Bug #56733
openSince Pacific upgrade, sporadic latencies plateau on random OSD/disks
0%
Description
Hello,
Since our upgrade to Pacific, we suffer from sporadic latencies on disks, not always the same.
The cluster is backing an OpenStack Cloud, and VM workloads are very impacted during these latency episodes.
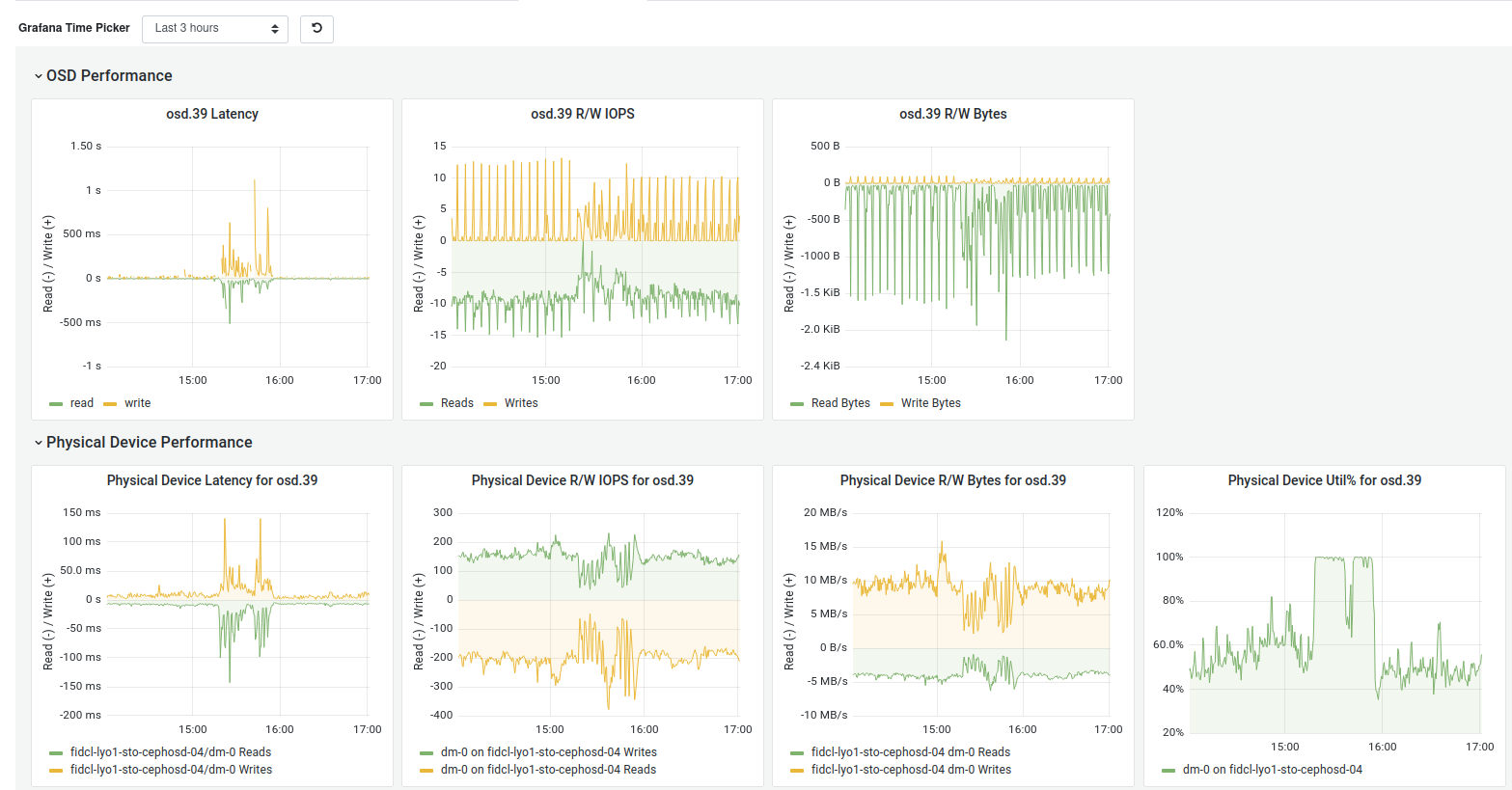
As we have SSD for rocksdb+wal, I found #56488, and increasing bluestore_prefer_deferred_size_hdd like mentioned have helped a bit, but we continue to see some high latency periods (30min to 1h), around 900ms (HDD). At 1ms, everything halts, and we have slow ops.
It seems, but I don't have enought occurence to be sure, that setting noscrub+nodeep-scrub during the event, stop it.
What's also unexpeted, is that the latency is on reads, impacting writes, not the reverse. During the latency plateau, there is not so much IOPS (~10) or Throughput (20MB/s) on the impacted drive.
The drive is OK in its SMART infos.
I've tried to remove the first drive/OSD I found having that problem, several times. But the problem happened on other OSD/drives.
Files
{kind=link}