Bug #62836
openCEPH zero iops after upgrade to Reef and manual read balancer
0%
Description
We've recently performed an upgrade on our Cephadm cluster, transitioning from Ceph Quiency to Reef. However, following the manual implementation of a read balancer in the Reef cluster, we've experienced a significant slowdown in client I/O operations within the Ceph cluster, affecting both client bandwidth and overall cluster performance.
This slowdown has resulted in unresponsiveness across all virtual machines within the cluster, despite the fact that the cluster exclusively utilizes SSD storage."
Kindly guide us to move forward.
Files
{kind=link}
Updated by Stefan Kooman 8 months ago
@Mosharaf Hossain:
Do you also have a performance overview when you were running Quincy? Quincy would then be the performance baseline.
The osdmap is something different than "ceph osd tree" overview. It's were ceph compiles all OSD related information about the cluster. It can be obtained in the following way:
ceph osd getmap -o om
You can view the contents with: osdmaptool --dump plain om
You can attach the file to this ticket.
Updated by Stefan Kooman 8 months ago
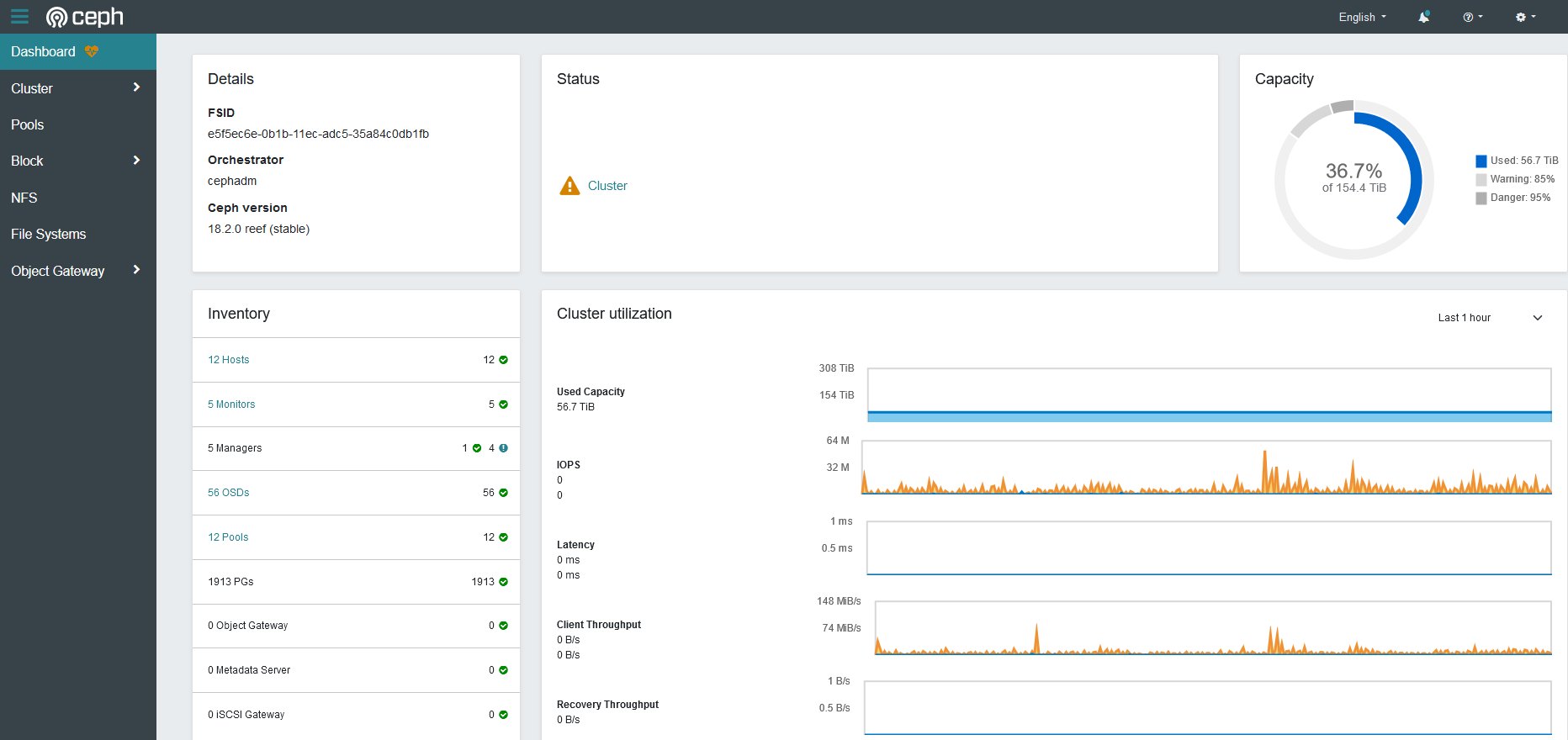
The dashboard values show all "0", but the graph indicates it's still doing IO, as does "ceph -s". It might (also) be a dashboard (related) issue.
Updated by Stefan Kooman 8 months ago
@Mosharaf Hossain:
What kind of client do you use to access the VM storage (i.e. kernel client rbd, krbd, or librbd through qemu/libvirt or some other means (rbd-nbd)?
What Ceph version do the clients (hypervisors) run?
Updated by Laura Flores 8 months ago
Hi Mosharaf, as Stefan wrote above, you can get your osdmap file by running the following command, where "osdmap" is the osdmap file. If you could attach this map to the tracker, that would be great:
ceph osd getmap -o osdmap
Also, you may want to try running the following command on each pg to see if performance improves:
ceph osd rm-pg-upmap-primary <pgid>
You can run the following command to see which pgs to execute this command on:
ceph osd dump
Updated by Laura Flores 8 months ago
After running `ceph osd dump`, you should see entries like this at the end of the output, which indicate each pg you should run the `ceph osd rm-pg-upmap-primary` command on:
pg_upmap_primary 4.0 2
Let us know if your IO improves.
Updated by Mosharaf Hossain 8 months ago
- File osd_map_ceph2.txt osd_map_ceph2.txt added
Stefan Kooman wrote:
@Mosharaf Hossain:
Do you also have a performance overview when you were running Quincy? Quincy would then be the performance baseline.
The osdmap is something different than "ceph osd tree" overview. It's were ceph compiles all OSD related information about the cluster. It can be obtained in the following way:
ceph osd getmap -o om
You can view the contents with: osdmaptool --dump plain om
You can attach the file to this ticket.
Hello @Stefan Kleijkers
I have attached the output as you have asked for. Please verify it.
Updated by Laura Flores 8 months ago
Mosharaf Hossain wrote:
Stefan Kooman wrote:
@Mosharaf Hossain:
Do you also have a performance overview when you were running Quincy? Quincy would then be the performance baseline.
The osdmap is something different than "ceph osd tree" overview. It's were ceph compiles all OSD related information about the cluster. It can be obtained in the following way:
ceph osd getmap -o om
You can view the contents with: osdmaptool --dump plain om
You can attach the file to this ticket.
Hello @Stefan Kleijkers
I have attached the output as you have asked for. Please verify it.
The output is fine; can you also please attach the osdmap file you used to generate the output?
Thanks,
Laura
Edit: The difference is that we can actually run the offline read balancer command on our end with that file, and see more debug output.
Updated by Laura Flores 8 months ago
Hi Mosharaf,
Regarding the traceback you got when trying to apply the rm-pg-upmap-primary command:
root@ceph-node1:/# ceph osd rm-pg-upmap-primary
Traceback (most recent call last): File "/usr/bin/ceph", line 1327, in <module> retval = main() File "/usr/bin/ceph", line 1036, in main retargs = run_in_thread(cluster_handle.conf_parse_argv, childargs) File "/usr/lib/python3.6/site-packages/ceph_argparse.py", line 1538, in run_in_thread raise t.exception File "/usr/lib/python3.6/site-packages/ceph_argparse.py", line 1504, in run self.retval = self.func(*self.args, **self.kwargs) File "rados.pyx", line 551, in rados.Rados.conf_parse_argv File "rados.pyx", line 314, in rados.cstr_list File "rados.pyx", line 308, in rados.cstr UnicodeEncodeError: 'utf-8' codec can't encode characters in position 3-4: surrogates
Can you paste the output of `which ceph` and `ceph versions` so we can check your python compatibility with the current running Ceph?
Updated by Laura Flores 8 months ago
Hey Mosharaf, any updates on the state of your cluster?
We would still need a copy of your actual osdmap file (achieved with `ceph osd getmap -o om`) to look further.
Also, we would like to understand if this is a versioning problem. What version of Ceph did you upgrade to Reef from?
Updated by Mosharaf Hossain 7 months ago
Laura Flores wrote:
Hey Mosharaf, any updates on the state of your cluster?
We would still need a copy of your actual osdmap file (achieved with `ceph osd getmap -o om`) to look further.
Also, we would like to understand if this is a versioning problem. What version of Ceph did you upgrade to Reef from?
Greetings Laura
I executed the command today, and it effectively resolved the issue. Within moments, my pools became active, and read/write IOPS started to rise.
Furthermore, the Hypervisor and VMs can now communicate seamlessly with the CEPH Cluster.
Command run:
ceph osd rm-pg-upmap-primary <PG_ID>
To summarize our findings:
Enabling the Ceph read balancer resulted in libvirtd from the hypervisor being unable to communicate with the CEPH cluster.
During the case, using RBD command images on the pool was readable
I'd like to express my gratitude to everyone involved, especially the forum contributors.
Updated by Radoslaw Zarzynski 7 months ago
Hello Mosharaf! Thanks for the update. It looks to the rm-pg-upmap-primary has workarounded the problem.
```
ceph osd rm-pg-upmap-primary <PG_ID>
```
However, what is still interesting is how balancer induced the IO stall. Would you be able to reproduce it again and collect ceph -s (hypothesis: OSDMap propagation issue -> laggy PGs).
Also, the binary of OSDMap (requested in #8) would be still very useful.
Updated by Laura Flores 7 months ago
Radoslaw Zarzynski wrote:
Hello Mosharaf! Thanks for the update. It looks to the
rm-pg-upmap-primaryhas workarounded the problem.```
ceph osd rm-pg-upmap-primary <PG_ID>
```However, what is still interesting is how balancer induced the IO stall. Would you be able to reproduce it again and collect
ceph -s(hypothesis: OSDMap propagation issue -> laggy PGs).Also, the binary of OSDMap (requested in #8) would be still very useful.
Yes, we would still like a copy of your osdmap, as well as the Ceph version before and after your upgrade.