Bug #24937
closed[rgw] Very high cache misses with automatic bucket resharding
0%
Description
Hi, guys.
I use Luminous 12.2.5.
Automatic bucket index resharding has not been activated in the past.
Few days ago i activated auto. resharding.
After that and now i see:
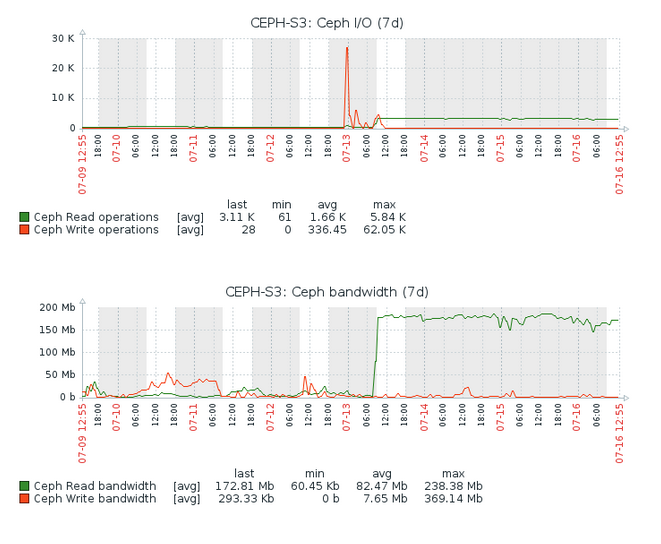
- very high Ceph read I/O (~300 I/O before activating resharding, ~4k now),
- very high Ceph read bandwidth (50 MB/s before activating resharding, 250 MB/s now),
- very high RGW cache miss (400 count/s before activating resharding, ~3.5k now).
For Ceph monitoring i use MGR+Zabbix plugin and zabbix-template from ceph github repo.
For RGW monitoring i use RGW perf dump and my script.
Files
{kind=link}
{kind=link}
Updated by Aleksandr Rudenko almost 6 years ago
I think i have this problem:
RGW Dynamic bucket index resharding keeps resharding all buckets - https://tracker.ceph.com/issues/24551?next_issue_id=24546&prev_issue_id=24562
I think RGW was resharding buckets over and over again but in my case this reproduced on versioning disabled buckets:
radosgw-admin reshard list
...
{
"time": "2018-07-17 11:08:20.336354Z",
"tenant": "",
"bucket_name": "bucket-name",
"bucket_id": "default.32785769.2",
"new_instance_id": "",
"old_num_shards": 1,
"new_num_shards": 161
},
...
radosgw-admin bucket limit check
...
{
"bucket": "bucket-name",
"tenant": "",
"num_objects": 20840702,
"num_shards": 161,
"objects_per_shard": 129445,
"fill_status": "OVER 100.000000%"
},
...
Updated by J. Eric Ivancich over 5 years ago
This may be related to the problem addressed by http://tracker.ceph.com/issues/27219 . The problem there was that due to high load, resharding could not complete before the resharding lock expired. This PR does a number of things to address this, including renewing the lock periodically to allow resharding to complete.
Updated by J. Eric Ivancich over 5 years ago
- Status changed from New to Pending Backport
- Assignee set to J. Eric Ivancich
This PR (https://github.com/ceph/ceph/pull/24898) is a luminous backport of a bug fix that resolved this in both master and downstream ceph. The bug-fix will allow resharding to complete if it's taking too long. It does this by periodically renewing the reshard lock. Previously the reshard lock could be lost and another reshard job started, thereby creating the problem described.
Updated by Nathan Cutler over 5 years ago
- Status changed from Pending Backport to Resolved
Backports are going via #27219
Updated by Nathan Cutler over 5 years ago
- Related to Bug #27219: lock in resharding may expires before the dynamic resharding completes added