about that d_revalidate does sleep lookup while parent is not locked. I think the dentry can get spliced while waiting for the reply. I think the better solution is make vfs tell us if parent is locked. handle the unlocked case as rcu case.
I don't think that will work. The VFS only locks the parent's rwsem if it's going to do a "real" lookup. lookup_fast won't take it (since it doesn't need it), and that's the main caller of d_revalidate. We could somehow communicate to the VFS that we require the parent to be locked (that was one of Al's suggestions), but I'm not sure I like that.
My point is let vfs tell us if the parent is locked. If it's not, we skip the step that sending a lookup request to mds. In most cases, our d_revalidate can still use lease or CEPH_CAP_FILE_SHARED to validate the dentry.
Sending a lookup request to mds is slow. I think it’s meaningless for these fast lookup cases. It's better to let VFS fallback to the slow lookup.
Alternately, do we really need to set r_locked_dir at all? What we really want to know here is whether the dentry still points to the same inode (or is still negative). We don't really need the parent's info to satisfy d_revalidate.
I think we can do this (maybe need minor modification to the code). But I don't understand how does this suppose to work in following situation.
- send lookup request to mds
- the dentry get spliced, it's parent changed
- get lookup reply.
let's assume the replied inode is equal to dentry inode. Is the dentry valid ?
The main problem there (AFAICT) is that I don't see how to communicate those results back from ceph_fill_trace when r_locked_dir isn't set. We rely that function manipulating the dcache for that now, and that requires the parent's mutex.
Updated by Zheng Yan over 7 years ago
Jeff Layton wrote:
I think the thing we want to do here is to not set r_locked_dir, and pass a reference to the inode that was the result of the lookup back to the d_revalidate function. Then we can do something like this in ceph_d_revalidate:
[...]
...and that sidesteps the whole problem.
The question is how to pass an inode reference back to it there. There is a req->r_inode field that we could try to use for that purpose, but other codepaths use that field as an argument not as a result container.
I think we can use req->r_target_inode
What's the right way to do that? Alternately, we could pass back just enough info to ID the inode (e.g. i_ino and i_generation).
Updated by Jeff Layton over 7 years ago
Zheng Yan wrote:
Jeff Layton wrote:
Zheng Yan wrote:
I'm little worry about that d_revalidate does sleep lookup while parent is not locked. I think the dentry can get spliced while waiting for the reply. I think the better solution is make vfs tell us if parent is locked. handle the unlocked case as rcu case.
I don't think that will work. The VFS only locks the parent's rwsem if it's going to do a "real" lookup. lookup_fast won't take it (since it doesn't need it), and that's the main caller of d_revalidate. We could somehow communicate to the VFS that we require the parent to be locked (that was one of Al's suggestions), but I'm not sure I like that.
My point is let vfs tell us if the parent is locked. If it's not, we skip the step that sending a lookup request to mds. In most cases, our d_revalidate can still use lease or CEPH_CAP_FILE_SHARED to validate the dentry.
Sending a lookup request to mds is slow. I think it’s meaningless for these fast lookup cases. It's better to let VFS fallback to the slow lookup.
Yes, though the whole reason for doing a lookup here (AIUI) is to avoid having the dentry be d_invalidated. Honestly, I hate the d_revalidate API. Maybe we should point out this difficulty in the email thread.
Alternately, do we really need to set r_locked_dir at all? What we really want to know here is whether the dentry still points to the same inode (or is still negative). We don't really need the parent's info to satisfy d_revalidate.
I think we can do this (maybe need minor modification to the code). But I don't understand how does this suppose to work in following situation.
- send lookup request to mds
- the dentry get spliced, it's parent changed
- get lookup reply.let's assume the replied inode is equal to dentry inode. Is the dentry valid ?
Yes -- That's the way it works with NFS, for instance. All the filesystem needs to answer is "Does this dentry still point at this inode?". Handling changes to the dcache hierarchy is the job of the vfs layer.
Hmm...maybe we should update vfs.txt to make that clear.
Updated by Zheng Yan over 7 years ago
got it. the whole point is avoid d_invalidated
Updated by Jeff Layton over 7 years ago
Jeff Layton wrote:
I think we can do this (maybe need minor modification to the code). But I don't understand how does this suppose to work in following situation.
- send lookup request to mds
- the dentry get spliced, it's parent changed
- get lookup reply.let's assume the replied inode is equal to dentry inode. Is the dentry valid ?
Yes -- That's the way it works with NFS, for instance. All the filesystem needs to answer is "Does this dentry still point at this inode?". Handling changes to the dcache hierarchy is the job of the vfs layer.
Hmm...maybe we should update vfs.txt to make that clear.
So that said...there is a difference between NFS and Ceph here, and that is that an NFS lookup involves a filehandle and a component name, whereas Ceph builds a full path and requests that. Thus, NFS more closely mirrors how the dcache actually works. With Ceph, you could get intermediate components renamed after you build a path but before you send it to the server, which could render the results of d_revalidate questionable.
I don't see a way to fix that given the current Ceph protocol though, given its reliance on (ick) pathnames. Note that CIFS has the same problem.
Updated by Jeff Layton over 7 years ago
- File 0001-ceph-don-t-set-r_locked_dir-in-ceph_d_revalidate.patch added
Ok, I think this patch will probably do the right thing. Only tested for compilation so far, but I'll see if I can give it a spin soon.
It turns out that we already get a pointer to r_target_inode, so we just need to compare that to d_inode(dentry) as long as we assume no duplicate entries in the inode cache.
Updated by Jeff Layton over 7 years ago
Did some basic testing (with a doctored kernel that always revalidates dentries) and this seems to do the right thing. That said, I am seeing some hangs in testing with the latest ceph/testing branch with synchronous calls seeming to get stuck waiting on replies. I don't think this patch is the cause but it would be good to rule that out.
Updated by Jeff Layton over 7 years ago
- File 0001-ceph-don-t-set-req-r_locked_dir-in-ceph_d_revalidate.patch 0001-ceph-don-t-set-req-r_locked_dir-in-ceph_d_revalidate.patch added
Actually, I think we want this patch. Now that we're not manipulating the dcache with this call, we must handle the different outcomes from the lookup differently.
I lightly tested this patch on top of ceph/testing running connectathon and it seemed to do OK. I'm not sure that that really exercises this codepath well though.
I also hacked ceph_d_revalidate to always do an on-the-wire revalidation, but then the test kept hanging on an rmdir (completely unrelated codepath). Possibly I broke something there, but it may be that the increased MDS lookup load is uncovering a different bug.
Note too that we need to remove the WARN_ON_ONCE in ceph_fill_trace, as this seems to trip it up. I don't think we need a WARN_ON just because MDS sent us an unsolicited is_dentry trace.
Updated by Jeff Layton over 7 years ago
- File deleted (
0001-ceph-don-t-set-r_locked_dir-in-ceph_d_revalidate.patch)
Updated by Zheng Yan over 7 years ago
Jeff Layton wrote:
Actually, I think we want this patch. Now that we're not manipulating the dcache with this call, we must handle the different outcomes from the lookup differently.
I lightly tested this patch on top of ceph/testing running connectathon and it seemed to do OK. I'm not sure that that really exercises this codepath well though.
I also hacked ceph_d_revalidate to always do an on-the-wire revalidation, but then the test kept hanging on an rmdir (completely unrelated codepath). Possibly I broke something there, but it may be that the increased MDS lookup load is uncovering a different bug.
Note too that we need to remove the WARN_ON_ONCE in ceph_fill_trace, as this seems to trip it up. I don't think we need a WARN_ON just because MDS sent us an unsolicited is_dentry trace.
If we only want inode, it's better to use getattr to validate dentry (getattr is basically the same as lookup, except mds does send dentry trace for getattr).
There are some places that access req->r_dentry->d_parent. Is it safe to do that when parent is not locked? maybe we need to use dget_parent in these places
Updated by Jeff Layton over 7 years ago
Zheng Yan wrote:
If we only want inode, it's better to use getattr to validate dentry (getattr is basically the same as lookup, except mds does send dentry trace for getattr).
Interesting, I had always figured that getattr would be done by inode number and not path. Note that we do need to verify that the dentry name points to the inode so the mds does need to do a name to inode lookup of some sort.
There are some places that access req->r_dentry->d_parent. Is it safe to do that when parent is not locked? maybe we need to use dget_parent in these places
Generally no, that's not safe. The only place that looks suspicious right offhand is in __choose_mds. dget_parent would probably work there, but we might also be able to rcu there instead since it doesn't look like any of the functions in the relevant code will block.
Updated by Zheng Yan over 7 years ago
Jeff Layton wrote:
Zheng Yan wrote:
If we only want inode, it's better to use getattr to validate dentry (getattr is basically the same as lookup, except mds does send dentry trace for getattr).
Interesting, I had always figured that getattr would be done by inode number and not path. Note that we do need to verify that the dentry name points to the inode so the mds does need to do a name to inode lookup of some sort.
sorry, I mean "getattr is basically the same as lookup, except mds does NOT send dentry trace for getattr". getattr can do name lookup, it's ideal for this case.
Updated by Jeff Layton over 7 years ago
- Status changed from New to In Progress
Patch posted to mailing list and merged into ceph-client/testing branch.
Updated by Aurimas Lapiene over 7 years ago
Tested this patch (https://github.com/ceph/ceph-client/commit/06ae6a76e4570cba948084f6a1c0d206485d1706) on two servers with kernel v4.8.12 yesterday for 6 hours straight and there were no kernel panics. Then another problem came up - after some time all IO started to get very slow (we had this problem earlier, but it wouldn't have time to fully show up before kernel panic). mdsc showed a lot of (thousands) requests processing and steadily growing (osdc showed just a few requests and they were processed fast). Requests were not hanged, they were being processed, but very slowly. Because of that we could not continue and returned to kernel v4.5, which handles way more IO in our case.
Updated by Jeff Layton over 7 years ago
Thanks for testing it. The slowdown sounds like a different problem entirely and I'd suggest opening a separate bug for that.
The patch for this bug has been merged into the testing branch, and I think we want it to go into stable kernels as well. I'll leave this open for now until it has been merged into master.
Updated by Ilya Dryomov over 7 years ago
- Status changed from In Progress to Pending Backport
Updated by Ilya Dryomov over 7 years ago
- Status changed from Pending Backport to Resolved
in 4.8.15.