Bug #52523
closed
Latency spikes causing timeouts after upgrade to pacific (16.2.5)
Added by Roland Sommer over 2 years ago.
Updated over 2 years ago.
Description
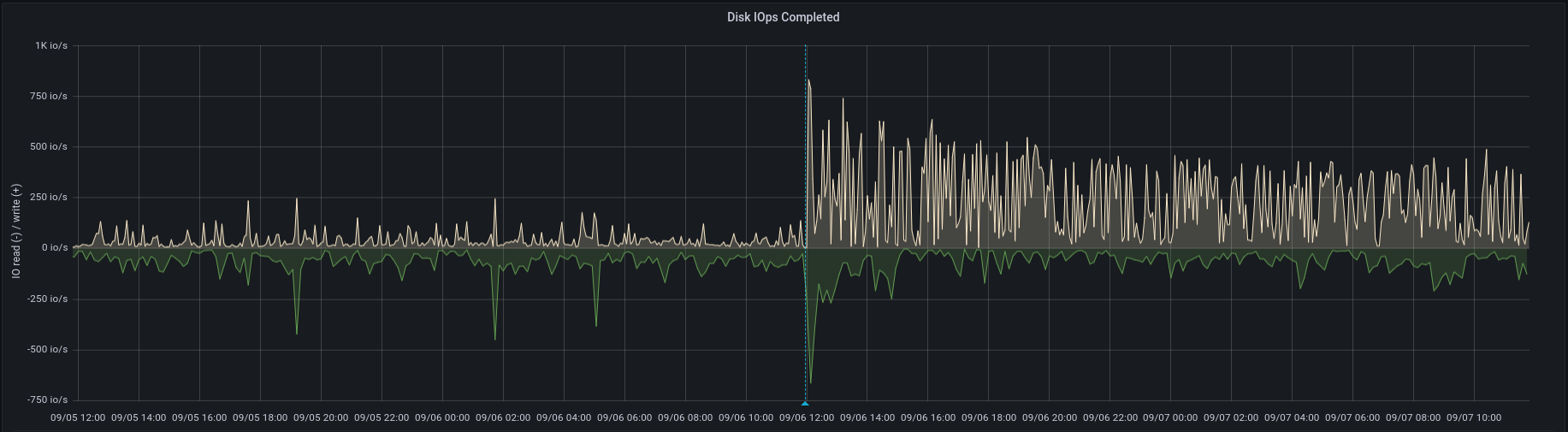
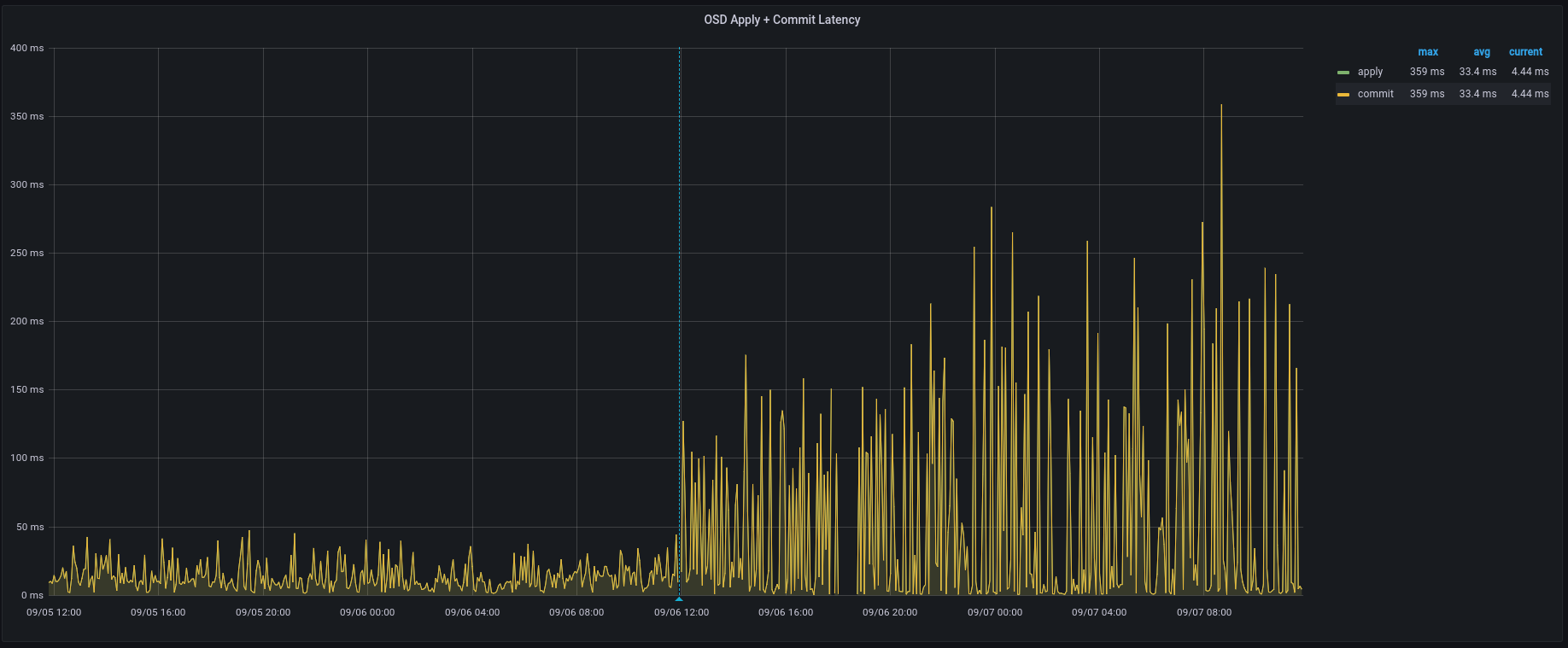
After having run pacific in our low volume staging system for 2 months, yesterday we upgraded our production cluster from octopus to pacific. When the first OSD-Node was upgraded, we saw timeouts in several applications accessing the ceph cluster via radosgw. At first, we thought that was caused due to rebalancing/recovery, but the problem did persist after the cluster was green again. Every 10 Minutes, we experience a rise in latency. After seeking for a possible cause, we could see in our metric system that disk IO has gone up since the restart of the OSD-Nodes. Searching further, we saw that the interval ingest volume in the rocksdb statistics has also gone up by around factor 200 (see attached log excerpt).
The IO has increased on the blockdb-devices (which are SSDs), IO on the data devices (normal HDDs) has not increased. The general setup is one SSD with multiple LVM volumes which act as blockdb devices for the HDDs (everything on bluestore).
Files
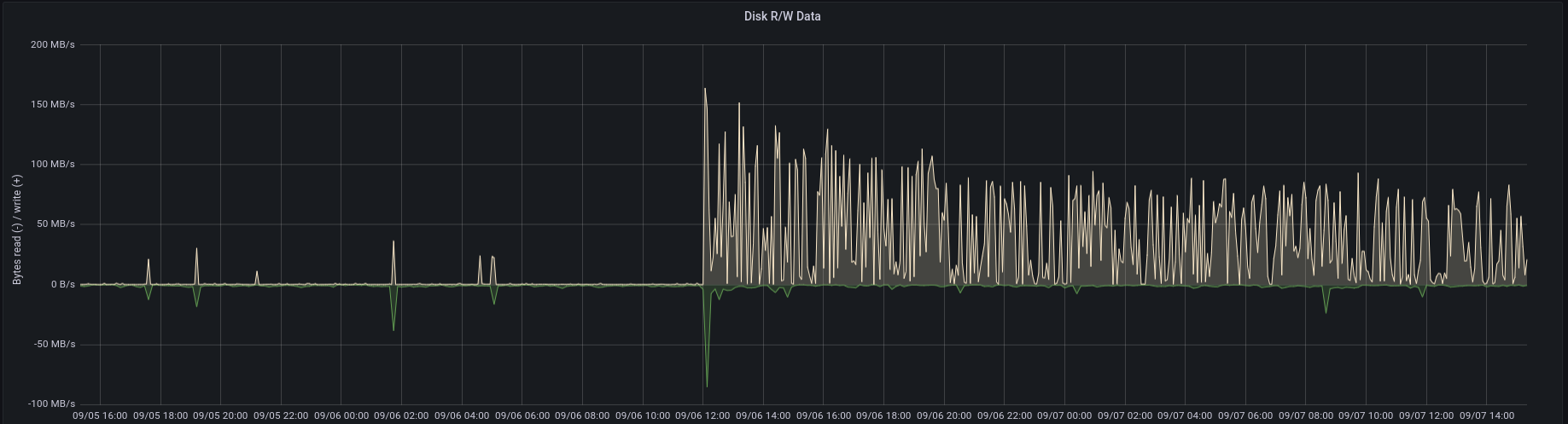
I attached another graph showing the increased amount of written data.
- Project changed from Ceph to RADOS
We started rolling out 16.2.5-522-gde2ff323-1bionic from the dev repos on the osd nodes, as there is no release/tag v16.2.6 until now. The dev builds contain the mentioned commit. As of now, it seems to have fixed the problem.
The cluster is running without any problems since we rolled out the latest dev release from the pacific branch to all nodes. Regarding the issue status, I am not allowed to change any of the fields, the stay read-only while editing.
Roland Sommer wrote:
The cluster is running without any problems since we rolled out the latest dev release from the pacific branch to all nodes. Regarding the issue status, I am not allowed to change any of the fields, the stay read-only while editing.
So I'm to mark this ticket as duplicate and close. Any objections?
The ticket can be closed from our side - and it may be a duplicate, but I'm not able to say this for sure. But I have no objections if this is marked as duplicate. Thanks for the quick help.
- Status changed from New to Duplicate
- Is duplicate of Bug #52089: Deferred writes are unexpectedly applied to large writes on spinners added
Also available in: Atom
PDF
{kind=link}
{kind=link}
{kind=link}