Bug #63389
openFailed to encode map X with expected CRC
0%
Description
During upgrade of ceph from Quincy to Reef we encountered a problem as we upgraded each OSD. Every time an OSD was restarted to upgrade the Reef the MON's would get spammed with
failed to encode map X with expected crc
Network load on the MON would skyrocket. The problem was identical to what was described by Kefu here in 2016:
https://lore.kernel.org/all/CAJE9aONFauhy7v6n9bT11Sga+e0Qgi8hWu=gr-zoxuAq5Yv+cA@mail.gmail.com/T/
We did not follow the recommendation in that post of downgrading the MONs and upgrading the OSDs first and then upgrading the MONs again. Instead we powered through the upgrade by just taking a one day downtime and upgrading all remaining OSDs. Once all OSDs were upgraded the errors went away and cluster was back to normal operation.
Files
{kind=link}
Updated by Navid Golpa 6 months ago
- File mon.csv mon.csv added
- File ceph-w.txt.gz ceph-w.txt.gz added
- File network.png network.png added
Unfortunately we have very limited logs as we were more concerned with making sure the system was stable again than with debugging.
I've attached what logs we do have:
- Capture of ceph -w command while we restarted a single OSD
- Log of one of the MONs (aps-controller-004) for the period we restarted the OSD (gzipped due to size)
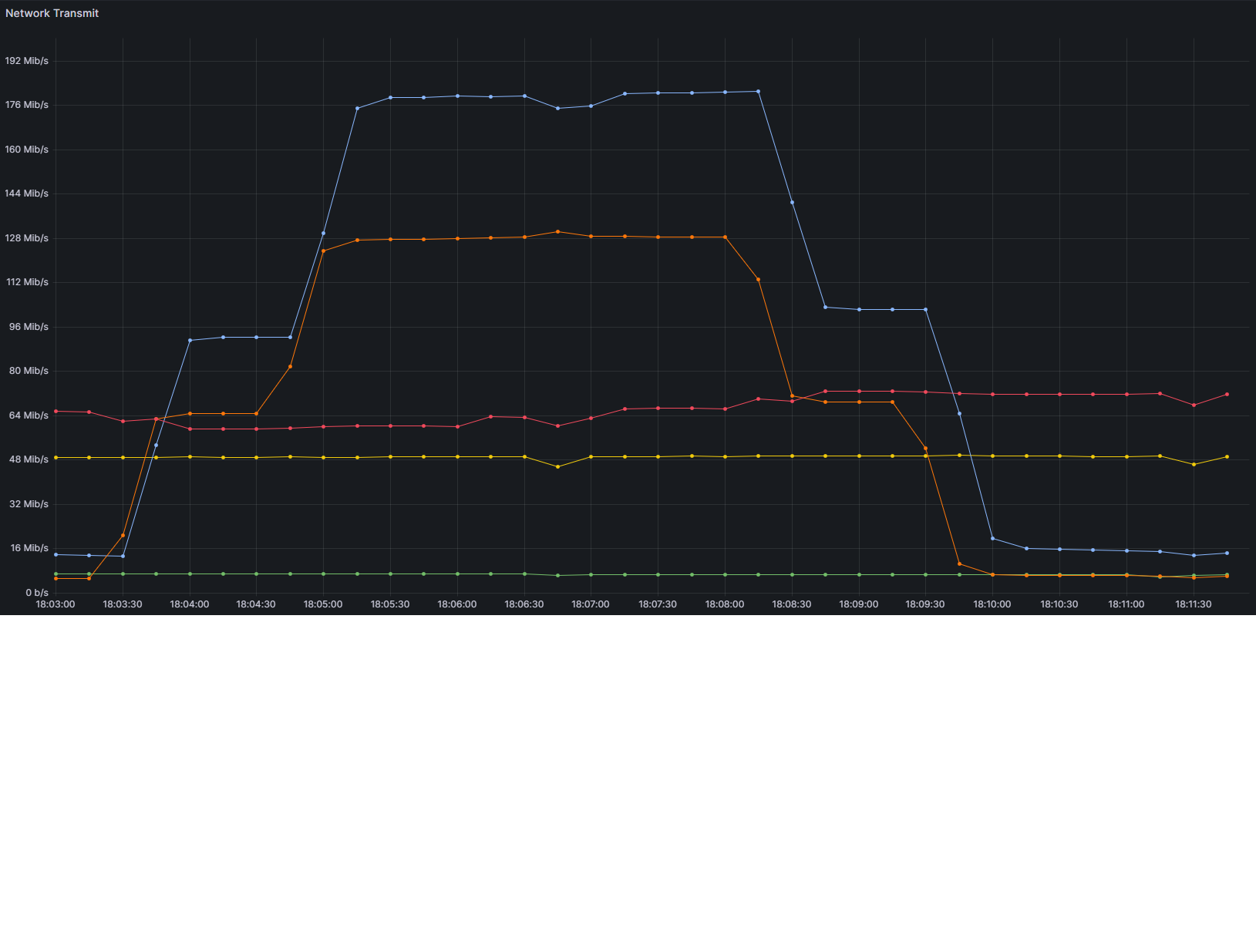
- Graph of the network transmit load of the MONs for that time period (aps-controller-003 is blue, aps-controller-004 is orange and aps-controller-005 is red)
Updated by Dan van der Ster 6 months ago
@Junior the quincy-x test suite has quite a few "failed to encode map" x "with expected crc"
Updated by Dan van der Ster 6 months ago
@Junior I suspect the warning isn't noticed because of this:
2023-10-28T15:59:53.486 DEBUG:teuthology.orchestra.run.smithi007:> sudo egrep '\[ERR\]|\[WRN\]|\[SEC\]' /var/log/ceph/10bc8c0a-75a0-11ee-8db9-212e2dc638e7/ceph.log | egrep -v '\(MDS_ALL_DOWN\)' | egrep -v '\(MDS_UP_LESS_THAN_MAX\)' | head -n 1 2023-10-28T15:59:53.517 INFO:teuthology.orchestra.run.smithi007.stderr:grep: /var/log/ceph/10bc8c0a-75a0-11ee-8db9-212e2dc638e7/ceph.log: No such file or directory
Updated by Dan van der Ster 6 months ago
- Related to Bug #63425: tasks.cephadm: ceph.log No such file or directory added
Updated by Radoslaw Zarzynski 6 months ago
- Priority changed from Normal to High
I'm changing the priority to High as it's important issue, thought we haven't observed any outages, so blocking releases etc. seems too much. This also gives us more time to work on the problem.
Let's start from ensuring this is another instance of https://tracker.ceph.com/issues/17386 -- the should be encoding change between the versions present in cluster during the upgrade.
Updated by Radoslaw Zarzynski 6 months ago
- Related to Bug #17386: Upgrading 0.94.6 -> 0.94.9 saturating mon node networking added
Updated by Radoslaw Zarzynski 5 months ago
scrub note: Junior is going to setup a meeting to discuss the issue.
Updated by Kamoltat (Junior) Sirivadhna 5 months ago
1. Currently what we found is that the issue is always reproducible in runs that contain “upgrade/parallel” + “upgrade-sequence workload/{ec-rados-default rados_api rados_loadgenbig rbd_import_export test_rbd_api test_rbd_python}”
2. CRC mismatch goes away after the monitors finish the upgrade and restart itself.
3. the mismatch has a stdout that indicates a diff in the blocklist attribute of the OSDMap between the map from the primary monitor (Canonicle) and the one that the peer applies the incremental map.
4. What's weird is that after there is a mismatch, the Monitor switched to using the Canonicle map and with the next OSDMap update, we now get matching blocklist content, however, CRC is still mismatch.
checkout https://docs.google.com/document/d/19cHkQHtROH_Anba2kv2N36Vx_7L3-n9BxKJAl5Q9_Kw/edit
I'm currently adding more loggings around the CRC code to understand how it gets changed through encoding. Need to find a way to use a custom image when running the upgrade test.
Updated by Kamoltat (Junior) Sirivadhna 5 months ago
- Pull request ID set to 54890
After adding more loggings, building a custom image, and re-running the upgrade suite to reproduce the issue, we found that the CRC mismatch output is expected to happen. This is because the CRC value is determined by the length of the OSDMap buffer list which means that if the monitors have different OSDMap encoding versions, the buffer list will have different lengths which causes the CRC values to be different.
The CRC mismatch in this tracker happens when the leader monitor is upgraded and running a different version to its peer monitors. However, when all the peer monitors have successfully upgraded themselves, the CRC mismatch error output goes away.
The reason why we don't see this issue in an upgrade from Nautilus to Quincy is that both Ceph versions have the same OSDMap encoding version of 9. However, we can see this issue in an upgrade from Quincy to Reef/Main because Reef/Main has an OSDMap encoding version of 10.
The proposed solution is to have better logging for when this problem occurs again by stating that this could be a mismatch in MON versions and outputting the different crc values.
Here is the PR link: https://github.com/ceph/ceph/pull/54890
Updated by Navid Golpa 5 months ago
If I understand it right, the conclusion is that this is only an issue if not all MONs have been upgraded to Reef?
I don't believe that scenario covers the case we encountered. We upgraded and restarted the MONs first before attempting upgrades of the OSDs. All MONs were using Reef when we started upgrade of OSDs.
We followed instructions outlined here and verified by running
ceph mon dump | grep min_mon_release
and verifying it returned Reef
Updated by Kamoltat (Junior) Sirivadhna 5 months ago
- Status changed from Need More Info to Fix Under Review
Updated by Kamoltat (Junior) Sirivadhna 5 months ago
As for the network load that sky-rocketed it could be because the Monitor is performing an upgrade and probably will go back to normal once the upgrade is finished
Updated by Kamoltat (Junior) Sirivadhna 4 months ago
Hi Navid,
Sorry, I might not have been clear with my explanation. Basically by investigating the logs of the runs I have reproduced (by replicating the same scenario you encountered, e.g., upgrading from Quincy to Reef while running some workloads, the upgrade also starts with the Monitors first before moving on to OSDs.) I have discovered that the error message `Failed to encode map X with expected crc` appears during a short window where the leader Monitor gets upgraded first to version n+1, while the peon Monitors are running version n which is caused due by Quincy having an OSDMap encoding version of 9 and Reef having an OSDMap encoding version of 10. This is because the CRC value depends on the bufferlist size, since Reef has more stuff to encode in the bufferlist, the CRC value will be different from that of Quincy which has less stuff to encode, even though the OSDMap has the same content.
Now, after going through the code, I have concluded that we already have a mechanism that detects this CRC mismatch and rolls back to using the OSDMap from the leader monitor. We can see that this error persists until all the Monitors are successfully upgraded to Reef.
I have created a PR that will give a more informative output for the user to understand the nature of the CRC mismatch error. Basically, it is expected for us to see this CRC mismatch output.
Now you might wonder why when you upgrade from Nautilus to Quincy you don't see such an error. Well ... it's because the OSDMap encoding version between Nautilus and Quincy is the same at 9 (basically no change to the items we encode).
Updated by Dan van der Ster 4 months ago
Hi,
I appreciate the extra debugging printouts, but I don't agree that this is a fix.
On large clusters this type of issue can saturate the network of the mons and degrade the availability of a cluster.
In your assessment of the issue did you find the reason that the encoding changed? Can we fix the reef mon to be backward compatible with previous OSDs until the upgrade is completed?
Thanks, Dan
Updated by Kamoltat (Junior) Sirivadhna 4 months ago
Hi Dan,
I understand your concern regarding network saturation, however, during an upgrade, it should be expected that there will be a short period of unavailability in the cluster. In my assessment, I have already pointed out changes in the OSDMap data types between Reef and Quincy (more stuff to encode in Reef so there is a warning when calculating the expected CRC value). I think the mechanism in place is already doing its job in making sure that if there are mix versions between the Monitors, we will always use the Primary Monitor's OSDMap to be committed in Paxos, this goes the same with OSDs where it will re-request the full map from the Primary Monitor when it discovers the crc mismatch.
Updated by Navid Golpa 4 months ago
I guess it depends on what is defined as short periods of unavailability.
Our case we had a 4000 OSD cluster. Knowing what we know now I suspect we would have had to schedule an entire work week outage to upgrade the cluster. Each node of 30 OSDs took 30 minutes to 1 hour to upgrade in parallel to reef before all the OSDs appeared online and the cluster stabilized and we could move on to the next set of OSDs.
Updated by Joshua Baergen 4 months ago
during an upgrade, it should be expected that there will be a short period of unavailability in the cluster
I disagree. An upgrade should be no more disruptive than an OSD restart. That's the goal of any modern HA service.
I have already pointed out changes in the OSDMap data types between Reef and Quincy
But shouldn't the new encoding not be used until require-osd-release is set to Reef+?
Updated by Joshua Baergen 3 months ago
https://lists.ceph.io/hyperkitty/list/ceph-users@ceph.io/thread/XHNC3YOBSOWYH5VZ7JI5RNI5Q2TJ7H3X/ has OSDs reporting this message during a 17.2.6 -> 18.2.1 upgrade and (perhaps, it's a bit hard to tell) I/O performance issues.
Updated by Radoslaw Zarzynski 3 months ago
- Assignee changed from Kamoltat (Junior) Sirivadhna to Radoslaw Zarzynski
Updated by Radoslaw Zarzynski 3 months ago
At the moment yet a hypothesis requiring a trial: the unconditional append of new_pg_upmap_primary is fine from the dencoding framework's point of view BUT messes up the bl bufferlist size which in turn triggers the CRC check.
void OSDMap::Incremental::encode(ceph::buffer::list& bl, uint64_t features) const
{
// ...
{
uint8_t v = 9;
if (!HAVE_FEATURE(features, SERVER_LUMINOUS)) {
v = 3;
} else if (!HAVE_FEATURE(features, SERVER_MIMIC)) {
v = 5;
} else if (!HAVE_FEATURE(features, SERVER_NAUTILUS)) {
v = 6;
} /* else if (!HAVE_FEATURE(features, SERVER_REEF)) {
v = 8;
} */
ENCODE_START(v, 1, bl); // client-usable data
// ...
if (v >= 9) {
encode(new_pg_upmap_primary, bl);
encode(old_pg_upmap_primary, bl);
}
ENCODE_FINISH(bl); // client-usable data
// ...
}
// fill in crc
ceph::buffer::list front;
front.substr_of(bl, start_offset, crc_offset - start_offset);
inc_crc = front.crc32c(-1);
ceph::buffer::list tail;
tail.substr_of(bl, tail_offset, bl.length() - tail_offset);
inc_crc = tail.crc32c(inc_crc);
ceph_le32 crc_le;
crc_le = inc_crc;
crc_filler->copy_in(4u, (char*)&crc_le);
have_crc = true;
OSDMap::Incremental inc;
// ...
auto p = bl.cbegin();
inc.decode(p);
// ...
if (o->apply_incremental(inc) < 0) {
// ...
if ((inc.have_crc && o->get_crc() != inc.full_crc) || injected_failure) {
Updated by Matt Benjamin 3 months ago
it seems like this is a bit of an unwanted side effect of converging crc into buffer::list; I wonder if we could reduce general coupling by splitting that out, somehow...
Updated by Radoslaw Zarzynski 3 months ago
Refining the hypothesis after tracking how crc, full_crc and inc_crc are managed.
OSDMap::Incremental inc;
// ...
auto p = bl.cbegin();
inc.decode(p);
if (o->apply_incremental(inc) < 0) {
// ...
bufferlist fbl;
o->encode(fbl, inc.encode_features | CEPH_FEATURE_RESERVED);
// ...
if ((inc.have_crc && o->get_crc() != inc.full_crc) || injected_failure) {
dout(2) << "got incremental " << e
<< " but failed to encode full with correct crc; requesting"
<< dendl;
clog->warn() << "failed to encode map e" << e << " with expected crc";
dout(20) << "my encoded map was:\n";
fbl.hexdump(*_dout);
1. The o->encode(fbl, inc.encode_features | CEPH_FEATURE_RESERVED) is crucial. It encodes the freshly incremented OSDMap o with a local encoder but using the peer's features bits. The produced fbl doesn't really matter; the encode is called for its side-effect: setting OSDMap::crc to a CRC produced by local OSDMap::encode() variant.
2. The locally produced o,crc is compared with the inc.full_crc that came as the incremental OSDMap from a remote.
3. Remote provides it the following way:
void OSDMap::Incremental::encode(ceph::buffer::list& bl, uint64_t features) const
{
// ...
encode(full_crc, bl);
ENCODE_FINISH(bl); // meta-encoding wrapper
// ...
}
void OSDMonitor::encode_pending(MonitorDBStore::TransactionRef t)
{
// ...
// features for osdmap and its incremental
uint64_t features;
// encode full map and determine its crc
OSDMap tmp;
{
tmp.deepish_copy_from(osdmap);
tmp.apply_incremental(pending_inc);
// determine appropriate features
features = tmp.get_encoding_features();
dout(10) << __func__ << " encoding full map with "
<< tmp.require_osd_release
<< " features " << features << dendl;
// the features should be a subset of the mon quorum's features!
ceph_assert((features & ~mon.get_quorum_con_features()) == 0);
bufferlist fullbl;
encode(tmp, fullbl, features | CEPH_FEATURE_RESERVED);
pending_inc.full_crc = tmp.get_crc();
What's crucial is that a remote determines the CRC basing on its own variant / flavour of OSDMap::encode():
encode(tmp, fullbl, features | CEPH_FEATURE_RESERVED);
pending_inc.full_crc = tmp.get_crc();
Not only the encoder-decoder pair must be compatible but it also must provide exact equality of byte streams between local & remote. The difference point is the autodiscard-the-end of DECODE_FINISH:
#define DECODE_START(v, bl) \
decode(struct_len, bl); \
if (struct_len > bl.get_remaining()) \
throw ::ceph::buffer::malformed_input(DECODE_ERR_PAST(__PRETTY_FUNCTION__)); \
unsigned struct_end = bl.get_off() + struct_len; \
// ...
#define DECODE_FINISH(bl) \
} while (false); \
if (struct_end) { \
// ...
if (bl.get_off() < struct_end) \
bl += struct_end - bl.get_off();
4. OSDMap::encode() has the same flaw as the previously mentioned OSDMap::Incremental::encode():
void OSDMap::encode(ceph::buffer::list& bl, uint64_t features) const
{
// ...
// meta-encoding: how we include client-used and osd-specific data
ENCODE_START(8, 7, bl);
{
// NOTE: any new encoding dependencies must be reflected by
// SIGNIFICANT_FEATURES
uint8_t v = 10;
if (!HAVE_FEATURE(features, SERVER_LUMINOUS)) {
v = 3;
} else if (!HAVE_FEATURE(features, SERVER_MIMIC)) {
v = 6;
} else if (!HAVE_FEATURE(features, SERVER_NAUTILUS)) {
v = 7;
} /* else if (!HAVE_FEATURE(features, SERVER_REEF)) {
v = 9;
} */
// ...
if (v >= 9) {
encode(last_up_change, bl);
encode(last_in_change, bl);
}
if (v >= 10) {
encode(pg_upmap_primaries, bl);
} else {
ceph_assert(pg_upmap_primaries.empty());
}
ENCODE_FINISH(bl); // client-usable data
}
Updated by Radoslaw Zarzynski 3 months ago
In very short: the quincy encoder doesn't produce the discardable junks from marshaling the empty pg_upmap_primaries but the Reef's one does. Although there is NO difference after demarshalling (empty pg_upmap_primaries at both sides), there is a difference of byte stream the CRCs are calculated from.
I wonder whether the following patch would be enough. At the moment I'm worried about SIGNIFICANT_FEATURES.
diff --git a/src/osd/OSDMap.cc b/src/osd/OSDMap.cc
index 8f60b2f3c83..3f6bc052ef4 100644
--- a/src/osd/OSDMap.cc
+++ b/src/osd/OSDMap.cc
@@ -588,9 +588,9 @@ void OSDMap::Incremental::encode(ceph::buffer::list& bl, uint64_t features) cons
v = 5;
} else if (!HAVE_FEATURE(features, SERVER_NAUTILUS)) {
v = 6;
- } /* else if (!HAVE_FEATURE(features, SERVER_REEF)) {
+ } else if (!HAVE_FEATURE(features, SERVER_REEF)) {
v = 8;
- } */
+ }
ENCODE_START(v, 1, bl); // client-usable data
encode(fsid, bl);
encode(epoch, bl);
@@ -3011,6 +3011,9 @@ bool OSDMap::primary_changed_broken(
uint64_t OSDMap::get_encoding_features() const
{
uint64_t f = SIGNIFICANT_FEATURES;
+ if (require_osd_release < ceph_release_t::reef) {
+ f &= ~CEPH_FEATURE_SERVER_REEF;
+ }
if (require_osd_release < ceph_release_t::octopus) {
f &= ~CEPH_FEATURE_SERVER_OCTOPUS;
}
@@ -3190,9 +3193,9 @@ void OSDMap::encode(ceph::buffer::list& bl, uint64_t features) const
v = 6;
} else if (!HAVE_FEATURE(features, SERVER_NAUTILUS)) {
v = 7;
- } /* else if (!HAVE_FEATURE(features, SERVER_REEF)) {
+ } else if (!HAVE_FEATURE(features, SERVER_REEF)) {
v = 9;
- } */
+ }
ENCODE_START(v, 1, bl); // client-usable data
// base
encode(fsid, bl);
diff --git a/src/osd/OSDMap.h b/src/osd/OSDMap.h
index 963039d0213..065ae60b099 100644
--- a/src/osd/OSDMap.h
+++ b/src/osd/OSDMap.h
@@ -564,7 +564,8 @@ private:
CEPH_FEATUREMASK_SERVER_LUMINOUS |
CEPH_FEATUREMASK_SERVER_MIMIC |
CEPH_FEATUREMASK_SERVER_NAUTILUS |
- CEPH_FEATUREMASK_SERVER_OCTOPUS;
+ CEPH_FEATUREMASK_SERVER_OCTOPUS |
+ CEPH_FEATUREMASK_SERVER_REEF;
struct addrs_s {
mempool::osdmap::vector<std::shared_ptr<entity_addrvec_t> > client_addrs;
The line-of-thought about dencoders + the crc check is:
- Fixed encoders in a Reef's minor would produce the same byte stream (without @pg_upmap_primaries) when speaking to <= Quincy peers.
- For clusters already upgraded to Reef
!HAVE_FEATURE(features, SERVER_REEF)would evaluate tofalse– the logical equivalent of theifcommented out@, so no difference. - For upgrades from a flawed Reef's minor to T+ (hypothetical
v == 11ofOSDMap::encode()) – fine, I guess.
The SIGNIFICANT_FEATURES part needs further investigation.
Updated by Samuel Just 3 months ago
The above looks right to me -- the idea (iirc) is that everyone encodes OSDMaps with the original encoding version, not their own.
Updated by Kamoltat (Junior) Sirivadhna 3 months ago
per https://github.com/ceph/ceph/pull/55401#issuecomment-1932723081
I wanna point out that the issue happens in both OSDs and Monitors
because they both update the OSDMap by encoding
and adding the increments to their existing map.
OSDMonitor paxos service is pulling osdmap from mon_store and uses the encoding features:
Which then gives the error:
https://pulpito.ceph.com/ksirivad-2024-01-31_21:14:43-upgrade:quincy-x-main-distro-default-smithi/7541233/
```
2024-01-31T21:48:31.745+0000 7f9405310700 -1 mon.c@2(peon).osd e260 update_from_paxos full map CRC mismatch, resetting to canonical
…
2024-01-31T21:48:31.745+0000 7f9405310700 20 mon.c@2(peon).osd e260 update_from_paxos my (bad) full osdmap:
…
```
Updated by Radoslaw Zarzynski 3 months ago
- Status changed from Fix Under Review to Pending Backport
- Backport set to reef
Only reef needs a backport.
Updated by Backport Bot 3 months ago
- Copied to Backport #64406: reef: Failed to encode map X with expected CRC added
Updated by Dan van der Ster 3 months ago
@Radoslaw Smigielski I'm confused, are we going with PR 54890 as a fix for this, or your proposed actual fix?
Updated by Patrick Donnelly 2 months ago
/teuthology/pdonnell-2024-02-16_01:25:08-fs:upgrade:mds_upgrade_sequence-wip-batrick-testing-20240215.160715-distro-default-smithi/7561870/teuthology.log
2024-02-16T02:08:41.210 INFO:journalctl@ceph.mon.smithi164.smithi164.stdout:Feb 16 02:08:41 smithi164 ceph-mon[93941]: failed to encode map e50 with expected crc
This is from a monitor running `main` shortly after an OSD was restarted by cephadm during an upgrade.
So, it seems like this fix is incomplete? Or is this expected (yuck)?
Updated by Radoslaw Zarzynski 2 months ago
- Pull request ID changed from 54890 to 55401
The actual fix (not just the log message change) is: https://github.com/ceph/ceph/pull/55401.
It got approved 2 hours ago and will be merged soon.
Updating the link in the tracker.
So, it seems like this fix is incomplete? Or is this expected (yuck)?
I bet the commit wasn't present in the testing branch.
Updated by Radoslaw Zarzynski about 2 months ago
The problem came because of a commit that introduced the commented-out check for SERVER_REEF in OSDMap::encode().
Quincy is free of the problem: https://github.com/ceph/ceph/blob/quincy/src/osd/OSDMap.cc#L3087-L3089.
Updated by Laura Flores about 1 month ago
- Related to Bug #65186: OSDs unreachable in upgrade test added
Updated by Laura Flores about 1 month ago
- Related to Bug #65185: OSD_SCRUB_ERROR, inconsistent pg in upgrade tests added
Updated by Radoslaw Zarzynski about 1 month ago
- Tags deleted (
backport_processed) - Backport changed from reef to reef,squid
Updated by Backport Bot about 1 month ago
- Copied to Backport #65198: squid: Failed to encode map X with expected CRC added
Updated by Laura Flores 19 days ago
- Related to deleted (Bug #65185: OSD_SCRUB_ERROR, inconsistent pg in upgrade tests)
Updated by Laura Flores 19 days ago
- Related to deleted (Bug #65186: OSDs unreachable in upgrade test)