Bug #10823
closedThe existance of snapshots causes huge performance issues
0%
Description
Having snapshots of rbd images (just the existing of the snapshots for backup purposes, no fancy stuff like layering) has a huge performance impact on the performance of the whole ceph cluster. This applies to throughput and latency.
Rados Benchmark with having 7 Snapshots per RBD Image:
------------------
Total time run: 301.939224
Total writes made: 3366
Write size: 4194304
Bandwidth (MB/sec): 44.592
Stddev Bandwidth: 32.8543
Max bandwidth (MB/sec): 164
Min bandwidth (MB/sec): 0
Average Latency: 1.43471
Stddev Latency: 1.92137
Max latency: 17.6235
Min latency: 0.044953
------------------
Rados Benchmark after removing all snapshots:
------------------
Total time run: 300.615888
Total writes made: 7343
Write size: 4194304
Bandwidth (MB/sec): 97.706
Stddev Bandwidth: 50.4059
Max bandwidth (MB/sec): 256
Min bandwidth (MB/sec): 0
Average Latency: 0.655008
Stddev Latency: 0.817465
Max latency: 10.1572
Min latency: 0.042001
------------------
Setup:
- ceph version 0.87 (c51c8f9d80fa4e0168aa52685b8de40e42758578)
- 4 Ceph Nodes with 10 spinning disks (sata raid editions 2TB) and 6 SSDs.
- all Journals are on SSDs.
- The Nodes are linked with 10GbE.
- currently 16 VM Images
- replicated size 3
- Ceph Nodes run Ubuntu Trusty with updated Kernel (3.18.0)
Skript used to create the snapshots:
--------------------
#!/bin/bash
DATE=$(date +"%Y%m%d_%H:%M")
MYTAG=autosnapshot
for IMAGE in $(rbd ls); do
rbd snap create $IMAGE@$MYTAG-$DATE
sleep 180
done
--------------------
Attachments:
- ceph.conf
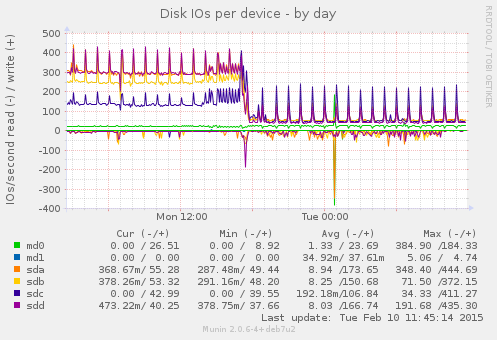
- munin disk io graph of one node (snapshots were have been removed at 18:00, afterwards I ran hourly rados benchmarks)
- zabbix io wait graph for a VM using the cluster (snapshots were have been removed at 18:00, afterwards I ran hourly rados benchmarks)
Files
{kind=link}
{kind=link}