Bug #53924
openEC PG stuckrecovery_unfound+undersized+degraded+remapped+peered
Added by Vikhyat Umrao over 2 years ago. Updated about 2 years ago.
0%
Description
# ceph -s
cluster:
id: 433323be-7878-11ec-b17f-000af7995756
health: HEALTH_ERR
Reduced data availability: 1 pg inactive
Possible data damage: 1 pg recovery_unfound
Degraded data redundancy: 8886/10297821 objects degraded (0.086%), 1 pg degraded, 1 pg undersized
services:
mon: 5 daemons, quorum f28-h28-000-r630.rdu2.scalelab.redhat.com,f28-h29-000-r630,f28-h30-000-r630,f22-h21-000-6048r,f22-h25-000-6048r (age 4h)
mgr: f28-h28-000-r630.rdu2.scalelab.redhat.com.vqxcfs(active, since 4h), standbys: f28-h29-000-r630.gxhqto
osd: 192 osds: 192 up (since 4h), 192 in (since 4h); 1 remapped pgs
rgw: 8 daemons active (8 hosts, 1 zones)
data:
pools: 7 pools, 931 pgs
objects: 1.72M objects, 6.2 TiB
usage: 12 TiB used, 343 TiB / 355 TiB avail
pgs: 0.107% pgs not active
8886/10297821 objects degraded (0.086%)
930 active+clean
1 recovery_unfound+undersized+degraded+remapped+peered
progress:
Global Recovery Event (2h)
[===========================.] (remaining: 11s)
- Health detail
# ceph health detail
HEALTH_ERR Reduced data availability: 1 pg inactive; Possible data damage: 1 pg recovery_unfound; Degraded data redundancy: 8886/10310745 objects degraded (0.086%), 1 pg degraded, 1 pg undersized
[WRN] PG_AVAILABILITY: Reduced data availability: 1 pg inactive
pg 13.2eb is stuck inactive for 3h, current state recovery_unfound+undersized+degraded+remapped+peered, last acting [33,103,NONE,123,66,NONE]
[ERR] PG_DAMAGED: Possible data damage: 1 pg recovery_unfound
pg 13.2eb is recovery_unfound+undersized+degraded+remapped+peered, acting [33,103,NONE,123,66,NONE]
[WRN] PG_DEGRADED: Degraded data redundancy: 8886/10310745 objects degraded (0.086%), 1 pg degraded, 1 pg undersized
pg 13.2eb is stuck undersized for 3h, current state recovery_unfound+undersized+degraded+remapped+peered, last acting [33,103,NONE,123,66,NONE]
# ceph version ceph version 17.0.0-10229-g7e035110 (7e035110784fba02ba81944e444be9a36932c6a3) quincy (dev)
- No OSD flapped and this PG went to this recovery_unfound state looks like maybe while autoscaler was changing the PG count?
2022-01-18T16:54:01.511939+0000 mgr.f28-h28-000-r630.rdu2.scalelab.redhat.com.vqxcfs (mgr.14222) 1808 : cluster [DBG] pgmap v2900: 1762 pgs: 1 activating, 2 peering, 1 clean+premerge+peered, 1758 active+clean; 176 GiB data, 6.0 TiB used, 349 TiB / 355 TiB avail; 327 KiB/s rd, 3.0 GiB/s wr, 1.91k op/s; 186/288795 objects degraded (0.064%); 31/48198 objects unfound (0.064%) 2022-01-18T17:38:30.310339+0000 mgr.f28-h28-000-r630.rdu2.scalelab.redhat.com.vqxcfs (mgr.14222) 3155 : cluster [DBG] pgmap v6499: 963 pgs: 1 recovery_unfound+undersized+degraded+remapped+peered, 10 recovering+undersized+remapped+peered, 8 recovering+undersized+peered, 944 active+clean; 5.6 TiB data, 11 TiB used, 344 TiB / 355 TiB avail; 60 KiB/s rd, 8.6 GiB/s wr, 3.46k op/s; 8886/9263667 objects degraded (0.096%); 159823/9263667 objects misplaced (1.725%); 376 MiB/s, 103 objects/s recovering
Files
| 13.2eb.query.txt (68.1 KB) 13.2eb.query.txt | Vikhyat Umrao, 01/18/2022 09:14 PM | ||
| ceph-osd.33.unfound.log (227 KB) ceph-osd.33.unfound.log | Vikhyat Umrao, 01/18/2022 09:20 PM | ||
| 7.dc4.query.txt (68.5 KB) 7.dc4.query.txt | Vikhyat Umrao, 02/07/2022 08:27 PM | ||
| 7.dc4.osds.logs.txt (108 KB) 7.dc4.osds.logs.txt | Vikhyat Umrao, 02/07/2022 11:33 PM | ||
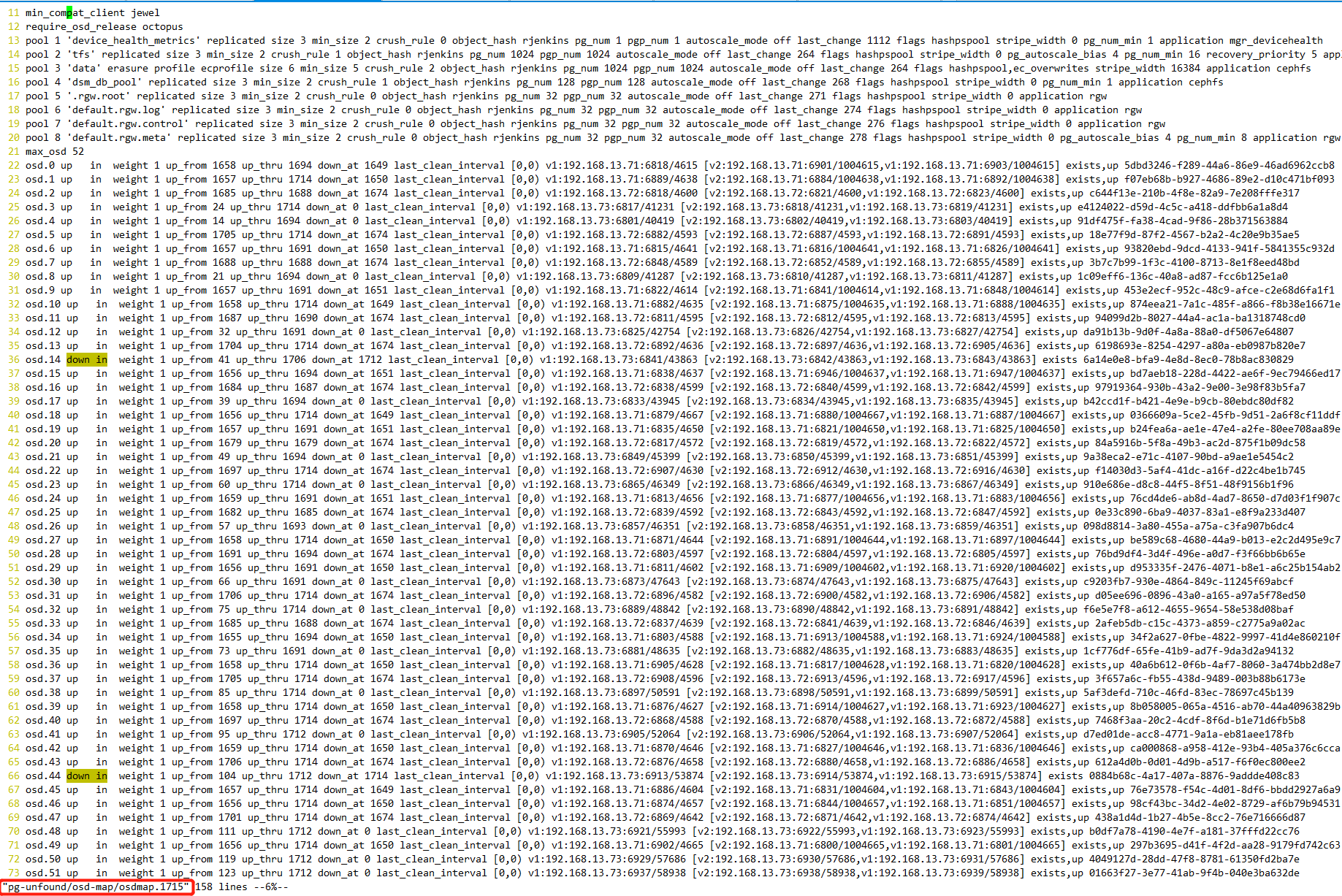
| 1711.png (311 KB) 1711.png | jianwei zhang, 03/09/2022 05:42 AM | ||
| 1715.png (311 KB) 1715.png | jianwei zhang, 03/09/2022 05:42 AM |
{kind=link}
{kind=link}
Updated by Vikhyat Umrao over 2 years ago
- File 13.2eb.query.txt 13.2eb.query.txt added
Ceph PG query!
Updated by Vikhyat Umrao over 2 years ago
- File ceph-osd.33.unfound.log ceph-osd.33.unfound.log added
Ceph OSD 33 Logs with grep unfound!
Updated by Neha Ojha over 2 years ago
Looks like the last time the PG was active was at "2022-01-18T17:38:23.338"
ceph-osd.104.log:2022-01-18T16:52:07.426+0000 7f2c99787700 1 osd.104 pg_epoch: 1389 pg[13.2ebs0( empty local-lis/les=0/0 n=0 ec=1389/1389 lis/c=0/0 les/c/f=0/0/0 sis=1389) [104,93,121,166,43,111]p104(0) r=0 lpr=1389 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
ceph-osd.104.log:2022-01-18T17:38:23.338+0000 7f2c99787700 1 osd.104 pg_epoch: 3726 pg[13.2ebs0( v 3724'1481 (0'0,3724'1481] local-lis/les=1389/1390 n=1481 ec=1389/1389 lis/c=1389/1389 les/c/f=1390/1390/0 sis=3726 pruub=9.287206650s) [33,103,158,123,66,168]p33(0) r=-1 lpr=3726 pi=[1389,3726)/1 crt=3724'1481 lcod 3724'1480 mlcod 3724'1480 active pruub 5108.907226562s@ mbc={}] start_peering_interval up [104,93,121,166,43,111] -> [33,103,158,123,66,168], acting [104,93,121,166,43,111] -> [33,103,158,123,66,168], acting_primary 104(0) -> 33, up_primary 104(0) -> 33, role 0 -> -1, features acting 4540138303579357183 upacting 4540138303579357183
ceph-osd.104.log:2022-01-18T17:38:23.340+0000 7f2c99787700 1 osd.104 pg_epoch: 3726 pg[13.2ebs0( v 3724'1481 (0'0,3724'1481] local-lis/les=1389/1390 n=1481 ec=1389/1389 lis/c=1389/1389 les/c/f=1390/1390/0 sis=3726 pruub=9.286009789s) [33,103,158,123,66,168]p33(0) r=-1 lpr=3726 pi=[1389,3726)/1 crt=3724'1481 lcod 3724'1480 mlcod 0'0 unknown NOTIFY pruub 5108.907226562s@ mbc={}] state<Start>: transitioning to Stray
ceph-osd.104.log:2022-01-18T17:38:24.369+0000 7f2c99787700 1 osd.104 pg_epoch: 3727 pg[13.2ebs0( v 3724'1481 (0'0,3724'1481] local-lis/les=1389/1390 n=1481 ec=1389/1389 lis/c=1389/1389 les/c/f=1390/1390/0 sis=3727) [33,103,158,123,66,168]/[33,103,NONE,123,66,NONE]p33(0) r=-1 lpr=3727 pi=[1389,3727)/1 crt=3724'1481 lcod 3724'1480 mlcod 0'0 remapped NOTIFY mbc={}] start_peering_interval up [33,103,158,123,66,168] -> [33,103,158,123,66,168], acting [33,103,158,123,66,168] -> [33,103,2147483647,123,66,2147483647], acting_primary 33(0) -> 33, up_primary 33(0) -> 33, role -1 -> -1, features acting 4540138303579357183 upacting 4540138303579357183
ceph-osd.104.log:2022-01-18T17:38:24.369+0000 7f2c99787700 1 osd.104 pg_epoch: 3727 pg[13.2ebs0( v 3724'1481 (0'0,3724'1481] local-lis/les=1389/1390 n=1481 ec=1389/1389 lis/c=1389/1389 les/c/f=1390/1390/0 sis=3727) [33,103,158,123,66,168]/[33,103,NONE,123,66,NONE]p33(0) r=-1 lpr=3727 pi=[1389,3727)/1 crt=3724'1481 lcod 3724'1480 mlcod 0'0 remapped NOTIFY mbc={}] state<Start>: transitioning to Stray
ceph-osd.33.log:2022-01-18T17:38:23.332+0000 7fc6a5712700 1 osd.33 pg_epoch: 3726 pg[13.2ebs0( empty local-lis/les=0/0 n=0 ec=1389/1389 lis/c=1389/1389 les/c/f=1390/1390/0 sis=3726) [33,103,158,123,66,168]p33(0) r=0 lpr=3726 pi=[1389,3726)/1 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
Updated by Vikhyat Umrao over 2 years ago
We have marked the primary OSD.33 down [1] and it has helped the stuck recovery_unfound pg to get unstuck and recovery started progressing and PG has recovered now.
While we were troubleshooting we had enabled debug logs debug_osd = 20 and debug_ms = 1. The logs are available in all the cluster nodes, following path:
/root/220120-0059_tracker53924_ceph /root/220120-0059_tracker53924_sa
[1] ceph osd down 33
Updated by Vikhyat Umrao about 2 years ago
- File 7.dc4.query.txt 7.dc4.query.txt added
- This was reproduced again today
# ceph health detail
HEALTH_ERR Reduced data availability: 1 pg inactive; Possible data damage: 1 pg recovery_unfound; Degraded data redundancy: 2394/62079768 objects degraded (0.004%), 1 pg degraded, 1 pg undersized
[WRN] PG_AVAILABILITY: Reduced data availability: 1 pg inactive
pg 7.dc4 is stuck inactive for 39m, current state recovery_unfound+undersized+degraded+peered, last acting [NONE,NONE,37,0,4,100]
[ERR] PG_DAMAGED: Possible data damage: 1 pg recovery_unfound
pg 7.dc4 is recovery_unfound+undersized+degraded+peered, acting [NONE,NONE,37,0,4,100]
[WRN] PG_DEGRADED: Degraded data redundancy: 2394/62079768 objects degraded (0.004%), 1 pg degraded, 1 pg undersized
pg 7.dc4 is stuck undersized for 39m, current state recovery_unfound+undersized+degraded+peered, last acting [NONE,NONE,37,0,4,100]
- ceph status
# ceph -s
cluster:
id: a47cb8d8-883b-11ec-9a25-000af7995d6c
health: HEALTH_ERR
Reduced data availability: 1 pg inactive
Possible data damage: 1 pg recovery_unfound
Degraded data redundancy: 2394/62079768 objects degraded (0.004%), 1 pg degraded, 1 pg undersized
services:
mon: 3 daemons, quorum f28-h21-000-r630.rdu2.scalelab.redhat.com,f28-h22-000-r630,f28-h23-000-r630 (age 2h)
mgr: f28-h23-000-r630.wqrjbv(active, since 34m), standbys: f28-h21-000-r630.rdu2.scalelab.redhat.com.gyushj, f28-h22-000-r630.oojyea
osd: 192 osds: 192 up (since 2h), 192 in (since 2h); 1 remapped pgs
rgw: 8 daemons active (8 hosts, 1 zones)
data:
pools: 7 pools, 4097 pgs
objects: 10.35M objects, 144 GiB
usage: 6.1 TiB used, 349 TiB / 355 TiB avail
pgs: 0.024% pgs not active
2394/62079768 objects degraded (0.004%)
4096 active+clean
1 recovery_unfound+undersized+degraded+peered
Again marking osd.103 fixed the PG.
# ceph osd down 103 marked down osd.103.
- The ceph status
# ceph -s
cluster:
id: a47cb8d8-883b-11ec-9a25-000af7995d6c
health: HEALTH_OK
services:
mon: 3 daemons, quorum f28-h21-000-r630.rdu2.scalelab.redhat.com,f28-h22-000-r630,f28-h23-000-r630 (age 2h)
mgr: f28-h23-000-r630.wqrjbv(active, since 41m), standbys: f28-h21-000-r630.rdu2.scalelab.redhat.com.gyushj, f28-h22-000-r630.oojyea
osd: 192 osds: 192 up (since 2m), 192 in (since 2h); 100 remapped pgs
rgw: 8 daemons active (8 hosts, 1 zones)
data:
pools: 7 pools, 4215 pgs
objects: 12.25M objects, 171 GiB
usage: 6.2 TiB used, 349 TiB / 355 TiB avail
pgs: 4205 active+clean
8 active+clean+scrubbing+deep
2 active+clean+scrubbing
io:
client: 67 MiB/s rd, 138 MiB/s wr, 68.85k op/s rd, 111.21k op/s wr
Updated by Vikhyat Umrao about 2 years ago
Vikhyat Umrao wrote:
- This was reproduced again today
As this issue is random we did not have debug logs from the time of the issue but default level logs are available at following location:
f28-h21-000-r630:~/tracker53924
Updated by Vikhyat Umrao about 2 years ago
Vikhyat Umrao wrote:
Vikhyat Umrao wrote:
- This was reproduced again today
As this issue is random we did not have debug logs from the time of the issue but default level logs are available at following location:
[...]
Ceph version where it was reproduced:
ceph version 17.0.0-10292-gd34c9171 (d34c917198765ac4750818b2bf334e91a0d6b085) quincy (dev)
Updated by Neha Ojha about 2 years ago
- Subject changed from 1 PG stuck in state recovery_unfound+undersized+degraded+remapped+peered to EC PG stuckrecovery_unfound+undersized+degraded+remapped+peered
- Priority changed from Normal to High
Updated by Vikhyat Umrao about 2 years ago
- PG query:
{
"snap_trimq": "[]",
"snap_trimq_len": 0,
"state": "recovery_unfound+undersized+degraded+peered",
"epoch": 851,
"up": [
103,
172,
37,
0,
4,
100
],
"acting": [
2147483647,
2147483647,
37,
0,
4,
100
],
"async_recovery_targets": [
"103(0)",
"172(1)"
],
"acting_recovery_backfill": [
"0(3)",
"4(4)",
"37(2)",
"100(5)",
"103(0)",
"172(1)"
],
<....>
"recovery_state": [
{
"name": "Started/Primary/Active",
"enter_time": "2022-02-07T19:40:18.943184+0000",
"might_have_unfound": [
{
"osd": "0(3)",
"status": "already probed"
},
{
"osd": "3(4)",
"status": "already probed"
},
{
"osd": "4(4)",
"status": "already probed"
},
{
"osd": "35(5)",
"status": "already probed"
},
{
"osd": "73(2)",
"status": "already probed"
},
{
"osd": "100(5)",
"status": "already probed"
},
{
"osd": "103(0)",
"status": "already probed"
},
{
"osd": "115(1)",
"status": "already probed"
},
{
"osd": "116(0)",
"status": "already probed"
},
{
"osd": "156(3)",
"status": "already probed"
},
{
"osd": "172(1)",
"status": "already probed"
}
],
Cluster logs:
2022-02-07T19:40:17.919950+0000 mgr.f28-h22-000-r630.oojyea (mgr.14312) 243 : cluster [DBG] pgmap v453: 3981 pgs: 1 active+remapped+backfilling, 3 active+clean+scrubbing+deep, 3977 active+clean; 24 GiB data, 5.9 TiB used, 349 TiB / 355 TiB avail; 17 MiB/s rd, 0 B/s wr, 22.64k op/s; 3/10388223 objects misplaced (0.000%) ^^ All good here! 2022-02-07T19:40:17.925002+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5707 : cluster [DBG] osdmap e788: 192 total, 192 up, 192 in 2022-02-07T19:40:18.083683+0000 osd.172 (osd.172) 58 : cluster [DBG] 7.542 scrub ok 2022-02-07T19:40:18.097759+0000 osd.156 (osd.156) 57 : cluster [DBG] 7.57d scrub ok 2022-02-07T19:40:18.110769+0000 osd.109 (osd.109) 30 : cluster [DBG] 7.5d5 scrub ok 2022-02-07T19:40:18.442642+0000 osd.180 (osd.180) 57 : cluster [DBG] 7.cda scrub ok 2022-02-07T19:40:18.254738+0000 osd.167 (osd.167) 23 : cluster [DBG] 7.e0f scrub ok 2022-02-07T19:40:18.431725+0000 osd.54 (osd.54) 47 : cluster [DBG] 7.d57 scrub ok 2022-02-07T19:40:18.625135+0000 osd.83 (osd.83) 37 : cluster [DBG] 7.d74 scrub ok 2022-02-07T19:40:18.648020+0000 osd.127 (osd.127) 21 : cluster [DBG] 7.612 deep-scrub ok 2022-02-07T19:40:18.923522+0000 osd.106 (osd.106) 39 : cluster [DBG] 7.5b6 scrub ok 2022-02-07T19:40:18.937767+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5712 : cluster [DBG] osdmap e789: 192 total, 192 up, 192 in 2022-02-07T19:40:19.097710+0000 osd.98 (osd.98) 42 : cluster [DBG] 7.5e5 scrub ok 2022-02-07T19:40:19.432904+0000 osd.187 (osd.187) 44 : cluster [DBG] 7.5f1 deep-scrub ok 2022-02-07T19:40:19.329065+0000 osd.85 (osd.85) 55 : cluster [DBG] 7.565 deep-scrub ok 2022-02-07T19:40:19.945830+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5713 : cluster [DBG] osdmap e790: 192 total, 192 up, 192 in 2022-02-07T19:40:19.946321+0000 osd.89 (osd.89) 31 : cluster [DBG] 7.5c8 deep-scrub ok *2022-02-07T19:40:19*.946928+0000 mgr.f28-h22-000-r630.oojyea (mgr.14312) 244 : cluster [DBG] pgmap v456: 4071 pgs: 1 recovery_unfound+undersized+degraded+peered, 58 recovering+undersized+remapped+peered, 26 recovering+undersized+peered, 85 peering, 1 active+remapped+backfilling, 90 unknown, 2 active+clean+scrubbing+deep, 3808 active+clean; 24 GiB data, 5.9 TiB used, 349 TiB / 355 TiB avail; 35 MiB/s rd, 35.35k op/s; 2394/10290471 objects degraded (0.023%); 203315/10290471 objects misplaced (1.976%) ^^ This is the time when this recovery_unfound was hit! 2022-02-07T19:40:20.945592+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5714 : cluster [ERR] Health check failed: Possible data damage: 1 pg recovery_unfound (PG_DAMAGED) 2022-02-07T19:40:20.945624+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5715 : cluster [WRN] Health check failed: Degraded data redundancy: 2394/10290471 objects degraded (0.023%), 1 pg degraded (PG_DEGRADED) 2022-02-07T19:40:20.657888+0000 osd.155 (osd.155) 44 : cluster [DBG] 7.610 deep-scrub ok 2022-02-07T19:40:20.954803+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5716 : cluster [DBG] osdmap e791: 192 total, 192 up, 192 in 2022-02-07T19:40:21.950836+0000 mgr.f28-h22-000-r630.oojyea (mgr.14312) 245 : cluster [DBG] pgmap v459: 4071 pgs: 1 remapped+peering, 1 recovery_unfound+undersized+degraded+peered, 62 recovering+undersized+remapped+peered, 27 recovering+undersized+peered, 87 peering, 1 active+remapped+backfilling, 84 unknown, 2 active+clean+scrubbing+deep, 3806 active+clean; 24 GiB data, 5.9 TiB used, 349 TiB / 355 TiB avail; 25 MiB/s rd, 25.92k op/s; 2394/10288521 objects degraded (0.023%); 214041/10288521 objects misplaced (2.080%) 2022-02-07T19:40:23.954133+0000 mgr.f28-h22-000-r630.oojyea (mgr.14312) 246 : cluster [DBG] pgmap v460: 4071 pgs: 1 remapped+peering, 1 recovery_unfound+undersized+degraded+peered, 62 recovering+undersized+remapped+peered, 27 recovering+undersized+peered, 87 peering, 1 active+remapped+backfilling, 84 unknown, 2 active+clean+scrubbing+deep, 3806 active+clean; 24 GiB data, 5.9 TiB used, 349 TiB / 355 TiB avail; 17 MiB/s rd, 17.34k op/s; 2394/10288521 objects degraded (0.023%); 214041/10288521 objects misplaced (2.080%) 2022-02-07T19:40:23.989617+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5717 : cluster [DBG] osdmap e792: 192 total, 192 up, 192 in 2022-02-07T19:40:24.997585+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5719 : cluster [DBG] osdmap e793: 192 total, 192 up, 192 in 2022-02-07T19:40:25.958563+0000 mgr.f28-h22-000-r630.oojyea (mgr.14312) 247 : cluster [DBG] pgmap v463: 4071 pgs: 1 recovery_unfound+undersized+degraded+peered, 11 undersized+remapped+peered, 1 active+remapped+backfilling, 5 undersized+peered, 69 recovering+undersized+remapped+peered, 37 recovering+undersized+peered, 5 peering, 3942 active+clean; 25 GiB data, 5.9 TiB used, 349 TiB / 355 TiB avail; 9.1 MiB/s rd, 109 MiB/s wr, 81.10k op/s; 2394/10577769 objects degraded (0.023%); 78743/10577769 objects misplaced (0.744%); 90 MiB/s, 6.38k objects/s recovering 2022-02-07T19:40:26.005406+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5720 : cluster [DBG] osdmap e794: 192 total, 192 up, 192 in 2022-02-07T19:40:26.006193+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5721 : cluster [WRN] Health check update: Degraded data redundancy: 2394/10577769 objects degraded (0.023%), 1 pg degraded (PG_DEGRADED) 2022-02-07T19:40:26.594424+0000 osd.127 (osd.127) 22 : cluster [DBG] 7.628 scrub ok 2022-02-07T19:40:26.808008+0000 osd.144 (osd.144) 47 : cluster [DBG] 7.cf2 scrub ok 2022-02-07T19:40:26.821307+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5723 : cluster [DBG] osdmap e795: 192 total, 192 up, 192 in 2022-02-07T19:40:27.094512+0000 osd.135 (osd.135) 51 : cluster [DBG] 7.5dc scrub ok
- Audit logs:
2022-02-07T19:40:16.910177+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5705 : audit [INF] from='mgr.14312 172.16.45.16:0/370746128' entity='mgr.f28-h22-000-r630.oojyea' cmd='[{"prefix": "osd pool set", "pool": "default.rgw.buckets.data", "var": "pgp_num_actual", "val": "3571"}]': finished
2022-02-07T19:40:17.925285+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5708 : audit [INF] from='mgr.14312 172.16.45.16:0/370746128' entity='mgr.f28-h22-000-r630.oojyea' cmd=[{"prefix": "osd pool set", "pool": "default.rgw.buckets.data", "var": "pg_num_actual", "val": "3699"}]: dispatch
2022-02-07T19:40:17.925444+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5709 : audit [INF] from='mgr.14312 172.16.45.16:0/370746128' entity='mgr.f28-h22-000-r630.oojyea' cmd=[{"prefix": "osd pool set", "pool": "default.rgw.buckets.data", "var": "pgp_num_actual", "val": "3609"}]: dispatch
2022-02-07T19:40:18.937087+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5710 : audit [INF] from='mgr.14312 172.16.45.16:0/370746128' entity='mgr.f28-h22-000-r630.oojyea' cmd='[{"prefix": "osd pool set", "pool": "default.rgw.buckets.data", "var": "pg_num_actual", "val": "3699"}]': finished
2022-02-07T19:40:18.937187+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5711 : audit [INF] from='mgr.14312 172.16.45.16:0/370746128' entity='mgr.f28-h22-000-r630.oojyea' cmd='[{"prefix": "osd pool set", "pool": "default.rgw.buckets.data", "var": "pgp_num_actual", "val": "3609"}]': finished
^^ Autoscaler was doing its job
2022-02-07T19:40:24.073328+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5718 : audit [DBG] from='client.? 172.16.44.156:0/3596211677' entity='client.admin' cmd=[{"prefix": "status"}]: dispatch
2022-02-07T19:40:36.013875+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5732 : audit [INF] from='mgr.14312 172.16.45.16:0/370746128' entity='mgr.f28-h22-000-r630.oojyea' cmd=[{"prefix": "osd pool set", "pool": "default.rgw.buckets.data", "var": "pg_num_actual", "val": "3737"}]: dispatch
2022-02-07T19:40:36.073438+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5733 : audit [INF] from='mgr.14312 172.16.45.16:0/370746128' entity='mgr.f28-h22-000-r630.oojyea' cmd='[{"prefix": "osd pool set", "pool": "default.rgw.buckets.data", "var": "pg_num_actual", "val": "3737"}]': finished
2022-02-07T19:40:37.226707+0000 mon.f28-h21-000-r630.rdu2.scalelab.redhat.com (mon.0) 5737 : audit [DBG] from='client.? 172.16.44.156:0/4211863871' entity='client.admin' cmd=[{"prefix": "df"}]: dispatch
- The OSD.100 has an entry in the same time:
ceph-osd.100.log:2022-02-07T19:40:19.003+0000 7f0bc2fcf700 1 osd.100 pg_epoch: 788 pg[7.dc4s5( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=788) [103,172,37,0,4,100]/[NONE,NONE,37,0,4,100]p37(2) r=5 lpr=788 pi=[776,788)/1 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Stray
- The empty local-lis
# cat 7.dc4.txt | grep "empty local-lis"
ceph-osd.0.log:2022-02-07T19:40:18.948+0000 7f8cb793f700 1 osd.0 pg_epoch: 788 pg[7.dc4s3( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=788) [103,172,37,0,4,100]/[NONE,NONE,37,0,4,100]p37(2) r=3 lpr=788 pi=[776,788)/1 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Stray
ceph-osd.100.log:2022-02-07T19:40:19.003+0000 7f0bc2fcf700 1 osd.100 pg_epoch: 788 pg[7.dc4s5( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=788) [103,172,37,0,4,100]/[NONE,NONE,37,0,4,100]p37(2) r=5 lpr=788 pi=[776,788)/1 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Stray
ceph-osd.103.log:2022-02-07T19:40:16.922+0000 7fd345ad8700 1 osd.103 pg_epoch: 787 pg[7.dc4s0( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=787) [103,172,37,0,4,100]p103(0) r=0 lpr=787 pi=[776,787)/1 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
ceph-osd.103.log:2022-02-07T19:40:17.930+0000 7fd345ad8700 1 osd.103 pg_epoch: 788 pg[7.dc4s0( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=788) [103,172,37,0,4,100]/[NONE,NONE,37,0,4,100]p37(2) r=-1 lpr=788 pi=[776,788)/1 crt=0'0 mlcod 0'0 remapped mbc={}] start_peering_interval up [103,172,37,0,4,100] -> [103,172,37,0,4,100], acting [103,172,37,0,4,100] -> [2147483647,2147483647,37,0,4,100], acting_primary 103(0) -> 37, up_primary 103(0) -> 103, role 0 -> -1, features acting 4540138303579357183 upacting 4540138303579357183
ceph-osd.103.log:2022-02-07T19:40:17.930+0000 7fd345ad8700 1 osd.103 pg_epoch: 788 pg[7.dc4s0( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=788) [103,172,37,0,4,100]/[NONE,NONE,37,0,4,100]p37(2) r=-1 lpr=788 pi=[776,788)/1 crt=0'0 mlcod 0'0 remapped NOTIFY mbc={}] state<Start>: transitioning to Stray
ceph-osd.172.log:2022-02-07T19:40:18.969+0000 7fca0de17700 1 osd.172 pg_epoch: 788 pg[7.dc4s1( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=788) [103,172,37,0,4,100]/[NONE,NONE,37,0,4,100]p37(2) r=-1 lpr=788 pi=[776,788)/1 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Stray
ceph-osd.37.log:2022-02-07T19:40:17.930+0000 7f9a2e3df700 1 osd.37 pg_epoch: 788 pg[7.dc4s2( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=788) [103,172,37,0,4,100]/[NONE,NONE,37,0,4,100]p37(2) r=2 lpr=788 pi=[776,788)/1 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
ceph-osd.4.log:2022-02-07T19:40:18.964+0000 7f9748601700 1 osd.4 pg_epoch: 788 pg[7.dc4s4( empty local-lis/les=0/0 n=0 ec=776/473 lis/c=776/776 les/c/f=777/777/0 sis=788) [103,172,37,0,4,100]/[NONE,NONE,37,0,4,100]p37(2) r=4 lpr=788 pi=[776,788)/1 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Stray
Updated by Vikhyat Umrao about 2 years ago
- File 7.dc4.osds.logs.txt 7.dc4.osds.logs.txt added
PG 7.dc4 - all osd logs.
Updated by jianwei zhang about 2 years ago
I had a similar problem with pg recovery_unfound
cluster:
id: 580bd632-9cfe-11ec-bf2f-0894efa5feb2
health: HEALTH_ERR
1/3984 objects unfound (0.025%)
Possible data damage: 1 pg recovery_unfound
Degraded data redundancy: 3/21411 objects degraded (0.014%), 1 pg degraded
services:
mon: 3 daemons, quorum a,b,c (age 15h)
mgr: c(active, since 26h), standbys: b, a
tfsmds: tfs
3 daemons: 3 up
c = up:running
a = up:running
b = up:running
6 ranks
6 up:active
osd: 52 osds: 52 up (since 15h), 52 in (since 45h)
data:
pools: 8 pools, 2305 pgs
objects: 3.98k objects, 14 GiB
usage: 2.1 TiB used, 104 TiB / 106 TiB avail
pgs: 3/21411 objects degraded (0.014%)
1/3984 objects unfound (0.025%)
2304 active+clean
1 active+recovery_unfound+degraded
HEALTH_ERR 1/3984 objects unfound (0.025%); Possible data damage: 1 pg recovery_unfound; Degraded data redundancy: 3/21411 objects degraded (0.014%), 1 pg degraded
[WRN] OBJECT_UNFOUND: 1/3984 objects unfound (0.025%)
pg 3.356 has 1 unfound objects
[ERR] PG_DAMAGED: Possible data damage: 1 pg recovery_unfound
pg 3.356 is active+recovery_unfound+degraded, acting [49,44,47,18,14,31], 1 unfound
[WRN] PG_DEGRADED: Degraded data redundancy: 3/21411 objects degraded (0.014%), 1 pg degraded
pg 3.356 is active+recovery_unfound+degraded, acting [49,44,47,18,14,31], 1 unfound
"object": "3:6ac67c21:::202000000034931.0000001a:head"
2022-03-07T17:45:43.032075 CREATE "prior_version": "0'0" "version": "1711'7081" client.9726451.0:502630 [1048576~18446744073708503039]
2022-03-07T17:45:43.079405 SETATTRS/APPEND"old_size": 1048576 "prior_version": "1711'7081" "version": "1711'7082" client.9726451.0:502636 [0~1048576,2097152~18446744073707454463]
2022-03-07T17:45:43.127273 SETATTRS/APPEND"old_size": 2097152 "prior_version": "1711'7082" "version": "1711'7083" client.9726451.0:502645 [0~2097152,3145728~18446744073706405887]
2022-03-07T17:45:43.196273 SETATTRS/APPEND"old_size": 3145728 "prior_version": "1711'7083" "version": "1711'7084" client.9726451.0:502665 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:47:39.839244 SETATTRS/ROLLBACK_EXTENTS[786432,262144] "prior_version": "1711'7084" "version": "1711'7107" client.9726451.0:533521 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:48:20.621004 SETATTRS/ROLLBACK_EXTENTS[786432,262144] "prior_version": "1711'7107" "version": "1715'7108" client.9726451.0:535060 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:48:20.800737 SETATTRS/ROLLBACK_EXTENTS[524288,262144] "prior_version": "1715'7108" "version": "1715'7109" client.9726451.0:535092 [0~2097152,3145728~18446744073706405887]
2022-03-07T17:48:21.189924 SETATTRS/ROLLBACK_EXTENTS[262144,262144] "prior_version": "1715'7109" "version": "1715'7110" client.9726451.0:535148 [0~1048576,2097152~18446744073707454463]
osd.49 s0 : 1715'7110
osd.44 s1 : 1711'7107 missing 1715'7110
osd.47 s2 : 1715'7109 missing 1715'7110
osd.18 s3 : 1715'7110
osd.14 s4 : 1711'7107 missing 1715'7110
osd.31 s5 : 1715'7110
[root@node1 ceph]# ceph daemon /var/run/ceph/client-962242-94691926095688.asok objecter_requests
{
"ops": [
{
"tid": 587660,
"pg": "3.843e6356",
"osd": 49,
"object_id": "202000000034931.0000001a",
"object_locator": "@3",
"target_object_id": "202000000034931.0000001a",
"target_object_locator": "@3",
"paused": 0,
"used_replica": 0,
"precalc_pgid": 0,
"last_sent": "0.000000s",
"age": 92909.956575136996,
"attempts": 0,
"snapid": "head",
"snap_context": "1=[]",
"mtime": "2022-03-07T17:48:21.189924+0800",
"osd_ops": [
"write 1048576~1048576 [1@-1] in=1048576b"
]
}
],
"linger_ops": [],
"pool_ops": [],
"pool_stat_ops": [],
"statfs_ops": [],
"command_ops": []
}
在osd.14/44反复coredump的时候,其实是不会影响到ec(4+2)的write写入的,因为满足k=4
但是在17:48:21写入1715'7110(在ec分片时,还满足k=4的要求),并把各个ec分片分发至各自所在osd,s0/3/5写入成功,但17:48:32 osd.47 coredump死亡时,1715'7110为来得及写入到s2,此时k<4,不满足ec k=4的要求了。
在这种场景下,osd不应该向nfs-server返回write op完成,因为不满足k=4
理论上,rados-client(nfsd) 在osdmap发生变化后,会自行重试未完成的write op, nfs-server也的确在一直重试
问题:在s2对应的osd异常后被拉起,nfs-server重试的write op为什么没有在osd重新写入?
Updated by jianwei zhang about 2 years ago
1711'7107 : s0/1/2/3/4/5都有所以都能写下去
1715'7108 : s0/2/3/5 满足k=4,所以能写下去
1715'7109 : s0/2/3/5 满足k=4,所以能写下去
1715'7110 : s0/2/3/5 满足k=4,所以能写下去, 但s2写入失败,s2重启后,recovery_unfound
ec (4+2) : 3 shard write sucess, 1 shard not write, 2 shard that were already in a low version pg-log due to an exception before.
Updated by jianwei zhang about 2 years ago
Updated by jianwei zhang about 2 years ago
[root@node1 ceph]# zcat ceph.client.log-20220308.gz|grep 202000000034931.0000001a
2022-03-08T03:12:25.531+0800 7f484b7fe700 0 client.9726451.objecter _send_op backoff 3.356s0 id 1 on 3:6ac67c21:::202000000034931.0000001a:head, queuing 0x7f468c004b30 tid 581810
2022-03-08T03:13:55.539+0800 7f484b7fe700 0 client.9726451.objecter _send_op backoff 3.356s0 id 1 on 3:6ac67c21:::202000000034931.0000001a:head, queuing 0x7f468c004b30 tid 581820
2022-03-08T03:15:25.548+0800 7f484b7fe700 0 client.9726451.objecter _send_op backoff 3.356s0 id 1 on 3:6ac67c21:::202000000034931.0000001a:head, queuing 0x7f468c004b30 tid 581830
2022-03-08T03:16:55.557+0800 7f484b7fe700 0 client.9726451.objecter _send_op backoff 3.356s0 id 1 on 3:6ac67c21:::202000000034931.0000001a:head, queuing 0x7f468c004b30 tid 581840
2022-03-08T03:18:25.565+0800 7f484b7fe700 0 client.9726451.objecter _send_op backoff 3.356s0 id 1 on 3:6ac67c21:::202000000034931.0000001a:head, queuing 0x7f468c004b30 tid 581850
2022-03-08T03:19:55.576+0800 7f484b7fe700 0 client.9726451.objecter _send_op backoff 3.356s0 id 1 on 3:6ac67c21:::202000000034931.0000001a:head, queuing 0x7f468c004b30 tid 581860
Updated by Neha Ojha about 2 years ago
jianwei zhang wrote:
1711'7107 : s0/1/2/3/4/5都有所以都能写下去
1715'7108 : s0/2/3/5 满足k=4,所以能写下去
1715'7109 : s0/2/3/5 满足k=4,所以能写下去
1715'7110 : s0/2/3/5 满足k=4,所以能写下去, 但s2写入失败,s2重启后,recovery_unfoundec (4+2) : 3 shard write sucess, 1 shard not write, 2 shard that were already in a low version pg-log due to an exception before.
Could you clarify what you mean by 1 shard not write? You could try to set min_size to 4 to see if that helps the PG to recover.
Updated by jianwei zhang about 2 years ago
Neha Ojha wrote:
jianwei zhang wrote:
1711'7107 : s0/1/2/3/4/5都有所以都能写下去
1715'7108 : s0/2/3/5 满足k=4,所以能写下去
1715'7109 : s0/2/3/5 满足k=4,所以能写下去
1715'7110 : s0/2/3/5 满足k=4,所以能写下去, 但s2写入失败,s2重启后,recovery_unfoundec (4+2) : 3 shard write sucess, 1 shard not write, 2 shard that were already in a low version pg-log due to an exception before.
Could you clarify what you mean by 1 shard not write? You could try to set min_size to 4 to see if that helps the PG to recover.
"object": "3:6ac67c21:::202000000034931.0000001a:head"
2022-03-07T17:45:43.032075 CREATE "prior_version": "0'0" "version": "1711'7081" client.9726451.0:502630 [1048576~18446744073708503039]
2022-03-07T17:45:43.079405 SETATTRS/APPEND"old_size": 1048576 "prior_version": "1711'7081" "version": "1711'7082" client.9726451.0:502636 [0~1048576,2097152~18446744073707454463]
2022-03-07T17:45:43.127273 SETATTRS/APPEND"old_size": 2097152 "prior_version": "1711'7082" "version": "1711'7083" client.9726451.0:502645 [0~2097152,3145728~18446744073706405887]
2022-03-07T17:45:43.196273 SETATTRS/APPEND"old_size": 3145728 "prior_version": "1711'7083" "version": "1711'7084" client.9726451.0:502665 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:47:39.839244 SETATTRS/ROLLBACK_EXTENTS[786432,262144] "prior_version": "1711'7084" "version": "1711'7107" client.9726451.0:533521 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:48:20.621004 SETATTRS/ROLLBACK_EXTENTS[786432,262144] "prior_version": "1711'7107" "version": "1715'7108" client.9726451.0:535060 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:48:20.800737 SETATTRS/ROLLBACK_EXTENTS[524288,262144] "prior_version": "1715'7108" "version": "1715'7109" client.9726451.0:535092 [0~2097152,3145728~18446744073706405887]
2022-03-07T17:48:21.189924 SETATTRS/ROLLBACK_EXTENTS[262144,262144] "prior_version": "1715'7109" "version": "1715'7110" client.9726451.0:535148 [0~1048576,2097152~18446744073707454463]
osd.49 s0 : have 1715'7110 ###osd.49(s0) write 1715'7110 success
osd.44 s1 : have 1711'7107 missing 1715'7110 ###osd.44(s1) dead due to coredump
osd.47 s2 : have 1715'7109 missing 1715'7110 ###osd.47(s2) dead due to coredump,
osd.18 s3 : have 1715'7110 ###osd.18(s3) write 1715'7110 success
osd.14 s4 : have 1711'7107 missing 1715'7110 ###osd.14(s4) dead due to coredump
osd.31 s5 : have 1715'7110 ###osd.31(s5) write 1715'7110 success
My confusion is why pg didn't rollback s0/3/5 to 1715'7109 When pg peering resolves object divergence pg-logs ?
Updated by jianwei zhang about 2 years ago
Neha Ojha wrote:
jianwei zhang wrote:
1711'7107 : s0/1/2/3/4/5都有所以都能写下去
1715'7108 : s0/2/3/5 满足k=4,所以能写下去
1715'7109 : s0/2/3/5 满足k=4,所以能写下去
1715'7110 : s0/2/3/5 满足k=4,所以能写下去, 但s2写入失败,s2重启后,recovery_unfoundec (4+2) : 3 shard write sucess, 1 shard not write, 2 shard that were already in a low version pg-log due to an exception before.
Could you clarify what you mean by 1 shard not write? You could try to set min_size to 4 to see if that helps the PG to recover.
I think it should not be the problem of min_size, because the osd of the ceph cluster has been up && in.
osd: 52 osds: 52 up (since 15h), 52 in (since 45h)
Updated by jianwei zhang about 2 years ago
ec(4+2) allow_ec_overwrites
ceph pg 3.356 query
1 {
2 "snap_trimq": "[]",
3 "snap_trimq_len": 0,
4 "state": "active+recovery_unfound+degraded",
5 "epoch": 1786,
6 "up": [
7 49,
8 44,
9 47,
10 18,
11 14,
12 31
13 ],
14 "acting": [
15 49,
16 44,
17 47,
18 18,
19 14,
20 31
21 ],
22 "acting_recovery_backfill": [
23 "14(4)",
24 "18(3)",
25 "31(5)",
26 "44(1)",
27 "47(2)",
28 "49(0)"
29 ],
30 "info": {
31 "pgid": "3.356s0",
32 "last_update": "1734'7141",
33 "last_complete": "1734'7141",
34 "log_tail": "1437'5676",
35 "last_user_version": 7141,
36 "last_backfill": "MAX",
37 "purged_snaps": [],
38 "history": {
39 "epoch_created": 206,
40 "epoch_pool_created": 206,
41 "last_epoch_started": 1734,
42 "last_interval_started": 1733,
43 "last_epoch_clean": 1709,
44 "last_interval_clean": 1706,
45 "last_epoch_split": 0,
46 "last_epoch_marked_full": 0,
47 "same_up_since": 1733,
48 "same_interval_since": 1733,
49 "same_primary_since": 1656,
50 "last_scrub": "0'0",
51 "last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
52 "last_deep_scrub": "0'0",
53 "last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
54 "last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
55 "prior_readable_until_ub": 0
56 },
Updated by Neha Ojha about 2 years ago
jianwei zhang wrote:
Neha Ojha wrote:
jianwei zhang wrote:
1711'7107 : s0/1/2/3/4/5都有所以都能写下去
1715'7108 : s0/2/3/5 满足k=4,所以能写下去
1715'7109 : s0/2/3/5 满足k=4,所以能写下去
1715'7110 : s0/2/3/5 满足k=4,所以能写下去, 但s2写入失败,s2重启后,recovery_unfoundec (4+2) : 3 shard write sucess, 1 shard not write, 2 shard that were already in a low version pg-log due to an exception before.
Could you clarify what you mean by 1 shard not write? You could try to set min_size to 4 to see if that helps the PG to recover.
"object": "3:6ac67c21:::202000000034931.0000001a:head"
2022-03-07T17:45:43.032075 CREATE "prior_version": "0'0" "version": "1711'7081" client.9726451.0:502630 [1048576~18446744073708503039]
2022-03-07T17:45:43.079405 SETATTRS/APPEND"old_size": 1048576 "prior_version": "1711'7081" "version": "1711'7082" client.9726451.0:502636 [0~1048576,2097152~18446744073707454463]
2022-03-07T17:45:43.127273 SETATTRS/APPEND"old_size": 2097152 "prior_version": "1711'7082" "version": "1711'7083" client.9726451.0:502645 [0~2097152,3145728~18446744073706405887]
2022-03-07T17:45:43.196273 SETATTRS/APPEND"old_size": 3145728 "prior_version": "1711'7083" "version": "1711'7084" client.9726451.0:502665 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:47:39.839244 SETATTRS/ROLLBACK_EXTENTS[786432,262144] "prior_version": "1711'7084" "version": "1711'7107" client.9726451.0:533521 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:48:20.621004 SETATTRS/ROLLBACK_EXTENTS[786432,262144] "prior_version": "1711'7107" "version": "1715'7108" client.9726451.0:535060 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:48:20.800737 SETATTRS/ROLLBACK_EXTENTS[524288,262144] "prior_version": "1715'7108" "version": "1715'7109" client.9726451.0:535092 [0~2097152,3145728~18446744073706405887]
2022-03-07T17:48:21.189924 SETATTRS/ROLLBACK_EXTENTS[262144,262144] "prior_version": "1715'7109" "version": "1715'7110" client.9726451.0:535148 [0~1048576,2097152~18446744073707454463]osd.49 s0 : have 1715'7110 ###osd.49(s0) write 1715'7110 success
osd.44 s1 : have 1711'7107 missing 1715'7110 ###osd.44(s1) dead due to coredump
osd.47 s2 : have 1715'7109 missing 1715'7110 ###osd.47(s2) dead due to coredump,
osd.18 s3 : have 1715'7110 ###osd.18(s3) write 1715'7110 success
osd.14 s4 : have 1711'7107 missing 1715'7110 ###osd.14(s4) dead due to coredump
osd.31 s5 : have 1715'7110 ###osd.31(s5) write 1715'7110 success
This might explain why we have 3 shards, where the write was successful and we don't have the fourth shard, which we need for recovery. Is there anything in particular you want us to look at in the pg query output?
My confusion is why pg didn't rollback s0/3/5 to 1715'7109 When pg peering resolves object divergence pg-logs ?
Updated by jianwei zhang about 2 years ago
Neha Ojha wrote:
jianwei zhang wrote:
Neha Ojha wrote:
jianwei zhang wrote:
1711'7107 : s0/1/2/3/4/5都有所以都能写下去
1715'7108 : s0/2/3/5 满足k=4,所以能写下去
1715'7109 : s0/2/3/5 满足k=4,所以能写下去
1715'7110 : s0/2/3/5 满足k=4,所以能写下去, 但s2写入失败,s2重启后,recovery_unfoundec (4+2) : 3 shard write sucess, 1 shard not write, 2 shard that were already in a low version pg-log due to an exception before.
Could you clarify what you mean by 1 shard not write? You could try to set min_size to 4 to see if that helps the PG to recover.
"object": "3:6ac67c21:::202000000034931.0000001a:head"
2022-03-07T17:45:43.032075 CREATE "prior_version": "0'0" "version": "1711'7081" client.9726451.0:502630 [1048576~18446744073708503039]
2022-03-07T17:45:43.079405 SETATTRS/APPEND"old_size": 1048576 "prior_version": "1711'7081" "version": "1711'7082" client.9726451.0:502636 [0~1048576,2097152~18446744073707454463]
2022-03-07T17:45:43.127273 SETATTRS/APPEND"old_size": 2097152 "prior_version": "1711'7082" "version": "1711'7083" client.9726451.0:502645 [0~2097152,3145728~18446744073706405887]
2022-03-07T17:45:43.196273 SETATTRS/APPEND"old_size": 3145728 "prior_version": "1711'7083" "version": "1711'7084" client.9726451.0:502665 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:47:39.839244 SETATTRS/ROLLBACK_EXTENTS[786432,262144] "prior_version": "1711'7084" "version": "1711'7107" client.9726451.0:533521 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:48:20.621004 SETATTRS/ROLLBACK_EXTENTS[786432,262144] "prior_version": "1711'7107" "version": "1715'7108" client.9726451.0:535060 [0~3145728,4194304~18446744073705357311]
2022-03-07T17:48:20.800737 SETATTRS/ROLLBACK_EXTENTS[524288,262144] "prior_version": "1715'7108" "version": "1715'7109" client.9726451.0:535092 [0~2097152,3145728~18446744073706405887]
2022-03-07T17:48:21.189924 SETATTRS/ROLLBACK_EXTENTS[262144,262144] "prior_version": "1715'7109" "version": "1715'7110" client.9726451.0:535148 [0~1048576,2097152~18446744073707454463]osd.49 s0 : have 1715'7110 ###osd.49(s0) write 1715'7110 success
osd.44 s1 : have 1711'7107 missing 1715'7110 ###osd.44(s1) dead due to coredump
osd.47 s2 : have 1715'7109 missing 1715'7110 ###osd.47(s2) dead due to coredump,
osd.18 s3 : have 1715'7110 ###osd.18(s3) write 1715'7110 success
osd.14 s4 : have 1711'7107 missing 1715'7110 ###osd.14(s4) dead due to coredump
osd.31 s5 : have 1715'7110 ###osd.31(s5) write 1715'7110 successThis might explain why we have 3 shards, where the write was successful and we don't have the fourth shard, which we need for recovery. Is there anything in particular you want us to look at in the pg query output?
My confusion is why pg didn't rollback s0/3/5 to 1715'7109 When pg peering resolves object divergence pg-logs ?
[root@node1 ~]# ceph pg 3.356 list_unfound
{
"num_missing": 1,
"num_unfound": 1,
"objects": [
{
"oid": {
"oid": "202000000034931.0000001a",
"key": "",
"snapid": -2,
"hash": 2218681174,
"max": 0,
"pool": 3,
"namespace": ""
},
"need": "1715'7110",
"have": "1711'7107",
"flags": "none",
"clean_regions": "clean_offsets: [0~1048576,4194304~18446744073705357311], clean_omap: 1, new_object: 0",
"locations": [
"18(3)",
"31(5)",
"49(0)"
]
}
],
"more": false
}
the 1715'7110 pg log and missing item
3.356s0.osd49- {
3.356s0.osd49- "op": "modify",
3.356s0.osd49: "object": "3:6ac67c21:::202000000034931.0000001a:head",
3.356s0.osd49- "version": "1715'7110",
3.356s0.osd49- "prior_version": "1715'7109",
3.356s0.osd49- "reqid": "client.9726451.0:535148",
3.356s0.osd49- "extra_reqids": [],
3.356s0.osd49- "mtime": "2022-03-07T17:48:21.189924+0800",
3.356s0.osd49- "return_code": 0,
3.356s0.osd49- "mod_desc": {
3.356s0.osd49- "object_mod_desc": {
3.356s0.osd49- "can_local_rollback": true,
3.356s0.osd49- "rollback_info_completed": false,
3.356s0.osd49- "ops": [
3.356s0.osd49- {
3.356s0.osd49- "code": "SETATTRS",
3.356s0.osd49- "attrs": [
3.356s0.osd49- "_",
3.356s0.osd49- "hinfo_key",
3.356s0.osd49- "snapset"
3.356s0.osd49- ]
3.356s0.osd49- },
3.356s0.osd49- {
3.356s0.osd49- "code": "ROLLBACK_EXTENTS",
3.356s0.osd49- "gen": 7110,
3.356s0.osd49- "snaps": "[262144,262144]"
3.356s0.osd49- }
3.356s0.osd49- ]
3.356s0.osd49- }
3.356s0.osd49- },
3.356s0.osd49- "clean_regions": {
3.356s0.osd49- "object_clean_regions": {
3.356s0.osd49- "clean_offsets": "[0~1048576,2097152~18446744073707454463]",
3.356s0.osd49- "clean_omap": true,
3.356s0.osd49- "new_object": false
3.356s0.osd49- }
3.356s0.osd49- }
3.356s0.osd49- },
3.356s1.osd44- "missing": [
3.356s1.osd44- {
3.356s1.osd44: "object": "3:6ac67c21:::202000000034931.0000001a:head",
3.356s1.osd44- "need": "1715'7110",
3.356s1.osd44- "have": "1711'7107",
3.356s1.osd44- "flags": "none",
3.356s1.osd44- "clean_regions": "clean_offsets: [0~1048576,4194304~18446744073705357311], clean_omap: 1, new_object: 0"
3.356s1.osd44- }
3.356s1.osd44- ],
3.356s2.osd47- "missing": [
3.356s2.osd47- {
3.356s2.osd47: "object": "3:6ac67c21:::202000000034931.0000001a:head",
3.356s2.osd47- "need": "1715'7110",
3.356s2.osd47- "have": "1715'7109",
3.356s2.osd47- "flags": "none",
3.356s2.osd47- "clean_regions": "clean_offsets: [0~1048576,2097152~18446744073707454463], clean_omap: 1, new_object: 0"
3.356s2.osd47- }
3.356s2.osd47- ],
3.356s3.osd18- {
3.356s3.osd18- "op": "modify",
3.356s3.osd18: "object": "3:6ac67c21:::202000000034931.0000001a:head",
3.356s3.osd18- "version": "1715'7110",
3.356s3.osd18- "prior_version": "1715'7109",
3.356s3.osd18- "reqid": "client.9726451.0:535148",
3.356s3.osd18- "extra_reqids": [],
3.356s3.osd18- "mtime": "2022-03-07T17:48:21.189924+0800",
3.356s3.osd18- "return_code": 0,
3.356s3.osd18- "mod_desc": {
3.356s3.osd18- "object_mod_desc": {
3.356s3.osd18- "can_local_rollback": true,
3.356s3.osd18- "rollback_info_completed": false,
3.356s3.osd18- "ops": [
3.356s3.osd18- {
3.356s3.osd18- "code": "SETATTRS",
3.356s3.osd18- "attrs": [
3.356s3.osd18- "_",
3.356s3.osd18- "hinfo_key",
3.356s3.osd18- "snapset"
3.356s3.osd18- ]
3.356s3.osd18- },
3.356s3.osd18- {
3.356s3.osd18- "code": "ROLLBACK_EXTENTS",
3.356s3.osd18- "gen": 7110,
3.356s3.osd18- "snaps": "[262144,262144]"
3.356s3.osd18- }
3.356s3.osd18- ]
3.356s3.osd18- }
3.356s3.osd18- },
3.356s3.osd18- "clean_regions": {
3.356s3.osd18- "object_clean_regions": {
3.356s3.osd18- "clean_offsets": "[0~1048576,2097152~18446744073707454463]",
3.356s3.osd18- "clean_omap": true,
3.356s3.osd18- "new_object": false
3.356s3.osd18- }
3.356s3.osd18- }
3.356s3.osd18- },
3.356s4.osd14- "missing": [
3.356s4.osd14- {
3.356s4.osd14: "object": "3:6ac67c21:::202000000034931.0000001a:head",
3.356s4.osd14- "need": "1715'7110",
3.356s4.osd14- "have": "1711'7107",
3.356s4.osd14- "flags": "none",
3.356s4.osd14- "clean_regions": "clean_offsets: [0~1048576,4194304~18446744073705357311], clean_omap: 1, new_object: 0"
3.356s4.osd14- }
3.356s4.osd14- ],
3.356s5.osd31- {
3.356s5.osd31- "op": "modify",
3.356s5.osd31: "object": "3:6ac67c21:::202000000034931.0000001a:head",
3.356s5.osd31- "version": "1715'7110",
3.356s5.osd31- "prior_version": "1715'7109",
3.356s5.osd31- "reqid": "client.9726451.0:535148",
3.356s5.osd31- "extra_reqids": [],
3.356s5.osd31- "mtime": "2022-03-07T17:48:21.189924+0800",
3.356s5.osd31- "return_code": 0,
3.356s5.osd31- "mod_desc": {
3.356s5.osd31- "object_mod_desc": {
3.356s5.osd31- "can_local_rollback": true,
3.356s5.osd31- "rollback_info_completed": false,
3.356s5.osd31- "ops": [
3.356s5.osd31- {
3.356s5.osd31- "code": "SETATTRS",
3.356s5.osd31- "attrs": [
3.356s5.osd31- "_",
3.356s5.osd31- "hinfo_key",
3.356s5.osd31- "snapset"
3.356s5.osd31- ]
3.356s5.osd31- },
3.356s5.osd31- {
3.356s5.osd31- "code": "ROLLBACK_EXTENTS",
3.356s5.osd31- "gen": 7110,
3.356s5.osd31- "snaps": "[262144,262144]"
3.356s5.osd31- }
3.356s5.osd31- ]
3.356s5.osd31- }
3.356s5.osd31- },
3.356s5.osd31- "clean_regions": {
3.356s5.osd31- "object_clean_regions": {
3.356s5.osd31- "clean_offsets": "[0~1048576,2097152~18446744073707454463]",
3.356s5.osd31- "clean_omap": true,
3.356s5.osd31- "new_object": false
3.356s5.osd31- }
3.356s5.osd31- }
3.356s5.osd31- },
the rados retry the same op
[root@node1 ceph]# ceph daemon /var/run/ceph/client-962242-94691926095688.asok objecter_requests
{
"ops": [
{
"tid": 587660,
"pg": "3.843e6356",
"osd": 49,
"object_id": "202000000034931.0000001a",
"object_locator": "3",-1] in=1048576b"
"target_object_id": "202000000034931.0000001a",
"target_object_locator": "@3",
"paused": 0,
"used_replica": 0,
"precalc_pgid": 0,
"last_sent": "0.000000s",
"age": 92909.956575136996,
"attempts": 0,
"snapid": "head",
"snap_context": "1=[]",
"mtime": "2022-03-07T17:48:21.189924+0800",
"osd_ops": [
"write 1048576~1048576 [1
]
}
],
"linger_ops": [],
"pool_ops": [],
"pool_stat_ops": [],
"statfs_ops": [],
"command_ops": []
}
The write(1715'7110) doest not callback to rados-client, the rados-client still retrying the same op(1715'7110),
so the write(1715'7110) op is not successful for the client.
The question now is:
(1) 1715'7110 can not revert to 1715'7109;
(2) rados-client retry the same op 1715'7110 and found the object is unfound, can not exec;
(3) pg recovery process found only s0/3/5 (1715'7110) three ec shard data, can not statisfy ec(4+2) k=4, so recovery_unfound
I think s0/3/5 should revert write(1715'7110) to 1715'7109, and then rados-client retry the same op(1715'7110).
But the pg and ec not revert. It should revert.
Updated by jianwei zhang about 2 years ago
According to the current abnormal case, is it possible to suspect that ec cannot guarantee its own consistency?
Updated by jianwei zhang about 2 years ago
ceph pg 3.356 mark_unfound_lost revert
this command is not support for ec.
so ec must guarantee its own consistency.
I think this is a problem.
ceph v15.2.13
Updated by jianwei zhang about 2 years ago
cluster:
id: 580bd632-9cfe-11ec-bf2f-0894efa5feb2
health: HEALTH_ERR
1/3984 objects unfound (0.025%)
Possible data damage: 1 pg recovery_unfound
Degraded data redundancy: 3/21411 objects degraded (0.014%), 1 pg degraded
services:
mon: 3 daemons, quorum a,b,c (age 16h)
mgr: c(active, since 26h), standbys: b, a
tfsmds: tfs
3 daemons: 3 up
c = up:running
a = up:running
b = up:running
6 ranks
6 up:active
osd: 52 osds: 52 up (since 16h), 52 in (since 46h)
data:
pools: 8 pools, 2305 pgs
objects: 3.98k objects, 14 GiB
usage: 2.1 TiB used, 104 TiB / 106 TiB avail
pgs: 3/21411 objects degraded (0.014%)
1/3984 objects unfound (0.025%)
2304 active+clean
1 active+recovery_unfound+degraded
the all osds is up&in, so the case doesn't involve recovery_unfound due to osd down.
{
"snap_trimq": "[]",
"snap_trimq_len": 0,
"state": "active+recovery_unfound+degraded",
"epoch": 1786,
"up": [
49,
44,
47,
18,
14,
31
],
"acting": [
49,
44,
47,
18,
14,
31
],
"acting_recovery_backfill": [
"14(4)",
"18(3)",
"31(5)",
"44(1)",
"47(2)",
"49(0)"
],
"info": {
"pgid": "3.356s0",
"last_update": "1734'7141",
"last_complete": "1734'7141",
"log_tail": "1437'5676",
"last_user_version": 7141,
"last_backfill": "MAX",
"purged_snaps": [],
"history": {
"epoch_created": 206,
"epoch_pool_created": 206,
"last_epoch_started": 1734,
"last_interval_started": 1733,
"last_epoch_clean": 1709,
"last_interval_clean": 1706,
"last_epoch_split": 0,
"last_epoch_marked_full": 0,
"same_up_since": 1733,
"same_interval_since": 1733,
"same_primary_since": 1656,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"prior_readable_until_ub": 0
},
"stats": {
"version": "1734'7141",
"reported_seq": "14623",
"reported_epoch": "1786",
"state": "active+recovery_unfound+degraded",
"last_fresh": "2022-03-08T10:03:25.888704+0800",
"last_change": "2022-03-07T17:50:02.468137+0800",
"last_active": "2022-03-08T10:03:25.888704+0800",
"last_peered": "2022-03-08T10:03:25.888704+0800",
"last_clean": "2022-03-07T17:47:39.874675+0800",
"last_became_active": "2022-03-07T17:50:02.077068+0800",
"last_became_peered": "2022-03-07T17:50:02.077068+0800",
"last_unstale": "2022-03-08T10:03:25.888704+0800",
"last_undegraded": "2022-03-07T17:50:01.930857+0800",
"last_fullsized": "2022-03-08T10:03:25.888704+0800",
"mapping_epoch": 1733,
"log_start": "1437'5676",
"ondisk_log_start": "1437'5676",
"created": 206,
"last_epoch_clean": 1709,
"parent": "0.0",
"parent_split_bits": 0,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"log_size": 1465,
"ondisk_log_size": 1465,
"stats_invalid": false,
"dirty_stats_invalid": false,
"omap_stats_invalid": false,
"hitset_stats_invalid": false,
"hitset_bytes_stats_invalid": false,
"pin_stats_invalid": false,
"manifest_stats_invalid": false,
"snaptrimq_len": 0,
"stat_sum": {
"num_bytes": 29360128,
"num_objects": 7,
"num_object_clones": 0,
"num_object_copies": 42,
"num_objects_missing_on_primary": 0,
"num_objects_missing": 0,
"num_objects_degraded": 3,
"num_objects_misplaced": 0,
"num_objects_unfound": 1,
"num_objects_dirty": 7,
"num_whiteouts": 0,
"num_read": 5435,
"num_read_kb": 5552905,
"num_write": 7136,
"num_write_kb": 6566917,
"num_scrub_errors": 0,
"num_shallow_scrub_errors": 0,
"num_deep_scrub_errors": 0,
"num_objects_recovered": 154,
"num_bytes_recovered": 553648435,
"num_keys_recovered": 0,
"num_objects_omap": 0,
"num_objects_hit_set_archive": 0,
"num_bytes_hit_set_archive": 0,
"num_flush": 0,
"num_flush_kb": 0,
"num_evict": 0,
"num_evict_kb": 0,
"num_promote": 0,
"num_flush_mode_high": 0,
"num_flush_mode_low": 0,
"num_evict_mode_some": 0,
"num_evict_mode_full": 0,
"num_objects_pinned": 0,
"num_legacy_snapsets": 0,
"num_large_omap_objects": 0,
"num_objects_manifest": 0,
"num_omap_bytes": 0,
"num_omap_keys": 0,
"num_objects_repaired": 0
},
"up": [
49,
44,
47,
18,
14,
31
],
"acting": [
49,
44,
47,
18,
14,
31
],
"avail_no_missing": [
"49(0)",
"18(3)",
"31(5)"
],
"object_location_counts": [
{
"shards": "14(4),18(3),31(5),44(1),47(2),49(0)",
"objects": 6
},
{
"shards": "18(3),31(5),49(0)",
"objects": 1
}
],
"blocked_by": [],
"up_primary": 49,
"acting_primary": 49,
"purged_snaps": []
},
"empty": 0,
"dne": 0,
"incomplete": 0,
"last_epoch_started": 1734,
"hit_set_history": {
"current_last_update": "0'0",
"history": []
}
},
"peer_info": [
{
"peer": "14(4)",
"pgid": "3.356s4",
"last_update": "1734'7141",
"last_complete": "1715'7109",
"log_tail": "1437'5676",
"last_user_version": 7113,
"last_backfill": "MAX",
"purged_snaps": [],
"history": {
"epoch_created": 206,
"epoch_pool_created": 206,
"last_epoch_started": 1734,
"last_interval_started": 1733,
"last_epoch_clean": 1709,
"last_interval_clean": 1706,
"last_epoch_split": 0,
"last_epoch_marked_full": 0,
"same_up_since": 1733,
"same_interval_since": 1733,
"same_primary_since": 1656,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"prior_readable_until_ub": 0
},
"stats": {
"version": "1725'7113",
"reported_seq": "14476",
"reported_epoch": "1731",
"state": "peering",
"last_fresh": "2022-03-07T17:49:40.965850+0800",
"last_change": "2022-03-07T17:49:39.969546+0800",
"last_active": "2022-03-07T17:49:39.969170+0800",
"last_peered": "2022-03-07T17:49:38.911597+0800",
"last_clean": "2022-03-07T17:47:39.874675+0800",
"last_became_active": "2022-03-07T17:49:22.360495+0800",
"last_became_peered": "2022-03-07T17:49:22.360495+0800",
"last_unstale": "2022-03-07T17:49:40.965850+0800",
"last_undegraded": "2022-03-07T17:49:40.965850+0800",
"last_fullsized": "2022-03-07T17:49:40.965850+0800",
"mapping_epoch": 1733,
"log_start": "1437'5676",
"ondisk_log_start": "1437'5676",
"created": 206,
"last_epoch_clean": 1709,
"parent": "0.0",
"parent_split_bits": 0,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"log_size": 1437,
"ondisk_log_size": 1437,
"stats_invalid": false,
"dirty_stats_invalid": false,
"omap_stats_invalid": false,
"hitset_stats_invalid": false,
"hitset_bytes_stats_invalid": false,
"pin_stats_invalid": false,
"manifest_stats_invalid": false,
"snaptrimq_len": 0,
"stat_sum": {
"num_bytes": 37748736,
"num_objects": 9,
"num_object_clones": 0,
"num_object_copies": 54,
"num_objects_missing_on_primary": 0,
"num_objects_missing": 1,
"num_objects_degraded": 0,
"num_objects_misplaced": 0,
"num_objects_unfound": 0,
"num_objects_dirty": 9,
"num_whiteouts": 0,
"num_read": 5401,
"num_read_kb": 5518089,
"num_write": 7108,
"num_write_kb": 6540293,
"num_scrub_errors": 0,
"num_shallow_scrub_errors": 0,
"num_deep_scrub_errors": 0,
"num_objects_recovered": 151,
"num_bytes_recovered": 541065523,
"num_keys_recovered": 0,
"num_objects_omap": 0,
"num_objects_hit_set_archive": 0,
"num_bytes_hit_set_archive": 0,
"num_flush": 0,
"num_flush_kb": 0,
"num_evict": 0,
"num_evict_kb": 0,
"num_promote": 0,
"num_flush_mode_high": 0,
"num_flush_mode_low": 0,
"num_evict_mode_some": 0,
"num_evict_mode_full": 0,
"num_objects_pinned": 0,
"num_legacy_snapsets": 0,
"num_large_omap_objects": 0,
"num_objects_manifest": 0,
"num_omap_bytes": 0,
"num_omap_keys": 0,
"num_objects_repaired": 0
},
"up": [
49,
44,
47,
18,
14,
31
],
"acting": [
49,
44,
47,
18,
14,
31
],
"avail_no_missing": [],
"object_location_counts": [],
"blocked_by": [],
"up_primary": 49,
"acting_primary": 49,
"purged_snaps": []
},
"empty": 0,
"dne": 0,
"incomplete": 0,
"last_epoch_started": 1734,
"hit_set_history": {
"current_last_update": "0'0",
"history": []
}
},
{
"peer": "18(3)",
"pgid": "3.356s3",
"last_update": "1734'7141",
"last_complete": "1734'7141",
"log_tail": "1437'5676",
"last_user_version": 7113,
"last_backfill": "MAX",
"purged_snaps": [],
"history": {
"epoch_created": 206,
"epoch_pool_created": 206,
"last_epoch_started": 1734,
"last_interval_started": 1733,
"last_epoch_clean": 1709,
"last_interval_clean": 1706,
"last_epoch_split": 0,
"last_epoch_marked_full": 0,
"same_up_since": 1733,
"same_interval_since": 1733,
"same_primary_since": 1656,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"prior_readable_until_ub": 0
},
"stats": {
"version": "1725'7113",
"reported_seq": "14456",
"reported_epoch": "1725",
"state": "active+recovery_unfound+undersized+degraded",
"last_fresh": "2022-03-07T17:49:07.918710+0800",
"last_change": "2022-03-07T17:49:05.876531+0800",
"last_active": "2022-03-07T17:49:07.918710+0800",
"last_peered": "2022-03-07T17:49:07.918710+0800",
"last_clean": "2022-03-07T17:47:39.874675+0800",
"last_became_active": "2022-03-07T17:49:05.435242+0800",
"last_became_peered": "2022-03-07T17:49:05.435242+0800",
"last_unstale": "2022-03-07T17:49:07.918710+0800",
"last_undegraded": "2022-03-07T17:49:05.289185+0800",
"last_fullsized": "2022-03-07T17:49:05.281151+0800",
"mapping_epoch": 1733,
"log_start": "1437'5676",
"ondisk_log_start": "1437'5676",
"created": 206,
"last_epoch_clean": 1709,
"parent": "0.0",
"parent_split_bits": 0,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"log_size": 1437,
"ondisk_log_size": 1437,
"stats_invalid": false,
"dirty_stats_invalid": false,
"omap_stats_invalid": false,
"hitset_stats_invalid": false,
"hitset_bytes_stats_invalid": false,
"pin_stats_invalid": false,
"manifest_stats_invalid": false,
"snaptrimq_len": 0,
"stat_sum": {
"num_bytes": 37748736,
"num_objects": 9,
"num_object_clones": 0,
"num_object_copies": 54,
"num_objects_missing_on_primary": 0,
"num_objects_missing": 0,
"num_objects_degraded": 20,
"num_objects_misplaced": 0,
"num_objects_unfound": 2,
"num_objects_dirty": 9,
"num_whiteouts": 0,
"num_read": 5400,
"num_read_kb": 5517065,
"num_write": 7108,
"num_write_kb": 6540293,
"num_scrub_errors": 0,
"num_shallow_scrub_errors": 0,
"num_deep_scrub_errors": 0,
"num_objects_recovered": 151,
"num_bytes_recovered": 541065523,
"num_keys_recovered": 0,
"num_objects_omap": 0,
"num_objects_hit_set_archive": 0,
"num_bytes_hit_set_archive": 0,
"num_flush": 0,
"num_flush_kb": 0,
"num_evict": 0,
"num_evict_kb": 0,
"num_promote": 0,
"num_flush_mode_high": 0,
"num_flush_mode_low": 0,
"num_evict_mode_some": 0,
"num_evict_mode_full": 0,
"num_objects_pinned": 0,
"num_legacy_snapsets": 0,
"num_large_omap_objects": 0,
"num_objects_manifest": 0,
"num_omap_bytes": 0,
"num_omap_keys": 0,
"num_objects_repaired": 0
},
"up": [
49,
44,
47,
18,
14,
31
],
"acting": [
49,
44,
47,
18,
14,
31
],
"avail_no_missing": [
"49(0)",
"18(3)",
"31(5)"
],
"object_location_counts": [
{
"shards": "18(3),31(5),44(1),49(0)",
"objects": 7
},
{
"shards": "18(3),31(5),49(0)",
"objects": 2
}
],
"blocked_by": [],
"up_primary": 49,
"acting_primary": 49,
"purged_snaps": []
},
"empty": 0,
"dne": 0,
"incomplete": 0,
"last_epoch_started": 1734,
"hit_set_history": {
"current_last_update": "0'0",
"history": []
}
},
{
"peer": "31(5)",
"pgid": "3.356s5",
"last_update": "1734'7141",
"last_complete": "1734'7141",
"log_tail": "1437'5676",
"last_user_version": 7113,
"last_backfill": "MAX",
"purged_snaps": [],
"history": {
"epoch_created": 206,
"epoch_pool_created": 206,
"last_epoch_started": 1734,
"last_interval_started": 1733,
"last_epoch_clean": 1709,
"last_interval_clean": 1706,
"last_epoch_split": 0,
"last_epoch_marked_full": 0,
"same_up_since": 1733,
"same_interval_since": 1733,
"same_primary_since": 1656,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"prior_readable_until_ub": 0
},
"stats": {
"version": "1725'7113",
"reported_seq": "14456",
"reported_epoch": "1725",
"state": "active+recovery_unfound+undersized+degraded",
"last_fresh": "2022-03-07T17:49:07.918710+0800",
"last_change": "2022-03-07T17:49:05.876531+0800",
"last_active": "2022-03-07T17:49:07.918710+0800",
"last_peered": "2022-03-07T17:49:07.918710+0800",
"last_clean": "2022-03-07T17:47:39.874675+0800",
"last_became_active": "2022-03-07T17:49:05.435242+0800",
"last_became_peered": "2022-03-07T17:49:05.435242+0800",
"last_unstale": "2022-03-07T17:49:07.918710+0800",
"last_undegraded": "2022-03-07T17:49:05.289185+0800",
"last_fullsized": "2022-03-07T17:49:05.281151+0800",
"mapping_epoch": 1733,
"log_start": "1437'5676",
"ondisk_log_start": "1437'5676",
"created": 206,
"last_epoch_clean": 1709,
"parent": "0.0",
"parent_split_bits": 0,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"log_size": 1437,
"ondisk_log_size": 1437,
"stats_invalid": false,
"dirty_stats_invalid": false,
"omap_stats_invalid": false,
"hitset_stats_invalid": false,
"hitset_bytes_stats_invalid": false,
"pin_stats_invalid": false,
"manifest_stats_invalid": false,
"snaptrimq_len": 0,
"stat_sum": {
"num_bytes": 37748736,
"num_objects": 9,
"num_object_clones": 0,
"num_object_copies": 54,
"num_objects_missing_on_primary": 0,
"num_objects_missing": 0,
"num_objects_degraded": 20,
"num_objects_misplaced": 0,
"num_objects_unfound": 2,
"num_objects_dirty": 9,
"num_whiteouts": 0,
"num_read": 5400,
"num_read_kb": 5517065,
"num_write": 7108,
"num_write_kb": 6540293,
"num_scrub_errors": 0,
"num_shallow_scrub_errors": 0,
"num_deep_scrub_errors": 0,
"num_objects_recovered": 151,
"num_bytes_recovered": 541065523,
"num_keys_recovered": 0,
"num_objects_omap": 0,
"num_objects_hit_set_archive": 0,
"num_bytes_hit_set_archive": 0,
"num_flush": 0,
"num_flush_kb": 0,
"num_evict": 0,
"num_evict_kb": 0,
"num_promote": 0,
"num_flush_mode_high": 0,
"num_flush_mode_low": 0,
"num_evict_mode_some": 0,
"num_evict_mode_full": 0,
"num_objects_pinned": 0,
"num_legacy_snapsets": 0,
"num_large_omap_objects": 0,
"num_objects_manifest": 0,
"num_omap_bytes": 0,
"num_omap_keys": 0,
"num_objects_repaired": 0
},
"up": [
49,
44,
47,
18,
14,
31
],
"acting": [
49,
44,
47,
18,
14,
31
],
"avail_no_missing": [
"49(0)",
"18(3)",
"31(5)"
],
"object_location_counts": [
{
"shards": "18(3),31(5),44(1),49(0)",
"objects": 7
},
{
"shards": "18(3),31(5),49(0)",
"objects": 2
}
],
"blocked_by": [],
"up_primary": 49,
"acting_primary": 49,
"purged_snaps": []
},
"empty": 0,
"dne": 0,
"incomplete": 0,
"last_epoch_started": 1734,
"hit_set_history": {
"current_last_update": "0'0",
"history": []
}
},
{
"peer": "44(1)",
"pgid": "3.356s1",
"last_update": "1734'7141",
"last_complete": "1715'7109",
"log_tail": "1437'5676",
"last_user_version": 7113,
"last_backfill": "MAX",
"purged_snaps": [],
"history": {
"epoch_created": 206,
"epoch_pool_created": 206,
"last_epoch_started": 1734,
"last_interval_started": 1733,
"last_epoch_clean": 1709,
"last_interval_clean": 1706,
"last_epoch_split": 0,
"last_epoch_marked_full": 0,
"same_up_since": 1733,
"same_interval_since": 1733,
"same_primary_since": 1656,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"prior_readable_until_ub": 0
},
"stats": {
"version": "1725'7113",
"reported_seq": "14456",
"reported_epoch": "1725",
"state": "active+recovery_unfound+undersized+degraded",
"last_fresh": "2022-03-07T17:49:07.918710+0800",
"last_change": "2022-03-07T17:49:05.876531+0800",
"last_active": "2022-03-07T17:49:07.918710+0800",
"last_peered": "2022-03-07T17:49:07.918710+0800",
"last_clean": "2022-03-07T17:47:39.874675+0800",
"last_became_active": "2022-03-07T17:49:05.435242+0800",
"last_became_peered": "2022-03-07T17:49:05.435242+0800",
"last_unstale": "2022-03-07T17:49:07.918710+0800",
"last_undegraded": "2022-03-07T17:49:05.289185+0800",
"last_fullsized": "2022-03-07T17:49:05.281151+0800",
"mapping_epoch": 1733,
"log_start": "1437'5676",
"ondisk_log_start": "1437'5676",
"created": 206,
"last_epoch_clean": 1709,
"parent": "0.0",
"parent_split_bits": 0,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"log_size": 1437,
"ondisk_log_size": 1437,
"stats_invalid": false,
"dirty_stats_invalid": false,
"omap_stats_invalid": false,
"hitset_stats_invalid": false,
"hitset_bytes_stats_invalid": false,
"pin_stats_invalid": false,
"manifest_stats_invalid": false,
"snaptrimq_len": 0,
"stat_sum": {
"num_bytes": 37748736,
"num_objects": 9,
"num_object_clones": 0,
"num_object_copies": 54,
"num_objects_missing_on_primary": 0,
"num_objects_missing": 1,
"num_objects_degraded": 20,
"num_objects_misplaced": 0,
"num_objects_unfound": 2,
"num_objects_dirty": 9,
"num_whiteouts": 0,
"num_read": 5400,
"num_read_kb": 5517065,
"num_write": 7108,
"num_write_kb": 6540293,
"num_scrub_errors": 0,
"num_shallow_scrub_errors": 0,
"num_deep_scrub_errors": 0,
"num_objects_recovered": 151,
"num_bytes_recovered": 541065523,
"num_keys_recovered": 0,
"num_objects_omap": 0,
"num_objects_hit_set_archive": 0,
"num_bytes_hit_set_archive": 0,
"num_flush": 0,
"num_flush_kb": 0,
"num_evict": 0,
"num_evict_kb": 0,
"num_promote": 0,
"num_flush_mode_high": 0,
"num_flush_mode_low": 0,
"num_evict_mode_some": 0,
"num_evict_mode_full": 0,
"num_objects_pinned": 0,
"num_legacy_snapsets": 0,
"num_large_omap_objects": 0,
"num_objects_manifest": 0,
"num_omap_bytes": 0,
"num_omap_keys": 0,
"num_objects_repaired": 0
},
"up": [
49,
44,
47,
18,
14,
31
],
"acting": [
49,
44,
47,
18,
14,
31
],
"avail_no_missing": [
"49(0)",
"18(3)",
"31(5)"
],
"object_location_counts": [
{
"shards": "18(3),31(5),44(1),49(0)",
"objects": 7
},
{
"shards": "18(3),31(5),49(0)",
"objects": 2
}
],
"blocked_by": [],
"up_primary": 49,
"acting_primary": 49,
"purged_snaps": []
},
"empty": 0,
"dne": 0,
"incomplete": 0,
"last_epoch_started": 1734,
"hit_set_history": {
"current_last_update": "0'0",
"history": []
}
},
{
"peer": "47(2)",
"pgid": "3.356s2",
"last_update": "1734'7141",
"last_complete": "1715'7109",
"log_tail": "1437'5676",
"last_user_version": 7113,
"last_backfill": "MAX",
"purged_snaps": [],
"history": {
"epoch_created": 206,
"epoch_pool_created": 206,
"last_epoch_started": 1734,
"last_interval_started": 1733,
"last_epoch_clean": 1709,
"last_interval_clean": 1706,
"last_epoch_split": 0,
"last_epoch_marked_full": 0,
"same_up_since": 1733,
"same_interval_since": 1733,
"same_primary_since": 1656,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"prior_readable_until_ub": 0
},
"stats": {
"version": "1725'7113",
"reported_seq": "14462",
"reported_epoch": "1728",
"state": "peering",
"last_fresh": "2022-03-07T17:49:22.186176+0800",
"last_change": "2022-03-07T17:49:21.167187+0800",
"last_active": "2022-03-07T17:49:21.162136+0800",
"last_peered": "2022-03-07T17:49:21.055205+0800",
"last_clean": "2022-03-07T17:47:39.874675+0800",
"last_became_active": "2022-03-07T17:49:05.435242+0800",
"last_became_peered": "2022-03-07T17:49:05.435242+0800",
"last_unstale": "2022-03-07T17:49:22.186176+0800",
"last_undegraded": "2022-03-07T17:49:22.186176+0800",
"last_fullsized": "2022-03-07T17:49:22.186176+0800",
"mapping_epoch": 1733,
"log_start": "1437'5676",
"ondisk_log_start": "1437'5676",
"created": 206,
"last_epoch_clean": 1709,
"parent": "0.0",
"parent_split_bits": 0,
"last_scrub": "0'0",
"last_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_deep_scrub": "0'0",
"last_deep_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"last_clean_scrub_stamp": "2022-03-06T11:40:37.231334+0800",
"log_size": 1437,
"ondisk_log_size": 1437,
"stats_invalid": false,
"dirty_stats_invalid": false,
"omap_stats_invalid": false,
"hitset_stats_invalid": false,
"hitset_bytes_stats_invalid": false,
"pin_stats_invalid": false,
"manifest_stats_invalid": false,
"snaptrimq_len": 0,
"stat_sum": {
"num_bytes": 37748736,
"num_objects": 9,
"num_object_clones": 0,
"num_object_copies": 54,
"num_objects_missing_on_primary": 0,
"num_objects_missing": 1,
"num_objects_degraded": 0,
"num_objects_misplaced": 0,
"num_objects_unfound": 0,
"num_objects_dirty": 9,
"num_whiteouts": 0,
"num_read": 5401,
"num_read_kb": 5518089,
"num_write": 7108,
"num_write_kb": 6540293,
"num_scrub_errors": 0,
"num_shallow_scrub_errors": 0,
"num_deep_scrub_errors": 0,
"num_objects_recovered": 151,
"num_bytes_recovered": 541065523,
"num_keys_recovered": 0,
"num_objects_omap": 0,
"num_objects_hit_set_archive": 0,
"num_bytes_hit_set_archive": 0,
"num_flush": 0,
"num_flush_kb": 0,
"num_evict": 0,
"num_evict_kb": 0,
"num_promote": 0,
"num_flush_mode_high": 0,
"num_flush_mode_low": 0,
"num_evict_mode_some": 0,
"num_evict_mode_full": 0,
"num_objects_pinned": 0,
"num_legacy_snapsets": 0,
"num_large_omap_objects": 0,
"num_objects_manifest": 0,
"num_omap_bytes": 0,
"num_omap_keys": 0,
"num_objects_repaired": 0
},
"up": [
49,
44,
47,
18,
14,
31
],
"acting": [
49,
44,
47,
18,
14,
31
],
"avail_no_missing": [],
"object_location_counts": [],
"blocked_by": [],
"up_primary": 49,
"acting_primary": 49,
"purged_snaps": []
},
"empty": 0,
"dne": 0,
"incomplete": 0,
"last_epoch_started": 1734,
"hit_set_history": {
"current_last_update": "0'0",
"history": []
}
}
],
"recovery_state": [
{
"name": "Started/Primary/Active",
"enter_time": "2022-03-07T17:50:01.930326+0800",
"might_have_unfound": [
{
"osd": "14(4)",
"status": "already probed"
},
{
"osd": "18(3)",
"status": "already probed"
},
{
"osd": "31(5)",
"status": "already probed"
},
{
"osd": "44(1)",
"status": "already probed"
},
{
"osd": "47(2)",
"status": "already probed"
}
],
"recovery_progress": {
"backfill_targets": [],
"waiting_on_backfill": [],
"last_backfill_started": "MIN",
"backfill_info": {
"begin": "MIN",
"end": "MIN",
"objects": []
},
"peer_backfill_info": [],
"backfills_in_flight": [],
"recovering": [],
"pg_backend": {
"recovery_ops": [],
"read_ops": []
}
}
},
{
"name": "Started",
"enter_time": "2022-03-07T17:50:00.930143+0800"
},
{
"scrubber.epoch_start": "0",
"scrubber.active": false,
"scrubber.state": "INACTIVE",
"scrubber.start": "MIN",
"scrubber.end": "MIN",
"scrubber.max_end": "MIN",
"scrubber.subset_last_update": "0'0",
"scrubber.deep": false,
"scrubber.waiting_on_whom": []
}
],
"agent_state": {}
}
Updated by Radoslaw Zarzynski about 2 years ago
the all osds is up&in, so the case doesn't involve recovery_unfound due to osd down.
A note from the bug scrub: this looks confusing. In the comment #22 a following info can be found:
osd.44 s1 : have 1711'7107 missing 1715'7110 ###osd.44(s1) dead due to coredump osd.47 s2 : have 1715'7109 missing 1715'7110 ###osd.47(s2) dead due to coredump, osd.18 s3 : have 1715'7110 ###osd.18(s3) write 1715'7110 success osd.14 s4 : have 1711'7107 missing 1715'7110 ###osd.14(s4) dead due to coredump
which would mean that, at least for some time, 3 OSDs were down and this is enough to cause the issue.
Anyway, there is no another thing we can use to double check: the can_rollback_to (aka. crt in the logs) value which is present in a log entry. Here is an example:
2022-03-29T15:41:03.577+0000 7f3572af1700 1 osd.0 pg_epoch: 7 pg[1.0( empty local-lis/les=0/0 n=0 ec=7/7 lis/c=0/0 les/c/f=0/0/0 sis=7) [0] r=0 lpr=7 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
Could you please provide similar entries for the affected PG?
Updated by jianwei zhang about 2 years ago
Radoslaw Zarzynski wrote:
the all osds is up&in, so the case doesn't involve recovery_unfound due to osd down.
A note from the bug scrub: this looks confusing. In the comment #22 a following info can be found:
[...]
which would mean that, at least for some time, 3 OSDs were down and this is enough to cause the issue.
Anyway, there is no another thing we can use to double check: the
can_rollback_to(aka.crtin the logs) value which is present in a log entry. Here is an example:[...]
Could you please provide similar entries for the affected PG?
[root@jianwei 10.128.130.71]# zcat ./host-log-node1/ceph/ceph-osd.49.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
2022-03-06T11:40:37.494+0800 7f911213d700 1 osd.49 pg_epoch: 206 pg[3.356s0( empty local-lis/les=0/0 n=0 ec=206/206 lis/c=0/0 les/c/f=0/0/0 sis=206) [49,44,47,22,14,1]p49(0) r=0 lpr=206 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T11:43:20.351+0800 7f910f938700 1 osd.49 pg_epoch: 237 pg[3.356s0( empty local-lis/les=206/207 n=0 ec=206/206 lis/c=206/206 les/c/f=207/207/0 sis=237 pruub=14.234196274s) [49,44,47,18,14,22]p49(0) r=0 lpr=237 pi=[206,237)/1 crt=0'0 mlcod 0'0 unknown pruub 389.257391117s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T11:44:16.610+0800 7f9114942700 1 osd.49 pg_epoch: 248 pg[3.356s0( empty local-lis/les=237/238 n=0 ec=206/206 lis/c=237/237 les/c/f=238/238/0 sis=248 pruub=8.653028340s) [49,44,47,18,14,31]p49(0) r=0 lpr=248 pi=[237,248)/1 crt=0'0 mlcod 0'0 unknown pruub 439.934734857s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:49:24.689+0800 7f3f50f04700 1 osd.49 pg_epoch: 280 pg[3.356s0( v 279'354 (0'0,279'354] local-lis/les=248/249 n=2 ec=206/206 lis/c=248/248 les/c/f=249/249/0 sis=248) [49,44,47,18,14,31]p49(0) r=0 lpr=279 crt=279'354 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:49:25.632+0800 7f3f50f04700 1 osd.49 pg_epoch: 304 pg[3.356s0( v 279'354 (0'0,279'354] local-lis/les=248/249 n=2 ec=206/206 lis/c=248/248 les/c/f=249/249/0 sis=304) [49,44,47,18,14,31]p49(0) r=0 lpr=304 pi=[248,304)/1 crt=279'354 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primar
2022-03-06T19:59:23.698+0800 7f34b6d16700 1 osd.49 pg_epoch: 313 pg[3.356s0( v 311'433 (0'0,311'433] local-lis/les=304/305 n=0 ec=206/206 lis/c=304/304 les/c/f=305/307/0 sis=304) [49,44,47,18,14,31]p49(0) r=0 lpr=311 crt=311'433 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:59:24.767+0800 7f34b951b700 1 osd.49 pg_epoch: 325 pg[3.356s0( v 311'433 (0'0,311'433] local-lis/les=304/305 n=0 ec=206/206 lis/c=304/304 les/c/f=305/307/0 sis=325) [49,44,47,18,14,31]p49(0) r=0 lpr=325 pi=[304,325)/1 crt=311'433 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primar
2022-03-06T20:56:51.475+0800 7f34b6d16700 1 osd.49 pg_epoch: 338 pg[3.356s0( v 337'804 (0'0,337'804] local-lis/les=325/326 n=0 ec=206/206 lis/c=325/325 les/c/f=326/327/0 sis=338 pruub=2.658631698s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=338 pi=[325,338)/1 crt=337'804 lcod 337'803 mlcod 0'0 unknown pruub 3457.315769102s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:02:23.610+0800 7f34b951b700 1 osd.49 pg_epoch: 351 pg[3.356s0( v 341'834 (0'0,341'834] local-lis/les=338/339 n=6 ec=206/206 lis/c=338/325 les/c/f=339/327/0 sis=351 pruub=12.800782387s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=351 pi=[325,351)/1 crt=341'834 lcod 341'833 mlcod 0'0 unknown pruub 3799.594023791s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:02:26.883+0800 7f34b6d16700 1 osd.49 pg_epoch: 354 pg[3.356s0( v 341'834 (0'0,341'834] local-lis/les=351/352 n=6 ec=206/206 lis/c=351/325 les/c/f=352/327/0 sis=354 pruub=13.974659987s) [49,44,47,18,14,31]p49(0) r=0 lpr=354 pi=[325,354)/1 crt=341'834 lcod 341'833 mlcod 0'0 unknown pruub 3804.040910339s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:09:19.029+0800 7f34b6d16700 1 osd.49 pg_epoch: 366 pg[3.356s0( v 365'877 (0'0,365'877] local-lis/les=354/355 n=0 ec=206/206 lis/c=354/354 les/c/f=355/363/0 sis=366 pruub=2.068333896s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=366 pi=[354,366)/1 crt=365'877 lcod 365'876 mlcod 0'0 unknown pruub 4207.197962580s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:12:30.167+0800 7f34b951b700 1 osd.49 pg_epoch: 381 pg[3.356s0( v 370'909 (0'0,370'909] local-lis/les=366/367 n=5 ec=206/206 lis/c=366/354 les/c/f=367/363/0 sis=381 pruub=9.917221160s) [49,44,47,18,14,31]p49(0) r=0 lpr=381 pi=[354,381)/1 crt=370'909 lcod 370'908 mlcod 0'0 unknown pruub 4406.184422104s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:13:44.854+0800 7f34bbd20700 1 osd.49 pg_epoch: 384 pg[3.356s0( v 383'918 (0'0,383'918] local-lis/les=381/382 n=5 ec=206/206 lis/c=381/381 les/c/f=382/383/0 sis=384) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=384 pi=[381,384)/1 crt=383'918 lcod 383'917 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:17:24.918+0800 7f34bbd20700 1 osd.49 pg_epoch: 398 pg[3.356s0( v 387'935 (0'0,387'935] local-lis/les=384/385 n=0 ec=206/206 lis/c=384/381 les/c/f=385/383/0 sis=398 pruub=13.494873878s) [49,44,47,18,14,31]p49(0) r=0 lpr=398 pi=[381,398)/1 crt=387'935 lcod 387'934 mlcod 0'0 unknown pruub 4704.512605106s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T23:56:07.266+0800 7f34bbd20700 1 osd.49 pg_epoch: 407 pg[3.356s0( v 406'1684 (278'300,406'1684] local-lis/les=398/399 n=0 ec=206/206 lis/c=398/398 les/c/f=399/399/0 sis=407 pruub=0.641491637s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=407 pi=[398,407)/1 crt=406'1684 lcod 406'1683 mlcod 0'0 unknown pruub 14214.006632879s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:01:18.395+0800 7f34bbd20700 1 osd.49 pg_epoch: 432 pg[3.356s0( v 409'1719 (278'300,409'1719] local-lis/les=407/408 n=4 ec=206/206 lis/c=407/398 les/c/f=408/399/0 sis=432 pruub=10.022340130s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=432 pi=[398,432)/1 crt=409'1719 lcod 409'1718 mlcod 0'0 unknown pruub 14534.516982275s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:01:19.720+0800 7f34bbd20700 1 osd.49 pg_epoch: 434 pg[3.356s0( v 409'1719 (278'300,409'1719] local-lis/les=432/433 n=4 ec=206/206 lis/c=432/398 les/c/f=433/399/0 sis=434 pruub=15.292470442s) [49,44,47,18,14,31]p49(0) r=0 lpr=434 pi=[398,434)/1 crt=409'1719 lcod 409'1718 mlcod 0'0 unknown pruub 14541.113063906s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:07:38.561+0800 7f34b6d16700 1 osd.49 pg_epoch: 460 pg[3.356s0( v 446'1723 (278'300,446'1723] local-lis/les=434/435 n=0 ec=206/206 lis/c=434/434 les/c/f=435/443/0 sis=460) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=460 pi=[434,460)/1 crt=446'1723 lcod 446'1722 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:12:26.728+0800 7f34b6d16700 1 osd.49 pg_epoch: 464 pg[3.356s0( v 463'1727 (278'300,463'1727] local-lis/les=460/461 n=1 ec=206/206 lis/c=460/434 les/c/f=461/443/0 sis=464 pruub=8.987281720s) [49,44,47,18,14,31]p49(0) r=0 lpr=464 pi=[434,464)/1 crt=463'1727 lcod 463'1726 mlcod 0'0 unknown pruub 15201.799332984s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:48:53.143+0800 7f34b6d16700 1 osd.49 pg_epoch: 472 pg[3.356s0( v 470'1923 (336'500,470'1923] local-lis/les=464/465 n=0 ec=206/206 lis/c=464/464 les/c/f=465/470/0 sis=472) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=472 pi=[464,472)/1 crt=470'1923 lcod 470'1922 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:54:22.123+0800 7f34bbd20700 1 osd.49 pg_epoch: 492 pg[3.356s0( v 482'1968 (336'500,482'1968] local-lis/les=472/473 n=7 ec=206/206 lis/c=472/464 les/c/f=473/470/0 sis=492 pruub=8.112465254s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=492 pi=[464,492)/1 crt=482'1968 lcod 481'1967 mlcod 0'0 unknown pruub 17716.335352355s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:54:24.598+0800 7f34b951b700 1 osd.49 pg_epoch: 495 pg[3.356s0( v 482'1968 (336'500,482'1968] local-lis/les=492/493 n=7 ec=206/206 lis/c=492/464 les/c/f=493/470/0 sis=495 pruub=14.715679461s) [49,44,47,18,14,31]p49(0) r=0 lpr=495 pi=[464,495)/1 crt=482'1968 lcod 481'1967 mlcod 0'0 unknown pruub 17725.413416775s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:59:44.574+0800 7f34b951b700 1 osd.49 pg_epoch: 504 pg[3.356s0( v 501'2011 (336'600,501'2011] local-lis/les=495/496 n=0 ec=206/206 lis/c=495/495 les/c/f=496/499/0 sis=504 pruub=1.142740998s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=504 pi=[495,504)/1 crt=501'2011 lcod 501'2010 mlcod 0'0 unknown pruub 18031.816826822s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T01:04:48.209+0800 7f34bbd20700 1 osd.49 pg_epoch: 519 pg[3.356s0( v 517'2033 (336'600,517'2033] local-lis/les=504/505 n=1 ec=206/206 lis/c=504/495 les/c/f=505/499/0 sis=519 pruub=9.387994059s) [49,44,47,18,14,31]p49(0) r=0 lpr=519 pi=[495,519)/1 crt=517'2033 lcod 508'2032 mlcod 0'0 unknown pruub 18343.697681454s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T01:37:43.250+0800 7f34b951b700 1 osd.49 pg_epoch: 561 pg[3.356s0( v 551'2148 (336'700,551'2148] local-lis/les=519/520 n=0 ec=206/206 lis/c=519/519 les/c/f=520/521/0 sis=561) [49,44,47,18,14,31]p49(0) r=0 lpr=561 pi=[519,561)/1 crt=551'2148 lcod 551'2147 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:15:36.459+0800 7f34b951b700 1 osd.49 pg_epoch: 581 pg[3.356s0( v 580'2334 (370'900,580'2334] local-lis/les=561/562 n=0 ec=206/206 lis/c=561/561 les/c/f=562/573/0 sis=581 pruub=0.577405628s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=581 pi=[561,581)/1 crt=580'2334 lcod 580'2333 mlcod 0'0 unknown pruub 22583.135910195s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:19:45.846+0800 7f34b951b700 1 osd.49 pg_epoch: 603 pg[3.356s0( v 584'2342 (370'900,584'2342] local-lis/les=581/582 n=1 ec=206/206 lis/c=581/561 les/c/f=582/573/0 sis=603 pruub=15.784000584s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=603 pi=[561,603)/1 crt=584'2342 lcod 584'2341 mlcod 0'0 unknown pruub 22847.729989461s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:19:47.987+0800 7f34bbd20700 1 osd.49 pg_epoch: 605 pg[3.356s0( v 584'2342 (370'900,584'2342] local-lis/les=603/604 n=1 ec=206/206 lis/c=603/561 les/c/f=604/573/0 sis=605 pruub=15.168124659s) [49,44,47,18,14,31]p49(0) r=0 lpr=605 pi=[561,605)/1 crt=584'2342 lcod 584'2341 mlcod 0'0 unknown pruub 22849.255179360s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:26:19.496+0800 7f34bbd20700 1 osd.49 pg_epoch: 609 pg[3.356s0( v 606'2352 (370'900,606'2352] local-lis/les=605/606 n=0 ec=206/206 lis/c=605/605 les/c/f=606/606/0 sis=609) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=609 pi=[605,609)/1 crt=606'2352 lcod 606'2351 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:31:07.769+0800 7f34bbd20700 1 osd.49 pg_epoch: 612 pg[3.356s0( v 611'2410 (399'1000,611'2410] local-lis/les=609/610 n=6 ec=206/206 lis/c=609/605 les/c/f=610/606/0 sis=612 pruub=8.894910398s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=612 pi=[605,612)/1 crt=611'2410 lcod 611'2409 mlcod 0'0 unknown pruub 23522.764383257s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:31:08.641+0800 7f34bbd20700 1 osd.49 pg_epoch: 613 pg[3.356s0( v 611'2410 (399'1000,611'2410] local-lis/les=609/610 n=6 ec=206/206 lis/c=609/605 les/c/f=610/606/0 sis=613) [49,44,47,18,14,31]p49(0) r=0 lpr=613 pi=[605,613)/1 crt=611'2410 lcod 611'2409 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T03:29:39.975+0800 7f34b6d16700 1 osd.49 pg_epoch: 656 pg[3.356s0( v 655'2768 (405'1300,655'2768] local-lis/les=613/614 n=0 ec=206/206 lis/c=613/613 les/c/f=614/619/0 sis=656 pruub=2.932511832s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=656 pi=[613,656)/1 crt=655'2768 lcod 655'2767 mlcod 0'0 unknown pruub 27029.006564684s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T03:35:57.904+0800 7f34bbd20700 1 osd.49 pg_epoch: 686 pg[3.356s0( v 683'2818 (405'1400,683'2818] local-lis/les=656/657 n=7 ec=206/206 lis/c=656/613 les/c/f=657/619/0 sis=686 pruub=15.053891262s) [49,44,47,18,14,31]p49(0) r=0 lpr=686 pi=[613,686)/1 crt=683'2818 lcod 680'2817 mlcod 0'0 unknown pruub 27419.057930805s@ mbc={}] state<Start>: transitioning to Primary
[root@jianwei 10.128.130.71]# zcat ./host-log-node3/ceph/ceph-osd.44.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
2022-03-06T19:45:34.140+0800 7fe04b6b3700 1 osd.44 pg_epoch: 283 pg[3.356s1( v 279'354 (0'0,279'354] local-lis/les=248/249 n=2 ec=206/206 lis/c=248/248 les/c/f=249/249/0 sis=283) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=283 pi=[248,283)/1 crt=279'354 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:49:24.673+0800 7fe04b6b3700 1 osd.44 pg_epoch: 303 pg[3.356s1( v 285'400 (0'0,285'400] local-lis/les=283/284 n=7 ec=206/206 lis/c=283/248 les/c/f=284/249/0 sis=303 pruub=10.581939253s) [NONE,44,47,18,14,31]p44(1) r=1 lpr=303 pi=[248,303)/1 crt=285'400 lcod 285'399 mlcod 0'0 unknown pruub 29574.443035431s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:54:14.616+0800 7fe048eae700 1 osd.44 pg_epoch: 314 pg[3.356s1( v 311'433 (0'0,311'433] local-lis/les=304/305 n=0 ec=206/206 lis/c=304/304 les/c/f=305/307/0 sis=314 pruub=0.269329053s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=314 pi=[304,314)/1 crt=311'433 mlcod 0'0 unknown pruub 29854.075373914s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T01:32:55.458+0800 7fe048eae700 1 osd.44 pg_epoch: 556 pg[3.356s1( v 551'2148 (336'700,551'2148] local-lis/les=519/520 n=0 ec=206/206 lis/c=519/519 les/c/f=520/521/0 sis=556) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=556 pi=[519,556)/1 crt=551'2148 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T01:37:42.290+0800 7fe04b6b3700 1 osd.44 pg_epoch: 560 pg[3.356s1( v 559'2173 (336'700,559'2173] local-lis/les=556/557 n=3 ec=206/206 lis/c=556/519 les/c/f=557/521/0 sis=560 pruub=10.295012239s) [NONE,44,47,18,14,31]p44(1) r=1 lpr=560 pi=[519,560)/1 crt=559'2173 lcod 559'2172 mlcod 0'0 unknown pruub 50471.773195984s@ mbc={}] state<Start>: transitioning to Primary
[root@jianwei 10.128.130.71]# zcat ./host-log-node2/ceph/ceph-osd.47.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
[root@jianwei 10.128.130.71]#
[root@jianwei 10.128.130.71]# zcat ./host-log-node1/ceph/ceph-osd.18.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
[root@jianwei 10.128.130.71]#
[root@jianwei 10.128.130.71]# zcat ./host-log-node3/ceph/ceph-osd.14.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
[root@jianwei 10.128.130.71]#
[root@jianwei 10.128.130.71]# zcat ./host-log-node2/ceph/ceph-osd.31.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
[root@jianwei 10.128.130.71]#
Updated by jianwei zhang about 2 years ago
Radoslaw Zarzynski wrote:
the all osds is up&in, so the case doesn't involve recovery_unfound due to osd down.
A note from the bug scrub: this looks confusing. In the comment #22 a following info can be found:
[...]
which would mean that, at least for some time, 3 OSDs were down and this is enough to cause the issue.
Anyway, there is no another thing we can use to double check: the
can_rollback_to(aka.crtin the logs) value which is present in a log entry. Here is an example:[...]
Could you please provide similar entries for the affected PG?
[root@jianwei 10.128.130.71]# zcat ./host-log-node1/ceph/ceph-osd.49.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
2022-03-06T11:40:37.494+0800 7f911213d700 1 osd.49 pg_epoch: 206 pg[3.356s0( empty local-lis/les=0/0 n=0 ec=206/206 lis/c=0/0 les/c/f=0/0/0 sis=206) [49,44,47,22,14,1]p49(0) r=0 lpr=206 crt=0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T11:43:20.351+0800 7f910f938700 1 osd.49 pg_epoch: 237 pg[3.356s0( empty local-lis/les=206/207 n=0 ec=206/206 lis/c=206/206 les/c/f=207/207/0 sis=237 pruub=14.234196274s) [49,44,47,18,14,22]p49(0) r=0 lpr=237 pi=[206,237)/1 crt=0'0 mlcod 0'0 unknown pruub 389.257391117s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T11:44:16.610+0800 7f9114942700 1 osd.49 pg_epoch: 248 pg[3.356s0( empty local-lis/les=237/238 n=0 ec=206/206 lis/c=237/237 les/c/f=238/238/0 sis=248 pruub=8.653028340s) [49,44,47,18,14,31]p49(0) r=0 lpr=248 pi=[237,248)/1 crt=0'0 mlcod 0'0 unknown pruub 439.934734857s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:49:24.689+0800 7f3f50f04700 1 osd.49 pg_epoch: 280 pg[3.356s0( v 279'354 (0'0,279'354] local-lis/les=248/249 n=2 ec=206/206 lis/c=248/248 les/c/f=249/249/0 sis=248) [49,44,47,18,14,31]p49(0) r=0 lpr=279 crt=279'354 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:49:25.632+0800 7f3f50f04700 1 osd.49 pg_epoch: 304 pg[3.356s0( v 279'354 (0'0,279'354] local-lis/les=248/249 n=2 ec=206/206 lis/c=248/248 les/c/f=249/249/0 sis=304) [49,44,47,18,14,31]p49(0) r=0 lpr=304 pi=[248,304)/1 crt=279'354 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primar
2022-03-06T19:59:23.698+0800 7f34b6d16700 1 osd.49 pg_epoch: 313 pg[3.356s0( v 311'433 (0'0,311'433] local-lis/les=304/305 n=0 ec=206/206 lis/c=304/304 les/c/f=305/307/0 sis=304) [49,44,47,18,14,31]p49(0) r=0 lpr=311 crt=311'433 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:59:24.767+0800 7f34b951b700 1 osd.49 pg_epoch: 325 pg[3.356s0( v 311'433 (0'0,311'433] local-lis/les=304/305 n=0 ec=206/206 lis/c=304/304 les/c/f=305/307/0 sis=325) [49,44,47,18,14,31]p49(0) r=0 lpr=325 pi=[304,325)/1 crt=311'433 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primar
2022-03-06T20:56:51.475+0800 7f34b6d16700 1 osd.49 pg_epoch: 338 pg[3.356s0( v 337'804 (0'0,337'804] local-lis/les=325/326 n=0 ec=206/206 lis/c=325/325 les/c/f=326/327/0 sis=338 pruub=2.658631698s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=338 pi=[325,338)/1 crt=337'804 lcod 337'803 mlcod 0'0 unknown pruub 3457.315769102s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:02:23.610+0800 7f34b951b700 1 osd.49 pg_epoch: 351 pg[3.356s0( v 341'834 (0'0,341'834] local-lis/les=338/339 n=6 ec=206/206 lis/c=338/325 les/c/f=339/327/0 sis=351 pruub=12.800782387s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=351 pi=[325,351)/1 crt=341'834 lcod 341'833 mlcod 0'0 unknown pruub 3799.594023791s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:02:26.883+0800 7f34b6d16700 1 osd.49 pg_epoch: 354 pg[3.356s0( v 341'834 (0'0,341'834] local-lis/les=351/352 n=6 ec=206/206 lis/c=351/325 les/c/f=352/327/0 sis=354 pruub=13.974659987s) [49,44,47,18,14,31]p49(0) r=0 lpr=354 pi=[325,354)/1 crt=341'834 lcod 341'833 mlcod 0'0 unknown pruub 3804.040910339s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:09:19.029+0800 7f34b6d16700 1 osd.49 pg_epoch: 366 pg[3.356s0( v 365'877 (0'0,365'877] local-lis/les=354/355 n=0 ec=206/206 lis/c=354/354 les/c/f=355/363/0 sis=366 pruub=2.068333896s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=366 pi=[354,366)/1 crt=365'877 lcod 365'876 mlcod 0'0 unknown pruub 4207.197962580s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:12:30.167+0800 7f34b951b700 1 osd.49 pg_epoch: 381 pg[3.356s0( v 370'909 (0'0,370'909] local-lis/les=366/367 n=5 ec=206/206 lis/c=366/354 les/c/f=367/363/0 sis=381 pruub=9.917221160s) [49,44,47,18,14,31]p49(0) r=0 lpr=381 pi=[354,381)/1 crt=370'909 lcod 370'908 mlcod 0'0 unknown pruub 4406.184422104s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:13:44.854+0800 7f34bbd20700 1 osd.49 pg_epoch: 384 pg[3.356s0( v 383'918 (0'0,383'918] local-lis/les=381/382 n=5 ec=206/206 lis/c=381/381 les/c/f=382/383/0 sis=384) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=384 pi=[381,384)/1 crt=383'918 lcod 383'917 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T21:17:24.918+0800 7f34bbd20700 1 osd.49 pg_epoch: 398 pg[3.356s0( v 387'935 (0'0,387'935] local-lis/les=384/385 n=0 ec=206/206 lis/c=384/381 les/c/f=385/383/0 sis=398 pruub=13.494873878s) [49,44,47,18,14,31]p49(0) r=0 lpr=398 pi=[381,398)/1 crt=387'935 lcod 387'934 mlcod 0'0 unknown pruub 4704.512605106s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T23:56:07.266+0800 7f34bbd20700 1 osd.49 pg_epoch: 407 pg[3.356s0( v 406'1684 (278'300,406'1684] local-lis/les=398/399 n=0 ec=206/206 lis/c=398/398 les/c/f=399/399/0 sis=407 pruub=0.641491637s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=407 pi=[398,407)/1 crt=406'1684 lcod 406'1683 mlcod 0'0 unknown pruub 14214.006632879s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:01:18.395+0800 7f34bbd20700 1 osd.49 pg_epoch: 432 pg[3.356s0( v 409'1719 (278'300,409'1719] local-lis/les=407/408 n=4 ec=206/206 lis/c=407/398 les/c/f=408/399/0 sis=432 pruub=10.022340130s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=432 pi=[398,432)/1 crt=409'1719 lcod 409'1718 mlcod 0'0 unknown pruub 14534.516982275s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:01:19.720+0800 7f34bbd20700 1 osd.49 pg_epoch: 434 pg[3.356s0( v 409'1719 (278'300,409'1719] local-lis/les=432/433 n=4 ec=206/206 lis/c=432/398 les/c/f=433/399/0 sis=434 pruub=15.292470442s) [49,44,47,18,14,31]p49(0) r=0 lpr=434 pi=[398,434)/1 crt=409'1719 lcod 409'1718 mlcod 0'0 unknown pruub 14541.113063906s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:07:38.561+0800 7f34b6d16700 1 osd.49 pg_epoch: 460 pg[3.356s0( v 446'1723 (278'300,446'1723] local-lis/les=434/435 n=0 ec=206/206 lis/c=434/434 les/c/f=435/443/0 sis=460) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=460 pi=[434,460)/1 crt=446'1723 lcod 446'1722 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:12:26.728+0800 7f34b6d16700 1 osd.49 pg_epoch: 464 pg[3.356s0( v 463'1727 (278'300,463'1727] local-lis/les=460/461 n=1 ec=206/206 lis/c=460/434 les/c/f=461/443/0 sis=464 pruub=8.987281720s) [49,44,47,18,14,31]p49(0) r=0 lpr=464 pi=[434,464)/1 crt=463'1727 lcod 463'1726 mlcod 0'0 unknown pruub 15201.799332984s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:48:53.143+0800 7f34b6d16700 1 osd.49 pg_epoch: 472 pg[3.356s0( v 470'1923 (336'500,470'1923] local-lis/les=464/465 n=0 ec=206/206 lis/c=464/464 les/c/f=465/470/0 sis=472) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=472 pi=[464,472)/1 crt=470'1923 lcod 470'1922 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:54:22.123+0800 7f34bbd20700 1 osd.49 pg_epoch: 492 pg[3.356s0( v 482'1968 (336'500,482'1968] local-lis/les=472/473 n=7 ec=206/206 lis/c=472/464 les/c/f=473/470/0 sis=492 pruub=8.112465254s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=492 pi=[464,492)/1 crt=482'1968 lcod 481'1967 mlcod 0'0 unknown pruub 17716.335352355s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:54:24.598+0800 7f34b951b700 1 osd.49 pg_epoch: 495 pg[3.356s0( v 482'1968 (336'500,482'1968] local-lis/les=492/493 n=7 ec=206/206 lis/c=492/464 les/c/f=493/470/0 sis=495 pruub=14.715679461s) [49,44,47,18,14,31]p49(0) r=0 lpr=495 pi=[464,495)/1 crt=482'1968 lcod 481'1967 mlcod 0'0 unknown pruub 17725.413416775s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T00:59:44.574+0800 7f34b951b700 1 osd.49 pg_epoch: 504 pg[3.356s0( v 501'2011 (336'600,501'2011] local-lis/les=495/496 n=0 ec=206/206 lis/c=495/495 les/c/f=496/499/0 sis=504 pruub=1.142740998s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=504 pi=[495,504)/1 crt=501'2011 lcod 501'2010 mlcod 0'0 unknown pruub 18031.816826822s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T01:04:48.209+0800 7f34bbd20700 1 osd.49 pg_epoch: 519 pg[3.356s0( v 517'2033 (336'600,517'2033] local-lis/les=504/505 n=1 ec=206/206 lis/c=504/495 les/c/f=505/499/0 sis=519 pruub=9.387994059s) [49,44,47,18,14,31]p49(0) r=0 lpr=519 pi=[495,519)/1 crt=517'2033 lcod 508'2032 mlcod 0'0 unknown pruub 18343.697681454s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T01:37:43.250+0800 7f34b951b700 1 osd.49 pg_epoch: 561 pg[3.356s0( v 551'2148 (336'700,551'2148] local-lis/les=519/520 n=0 ec=206/206 lis/c=519/519 les/c/f=520/521/0 sis=561) [49,44,47,18,14,31]p49(0) r=0 lpr=561 pi=[519,561)/1 crt=551'2148 lcod 551'2147 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:15:36.459+0800 7f34b951b700 1 osd.49 pg_epoch: 581 pg[3.356s0( v 580'2334 (370'900,580'2334] local-lis/les=561/562 n=0 ec=206/206 lis/c=561/561 les/c/f=562/573/0 sis=581 pruub=0.577405628s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=581 pi=[561,581)/1 crt=580'2334 lcod 580'2333 mlcod 0'0 unknown pruub 22583.135910195s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:19:45.846+0800 7f34b951b700 1 osd.49 pg_epoch: 603 pg[3.356s0( v 584'2342 (370'900,584'2342] local-lis/les=581/582 n=1 ec=206/206 lis/c=581/561 les/c/f=582/573/0 sis=603 pruub=15.784000584s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=603 pi=[561,603)/1 crt=584'2342 lcod 584'2341 mlcod 0'0 unknown pruub 22847.729989461s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:19:47.987+0800 7f34bbd20700 1 osd.49 pg_epoch: 605 pg[3.356s0( v 584'2342 (370'900,584'2342] local-lis/les=603/604 n=1 ec=206/206 lis/c=603/561 les/c/f=604/573/0 sis=605 pruub=15.168124659s) [49,44,47,18,14,31]p49(0) r=0 lpr=605 pi=[561,605)/1 crt=584'2342 lcod 584'2341 mlcod 0'0 unknown pruub 22849.255179360s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:26:19.496+0800 7f34bbd20700 1 osd.49 pg_epoch: 609 pg[3.356s0( v 606'2352 (370'900,606'2352] local-lis/les=605/606 n=0 ec=206/206 lis/c=605/605 les/c/f=606/606/0 sis=609) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=609 pi=[605,609)/1 crt=606'2352 lcod 606'2351 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:31:07.769+0800 7f34bbd20700 1 osd.49 pg_epoch: 612 pg[3.356s0( v 611'2410 (399'1000,611'2410] local-lis/les=609/610 n=6 ec=206/206 lis/c=609/605 les/c/f=610/606/0 sis=612 pruub=8.894910398s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=612 pi=[605,612)/1 crt=611'2410 lcod 611'2409 mlcod 0'0 unknown pruub 23522.764383257s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T02:31:08.641+0800 7f34bbd20700 1 osd.49 pg_epoch: 613 pg[3.356s0( v 611'2410 (399'1000,611'2410] local-lis/les=609/610 n=6 ec=206/206 lis/c=609/605 les/c/f=610/606/0 sis=613) [49,44,47,18,14,31]p49(0) r=0 lpr=613 pi=[605,613)/1 crt=611'2410 lcod 611'2409 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T03:29:39.975+0800 7f34b6d16700 1 osd.49 pg_epoch: 656 pg[3.356s0( v 655'2768 (405'1300,655'2768] local-lis/les=613/614 n=0 ec=206/206 lis/c=613/613 les/c/f=614/619/0 sis=656 pruub=2.932511832s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=656 pi=[613,656)/1 crt=655'2768 lcod 655'2767 mlcod 0'0 unknown pruub 27029.006564684s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T03:35:57.904+0800 7f34bbd20700 1 osd.49 pg_epoch: 686 pg[3.356s0( v 683'2818 (405'1400,683'2818] local-lis/les=656/657 n=7 ec=206/206 lis/c=656/613 les/c/f=657/619/0 sis=686 pruub=15.053891262s) [49,44,47,18,14,31]p49(0) r=0 lpr=686 pi=[613,686)/1 crt=683'2818 lcod 680'2817 mlcod 0'0 unknown pruub 27419.057930805s@ mbc={}] state<Start>: transitioning to Primary
[root@jianwei 10.128.130.71]# zcat ./host-log-node3/ceph/ceph-osd.44.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
2022-03-06T19:45:34.140+0800 7fe04b6b3700 1 osd.44 pg_epoch: 283 pg[3.356s1( v 279'354 (0'0,279'354] local-lis/les=248/249 n=2 ec=206/206 lis/c=248/248 les/c/f=249/249/0 sis=283) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=283 pi=[248,283)/1 crt=279'354 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:49:24.673+0800 7fe04b6b3700 1 osd.44 pg_epoch: 303 pg[3.356s1( v 285'400 (0'0,285'400] local-lis/les=283/284 n=7 ec=206/206 lis/c=283/248 les/c/f=284/249/0 sis=303 pruub=10.581939253s) [NONE,44,47,18,14,31]p44(1) r=1 lpr=303 pi=[248,303)/1 crt=285'400 lcod 285'399 mlcod 0'0 unknown pruub 29574.443035431s@ mbc={}] state<Start>: transitioning to Primary
2022-03-06T19:54:14.616+0800 7fe048eae700 1 osd.44 pg_epoch: 314 pg[3.356s1( v 311'433 (0'0,311'433] local-lis/les=304/305 n=0 ec=206/206 lis/c=304/304 les/c/f=305/307/0 sis=314 pruub=0.269329053s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=314 pi=[304,314)/1 crt=311'433 mlcod 0'0 unknown pruub 29854.075373914s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T01:32:55.458+0800 7fe048eae700 1 osd.44 pg_epoch: 556 pg[3.356s1( v 551'2148 (336'700,551'2148] local-lis/les=519/520 n=0 ec=206/206 lis/c=519/519 les/c/f=520/521/0 sis=556) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=556 pi=[519,556)/1 crt=551'2148 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T01:37:42.290+0800 7fe04b6b3700 1 osd.44 pg_epoch: 560 pg[3.356s1( v 559'2173 (336'700,559'2173] local-lis/les=556/557 n=3 ec=206/206 lis/c=556/519 les/c/f=557/521/0 sis=560 pruub=10.295012239s) [NONE,44,47,18,14,31]p44(1) r=1 lpr=560 pi=[519,560)/1 crt=559'2173 lcod 559'2172 mlcod 0'0 unknown pruub 50471.773195984s@ mbc={}] state<Start>: transitioning to Primary
[root@jianwei 10.128.130.71]# zcat ./host-log-node2/ceph/ceph-osd.47.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
[root@jianwei 10.128.130.71]#
[root@jianwei 10.128.130.71]# zcat ./host-log-node1/ceph/ceph-osd.18.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
[root@jianwei 10.128.130.71]#
[root@jianwei 10.128.130.71]# zcat ./host-log-node3/ceph/ceph-osd.14.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
[root@jianwei 10.128.130.71]#
[root@jianwei 10.128.130.71]# zcat ./host-log-node2/ceph/ceph-osd.31.log-20220307.gz |grep '3\.356s'|grep 'transitioning to Primary'
[root@jianwei 10.128.130.71]#
Updated by jianwei zhang about 2 years ago
sorry, above log is 2022-03-07, too old
following log is the problem timestamp log
Updated by jianwei zhang about 2 years ago
[root@jianwei ceph]# grep 'transitioning to Primary' ceph-osd.49.log-20220308|grep -e 2022-03-07T17:4 -e 2022-03-07T17:5
2022-03-07T17:47:52.164+0800 7fd476d22700 1 osd.49 pg_epoch: 1712 pg[3.14bs1( v 1711'7024 (1433'5600,1711'7024] local-lis/les=1706/1707 n=7 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1712 pruub=4.191120771s) [NONE,49,5,41,43,10]p49(1) r=1 lpr=1712 pi=[1706,1712)/1 crt=1711'7024 mlcod 0'0 unknown pruub 6305.379564888s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:47:52.165+0800 7fd479527700 1 osd.49 pg_epoch: 1712 pg[3.286s0( v 1711'7232 (1437'5793,1711'7232] local-lis/les=1706/1707 n=4 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1712 pruub=4.396731598s) [49,NONE,43,50,31,36]p49(0) r=0 lpr=1712 pi=[1706,1712)/1 crt=1711'7232 lcod 1711'7231 mlcod 0'0 unknown pruub 6305.584962584s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:47:52.165+0800 7fd476d22700 1 osd.49 pg_epoch: 1712 pg[3.2f9s1( v 1711'7222 (1433'5800,1711'7222] local-lis/les=1706/1707 n=7 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1712 pruub=4.215228603s) [NONE,49,48,13,43,1]p49(1) r=1 lpr=1712 pi=[1706,1712)/1 crt=1711'7222 mlcod 0'0 unknown pruub 6305.405005523s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:47:52.170+0800 7fd472d1a700 1 osd.49 pg_epoch: 1712 pg[3.356s0( v 1711'7107 (1437'5676,1711'7107] local-lis/les=1706/1707 n=9 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1712 pruub=4.391165257s) [49,44,47,18,NONE,31]p49(0) r=0 lpr=1712 pi=[1706,1712)/1 crt=1711'7107 lcod 1711'7106 mlcod 0'0 unknown pruub 6305.584885278s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:47:52.171+0800 7fd477523700 1 osd.49 pg_epoch: 1712 pg[3.30cs0( v 1711'7012 (1441'5570,1711'7012] local-lis/les=1705/1706 n=4 ec=206/206 lis/c=1705/1705 les/c/f=1706/1709/0 sis=1712 pruub=3.287798304s) [49,44,22,NONE,37,36]p49(0) r=0 lpr=1712 pi=[1705,1712)/1 crt=1711'7012 lcod 1711'7011 mlcod 0'0 unknown pruub 6304.482316580s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:47:52.173+0800 7fd477d24700 1 osd.49 pg_epoch: 1712 pg[3.27fs1( v 1711'7183 (1437'5800,1711'7183] local-lis/les=1706/1707 n=10 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1712 pruub=4.208083074s) [NONE,49,5,10,51,43]p49(1) r=1 lpr=1712 pi=[1706,1712)/1 crt=1711'7183 mlcod 0'0 unknown pruub 6305.405714922s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:47:52.174+0800 7fd475d20700 1 osd.49 pg_epoch: 1712 pg[3.1cfs0( v 1711'7129 (1436'5708,1711'7129] local-lis/les=1705/1706 n=6 ec=206/206 lis/c=1705/1705 les/c/f=1706/1709/0 sis=1712 pruub=3.297334483s) [49,50,10,37,NONE,22]p49(0) r=0 lpr=1712 pi=[1705,1712)/1 crt=1711'7129 lcod 1711'7128 mlcod 0'0 unknown pruub 6304.495572882s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:47:52.179+0800 7fd475d20700 1 osd.49 pg_epoch: 1712 pg[3.3f5s0( v 1711'7842 (1514'6426,1711'7842] local-lis/les=1706/1707 n=1 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1712 pruub=4.197060802s) [49,NONE,50,36,43,5]p49(0) r=0 lpr=1712 pi=[1706,1712)/1 crt=1711'7842 lcod 1711'7841 mlcod 0'0 unknown pruub 6305.400397981s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.580+0800 7fd478d26700 1 osd.49 pg_epoch: 1714 pg[3.340s1( v 1711'6973 (1436'5500,1711'6973] local-lis/les=1705/1706 n=3 ec=206/206 lis/c=1705/1705 les/c/f=1706/1709/0 sis=1714) [NONE,49,22,37,38,10]p49(1) r=1 lpr=1714 pi=[1705,1714)/1 crt=1711'6973 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.581+0800 7fd474d1e700 1 osd.49 pg_epoch: 1714 pg[3.30cs0( v 1711'7012 (1441'5570,1711'7012] local-lis/les=1712/1713 n=4 ec=206/206 lis/c=1712/1705 les/c/f=1713/1709/0 sis=1714) [49,NONE,22,NONE,37,36]p49(0) r=0 lpr=1714 pi=[1705,1714)/1 crt=1711'7012 lcod 1711'7011 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.581+0800 7fd47451d700 1 osd.49 pg_epoch: 1714 pg[3.24fs1( v 1711'7365 (1469'5900,1711'7365] local-lis/les=1706/1707 n=4 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1714) [NONE,49,31,1,32,37]p49(1) r=1 lpr=1714 pi=[1706,1714)/1 crt=1711'7365 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.581+0800 7fd477d24700 1 osd.49 pg_epoch: 1714 pg[3.13s0( v 1713'7189 (1436'5780,1713'7189] local-lis/les=1705/1706 n=5 ec=206/206 lis/c=1705/1705 les/c/f=1706/1709/0 sis=1714) [49,23,37,NONE,36,22]p49(0) r=0 lpr=1714 pi=[1705,1714)/1 crt=1713'7189 lcod 1711'7188 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.583+0800 7fd476521700 1 osd.49 pg_epoch: 1714 pg[3.7as0( v 1711'7509 (1437'6075,1711'7509] local-lis/les=1704/1705 n=7 ec=206/206 lis/c=1704/1704 les/c/f=1705/1709/0 sis=1714) [49,NONE,1,3,13,40]p49(0) r=0 lpr=1714 pi=[1704,1714)/1 crt=1711'7509 lcod 1711'7508 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.583+0800 7fd472d1a700 1 osd.49 pg_epoch: 1714 pg[3.356s0( v 1711'7107 (1437'5676,1711'7107] local-lis/les=1712/1713 n=9 ec=206/206 lis/c=1712/1706 les/c/f=1713/1709/0 sis=1714) [49,NONE,47,18,NONE,31]p49(0) r=0 lpr=1714 pi=[1706,1714)/1 crt=1711'7107 lcod 1711'7106 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.583+0800 7fd475d20700 1 osd.49 pg_epoch: 1714 pg[3.346s0( v 1713'7433 (1514'6018,1713'7433] local-lis/les=1706/1707 n=4 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1714) [49,43,NONE,22,23,27]p49(0) r=0 lpr=1714 pi=[1706,1714)/1 crt=1713'7433 lcod 1711'7432 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.584+0800 7fd472d1a700 1 osd.49 pg_epoch: 1714 pg[3.22fs1( v 1711'6932 (1433'5500,1711'6932] local-lis/les=1712/1713 n=9 ec=206/206 lis/c=1712/1705 les/c/f=1713/1709/0 sis=1714) [NONE,49,NONE,36,22,37]p49(1) r=1 lpr=1714 pi=[1705,1714)/1 crt=1711'6932 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.586+0800 7fd478525700 1 osd.49 pg_epoch: 1714 pg[3.1bbs0( v 1713'6612 (1432'5207,1713'6612] local-lis/les=1704/1705 n=8 ec=206/206 lis/c=1704/1704 les/c/f=1705/1707/0 sis=1714) [49,18,NONE,13,47,32]p49(0) r=0 lpr=1714 pi=[1704,1714)/1 crt=1713'6611 lcod 1711'6610 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.586+0800 7fd472d1a700 1 osd.49 pg_epoch: 1714 pg[3.20cs0( v 1713'7621 (1433'6146,1713'7621] local-lis/les=1704/1705 n=7 ec=206/206 lis/c=1704/1704 les/c/f=1705/1707/0 sis=1714) [49,38,27,13,NONE,47]p49(0) r=0 lpr=1714 pi=[1704,1714)/1 crt=1713'7621 lcod 1711'7620 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.587+0800 7fd478525700 1 osd.49 pg_epoch: 1714 pg[3.238s2( v 1711'7511 (1437'6100,1711'7511] local-lis/les=1712/1713 n=5 ec=206/206 lis/c=1712/1706 les/c/f=1713/1709/0 sis=1714) [NONE,NONE,49,43,27,31]p49(2) r=2 lpr=1714 pi=[1706,1714)/1 crt=1711'7511 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.588+0800 7fd477d24700 1 osd.49 pg_epoch: 1714 pg[3.15ds0( v 1711'7054 (1436'5627,1711'7054] local-lis/les=1705/1706 n=4 ec=206/206 lis/c=1705/1705 les/c/f=1706/1709/0 sis=1714) [49,NONE,5,47,1,38]p49(0) r=0 lpr=1714 pi=[1705,1714)/1 crt=1711'7054 lcod 1711'7053 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.484+0800 7fd478d26700 1 osd.49 pg_epoch: 1716 pg[3.1abs0( v 1715'6917 (1433'5461,1715'6917] local-lis/les=1701/1702 n=7 ec=206/206 lis/c=1701/1701 les/c/f=1702/1707/0 sis=1716 pruub=0.515762003s) [49,NONE,48,27,23,22]p49(0) r=0 lpr=1716 pi=[1701,1716)/1 crt=1715'6917 lcod 1711'6916 mlcod 0'0 unknown pruub 6340.024717519s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.484+0800 7fd476d22700 1 osd.49 pg_epoch: 1716 pg[3.236s0( v 1715'7052 (1437'5664,1715'7052] local-lis/les=1704/1705 n=9 ec=206/206 lis/c=1704/1704 les/c/f=1705/1707/0 sis=1716 pruub=4.534575291s) [49,36,13,23,NONE,51]p49(0) r=0 lpr=1716 pi=[1704,1716)/1 crt=1715'7052 lcod 1711'7051 mlcod 0'0 unknown pruub 6344.043403096s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.484+0800 7fd477523700 1 osd.49 pg_epoch: 1716 pg[3.25ds0( v 1711'7170 (1514'5778,1711'7170] local-lis/les=1705/1706 n=7 ec=206/206 lis/c=1705/1705 les/c/f=1706/1709/0 sis=1716) [49,36,48,NONE,3,5]p49(0) r=0 lpr=1716 pi=[1705,1716)/1 crt=1711'7170 lcod 1711'7169 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.488+0800 7fd472d1a700 1 osd.49 pg_epoch: 1716 pg[3.15ds0( v 1711'7054 (1436'5627,1711'7054] local-lis/les=1714/1715 n=4 ec=206/206 lis/c=1714/1705 les/c/f=1715/1709/0 sis=1716 pruub=4.320797432s) [49,NONE,5,NONE,1,38]p49(0) r=0 lpr=1716 pi=[1705,1716)/1 crt=1711'7054 lcod 1711'7053 mlcod 0'0 unknown pruub 6343.833850232s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.488+0800 7fd477d24700 1 osd.49 pg_epoch: 1716 pg[3.20cs0( v 1713'7621 (1433'6146,1713'7621] local-lis/les=1714/1715 n=7 ec=206/206 lis/c=1714/1704 les/c/f=1715/1707/0 sis=1716 pruub=4.327716162s) [49,38,27,13,NONE,NONE]p49(0) r=0 lpr=1716 pi=[1704,1716)/1 crt=1713'7621 lcod 1711'7620 mlcod 0'0 unknown pruub 6343.841418649s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.488+0800 7fd478525700 1 osd.49 pg_epoch: 1716 pg[3.1bbs0( v 1713'6612 (1432'5207,1713'6612] local-lis/les=1714/1715 n=8 ec=206/206 lis/c=1714/1704 les/c/f=1715/1707/0 sis=1716 pruub=4.324334286s) [49,18,NONE,13,NONE,32]p49(0) r=0 lpr=1716 pi=[1704,1716)/1 crt=1713'6612 lcod 1711'6610 mlcod 0'0 unknown pruub 6343.838083995s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.488+0800 7fd475d20700 1 osd.49 pg_epoch: 1716 pg[3.4es0( v 1713'7450 (1441'6047,1713'7450] local-lis/les=1704/1705 n=16 ec=206/206 lis/c=1704/1704 les/c/f=1705/1707/0 sis=1716 pruub=4.521478595s) [49,NONE,18,13,32,48]p49(0) r=0 lpr=1716 pi=[1704,1716)/1 crt=1713'7450 lcod 1713'7449 mlcod 0'0 unknown pruub 6344.034386656s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.490+0800 7fd47551f700 1 osd.49 pg_epoch: 1716 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1716 pruub=4.332741706s) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1716 pi=[1706,1716)/1 crt=1715'7109 lcod 1715'7108 mlcod 0'0 unknown pruub 6343.848557841s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:44.370+0800 7fd47451d700 1 osd.49 pg_epoch: 1719 pg[3.286s0( v 1711'7232 (1437'5793,1711'7232] local-lis/les=1712/1713 n=4 ec=206/206 lis/c=1712/1706 les/c/f=1713/1709/0 sis=1719 pruub=12.872266809s) [49,14,43,50,31,36]p49(0) r=0 lpr=1719 pi=[1706,1719)/1 crt=1711'7232 lcod 1711'7231 mlcod 0'0 unknown pruub 6366.266580619s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:44.370+0800 7fd474d1e700 1 osd.49 pg_epoch: 1719 pg[3.30cs0( v 1711'7012 (1441'5570,1711'7012] local-lis/les=1714/1715 n=4 ec=206/206 lis/c=1714/1705 les/c/f=1715/1709/0 sis=1719 pruub=14.446404830s) [49,NONE,22,14,37,36]p49(0) r=0 lpr=1719 pi=[1705,1719)/1 crt=1711'7012 lcod 1711'7011 mlcod 0'0 unknown pruub 6367.841124947s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:44.376+0800 7fd47351b700 1 osd.49 pg_epoch: 1719 pg[3.1cfs0( v 1717'7133 (1436'5708,1717'7133] local-lis/les=1712/1713 n=6 ec=206/206 lis/c=1712/1705 les/c/f=1713/1709/0 sis=1719 pruub=12.874102749s) [49,50,10,37,14,22]p49(0) r=0 lpr=1719 pi=[1705,1719)/1 crt=1717'7133 lcod 1717'7132 mlcod 0'0 unknown pruub 6366.274721049s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:44.378+0800 7fd47551f700 1 osd.49 pg_epoch: 1719 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1719) [49,NONE,NONE,18,14,31]p49(0) r=0 lpr=1719 pi=[1706,1719)/1 crt=1715'7109 lcod 1715'7108 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:44.381+0800 7fd478525700 1 osd.49 pg_epoch: 1719 pg[3.3f5s0( v 1711'7842 (1514'6426,1711'7842] local-lis/les=1712/1713 n=1 ec=206/206 lis/c=1712/1706 les/c/f=1713/1709/0 sis=1719 pruub=12.862215511s) [49,14,50,36,43,5]p49(0) r=0 lpr=1719 pi=[1706,1719)/1 crt=1711'7842 lcod 1711'7841 mlcod 0'0 unknown pruub 6366.266933351s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:44.384+0800 7fd47551f700 1 osd.49 pg_epoch: 1719 pg[3.22fs1( v 1717'6935 (1433'5500,1717'6935] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1705 les/c/f=1715/1709/0 sis=1719 pruub=14.434811987s) [NONE,49,14,36,22,37]p49(1) r=1 lpr=1719 pi=[1705,1719)/1 crt=1717'6935 lcod 1717'6934 mlcod 0'0 unknown pruub 6367.843717213s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.808+0800 7fd474d1e700 1 osd.49 pg_epoch: 1721 pg[3.30cs0( v 1711'7012 (1441'5570,1711'7012] local-lis/les=1719/1720 n=4 ec=206/206 lis/c=1719/1705 les/c/f=1720/1709/0 sis=1721 pruub=2.583383986s) [49,NONE,22,NONE,37,36]p49(0) r=0 lpr=1721 pi=[1705,1721)/2 crt=1711'7012 lcod 1711'7011 mlcod 0'0 unknown pruub 6370.415690765s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.810+0800 7fd479527700 1 osd.49 pg_epoch: 1721 pg[3.2f9s1( v 1717'7227 (1433'5800,1717'7227] local-lis/les=1719/1720 n=7 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1721) [NONE,49,48,13,43,1]p49(1) r=1 lpr=1721 pi=[1706,1721)/2 crt=1717'7227 lcod 1717'7226 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.812+0800 7fd47451d700 1 osd.49 pg_epoch: 1721 pg[3.14bs1( v 1711'7024 (1433'5600,1711'7024] local-lis/les=1719/1720 n=7 ec=206/206 lis/c=1719/1719 les/c/f=1720/1720/0 sis=1721) [NONE,49,5,41,43,10]p49(1) r=1 lpr=1721 pi=[1719,1721)/1 crt=1711'7024 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.813+0800 7fd479527700 1 osd.49 pg_epoch: 1721 pg[3.286s0( v 1711'7232 (1437'5793,1711'7232] local-lis/les=1719/1720 n=4 ec=206/206 lis/c=1719/1719 les/c/f=1720/1720/0 sis=1721 pruub=2.668717919s) [49,NONE,43,50,31,36]p49(0) r=0 lpr=1721 pi=[1719,1721)/1 crt=1711'7232 lcod 1711'7231 mlcod 0'0 unknown pruub 6370.505664746s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.813+0800 7fd47351b700 1 osd.49 pg_epoch: 1721 pg[3.1cfs0( v 1717'7133 (1436'5708,1717'7133] local-lis/les=1719/1720 n=6 ec=206/206 lis/c=1719/1705 les/c/f=1720/1709/0 sis=1721 pruub=2.670554899s) [49,50,10,37,NONE,22]p49(0) r=0 lpr=1721 pi=[1705,1721)/2 crt=1717'7133 lcod 1717'7132 mlcod 0'0 unknown pruub 6370.508374323s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.814+0800 7fd475d20700 1 osd.49 pg_epoch: 1721 pg[3.238s2( v 1715'7512 (1437'6100,1715'7512] local-lis/les=1719/1720 n=5 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1721) [NONE,NONE,49,43,27,31]p49(2) r=2 lpr=1721 pi=[1706,1721)/2 crt=1715'7512 lcod 1711'7511 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.816+0800 7fd472d1a700 1 osd.49 pg_epoch: 1721 pg[3.27fs1( v 1717'7187 (1437'5800,1717'7187] local-lis/les=1719/1720 n=10 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1721) [NONE,49,5,10,51,43]p49(1) r=1 lpr=1721 pi=[1706,1721)/2 crt=1717'7187 lcod 1717'7186 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.817+0800 7fd475d20700 1 osd.49 pg_epoch: 1721 pg[3.3f5s0( v 1711'7842 (1514'6426,1711'7842] local-lis/les=1719/1720 n=1 ec=206/206 lis/c=1719/1719 les/c/f=1720/1720/0 sis=1721 pruub=2.663814162s) [49,NONE,50,36,43,5]p49(0) r=0 lpr=1721 pi=[1719,1721)/1 crt=1711'7842 lcod 1711'7841 mlcod 0'0 unknown pruub 6370.505425742s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.819+0800 7fd477d24700 1 osd.49 pg_epoch: 1721 pg[3.22fs1( v 1717'6935 (1433'5500,1717'6935] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1705 les/c/f=1720/1709/0 sis=1721 pruub=2.824175751s) [NONE,49,NONE,36,22,37]p49(1) r=1 lpr=1721 pi=[1705,1721)/2 crt=1717'6935 lcod 1717'6934 mlcod 0'0 unknown pruub 6370.667566316s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.819+0800 7fd472d1a700 1 osd.49 pg_epoch: 1721 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1721 pruub=2.823632061s) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1721 pi=[1706,1721)/1 crt=1720'7111 lcod 1715'7110 mlcod 0'0 unknown pruub 6370.667211529s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.105+0800 7fd473d1c700 1 osd.49 pg_epoch: 1724 pg[3.7as0( v 1711'7509 (1437'6075,1711'7509] local-lis/les=1714/1715 n=7 ec=206/206 lis/c=1714/1704 les/c/f=1715/1709/0 sis=1724 pruub=10.706362626s) [49,44,1,3,13,40]p49(0) r=0 lpr=1724 pi=[1704,1724)/1 crt=1711'7509 lcod 1711'7508 mlcod 0'0 unknown pruub 6383.835825554s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.105+0800 7fd477523700 1 osd.49 pg_epoch: 1724 pg[3.30cs0( v 1711'7012 (1441'5570,1711'7012] local-lis/les=1721/1722 n=4 ec=206/206 lis/c=1721/1705 les/c/f=1722/1709/0 sis=1724 pruub=11.816955889s) [49,44,22,NONE,37,36]p49(0) r=0 lpr=1724 pi=[1705,1724)/2 crt=1711'7012 lcod 1711'7011 mlcod 0'0 unknown pruub 6384.946350832s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.105+0800 7fd475d20700 1 osd.49 pg_epoch: 1724 pg[3.346s0( v 1717'7436 (1514'6018,1717'7436] local-lis/les=1714/1715 n=4 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1724 pruub=10.716009076s) [49,43,44,22,23,27]p49(0) r=0 lpr=1724 pi=[1706,1724)/1 crt=1717'7436 lcod 1717'7435 mlcod 0'0 unknown pruub 6383.845507964s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.109+0800 7fd47551f700 1 osd.49 pg_epoch: 1724 pg[3.20cs0( v 1722'7626 (1433'6146,1722'7626] local-lis/les=1716/1717 n=7 ec=206/206 lis/c=1716/1704 les/c/f=1717/1707/0 sis=1724 pruub=15.526731851s) [49,38,27,13,44,NONE]p49(0) r=0 lpr=1724 pi=[1704,1724)/1 crt=1722'7626 lcod 1718'7625 mlcod 0'0 unknown pruub 6388.659832555s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.110+0800 7fd47551f700 1 osd.49 pg_epoch: 1724 pg[3.15ds0( v 1711'7054 (1436'5627,1711'7054] local-lis/les=1716/1717 n=4 ec=206/206 lis/c=1716/1705 les/c/f=1717/1709/0 sis=1724 pruub=15.524148851s) [49,44,5,NONE,1,38]p49(0) r=0 lpr=1724 pi=[1705,1724)/1 crt=1711'7054 lcod 1711'7053 mlcod 0'0 unknown pruub 6388.658753479s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.112+0800 7fd47351b700 1 osd.49 pg_epoch: 1724 pg[3.1bbs0( v 1717'6616 (1432'5207,1717'6616] local-lis/les=1716/1717 n=8 ec=206/206 lis/c=1716/1704 les/c/f=1717/1707/0 sis=1724 pruub=15.530467565s) [49,18,44,13,NONE,32]p49(0) r=0 lpr=1724 pi=[1704,1724)/1 crt=1717'6616 lcod 1717'6615 mlcod 0'0 unknown pruub 6388.667297050s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.114+0800 7fd47551f700 1 osd.49 pg_epoch: 1724 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1724) [49,44,NONE,18,NONE,31]p49(0) r=0 lpr=1724 pi=[1706,1724)/1 crt=1720'7111 lcod 1715'7110 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.116+0800 7fd477d24700 1 osd.49 pg_epoch: 1724 pg[3.13s0( v 1717'7190 (1436'5780,1717'7190] local-lis/les=1714/1715 n=5 ec=206/206 lis/c=1714/1705 les/c/f=1715/1709/0 sis=1724 pruub=10.704683640s) [49,23,37,44,36,22]p49(0) r=0 lpr=1724 pi=[1705,1724)/1 crt=1717'7190 lcod 1713'7189 mlcod 0'0 unknown pruub 6383.844838178s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.159+0800 7fd473d1c700 1 osd.49 pg_epoch: 1727 pg[3.1abs0( v 1715'6917 (1433'5461,1715'6917] local-lis/les=1716/1717 n=7 ec=206/206 lis/c=1716/1701 les/c/f=1717/1707/0 sis=1727 pruub=14.510382058s) [49,47,48,27,23,22]p49(0) r=0 lpr=1727 pi=[1701,1727)/1 crt=1715'6917 lcod 1711'6916 mlcod 0'0 unknown pruub 6404.693759325s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.160+0800 7fd47351b700 1 osd.49 pg_epoch: 1727 pg[3.346s0( v 1717'7436 (1514'6018,1717'7436] local-lis/les=1724/1725 n=4 ec=206/206 lis/c=1724/1706 les/c/f=1725/1709/0 sis=1727 pruub=0.245137087s) [49,43,NONE,22,23,27]p49(0) r=0 lpr=1727 pi=[1706,1727)/2 crt=1717'7436 lcod 1717'7435 mlcod 0'0 unknown pruub 6390.429154695s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.161+0800 7fd475d20700 1 osd.49 pg_epoch: 1727 pg[3.4es0( v 1725'7457 (1441'6047,1725'7457] local-lis/les=1716/1717 n=16 ec=206/206 lis/c=1716/1704 les/c/f=1717/1707/0 sis=1727 pruub=14.509663689s) [49,47,18,13,32,48]p49(0) r=0 lpr=1727 pi=[1704,1727)/1 crt=1725'7457 lcod 1725'7456 mlcod 0'0 unknown pruub 6404.694273157s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.161+0800 7fd47451d700 1 osd.49 pg_epoch: 1727 pg[3.24fs1( v 1711'7365 (1469'5900,1711'7365] local-lis/les=1724/1725 n=4 ec=206/206 lis/c=1724/1724 les/c/f=1725/1725/0 sis=1727) [NONE,49,31,1,32,37]p49(1) r=1 lpr=1727 pi=[1724,1727)/1 crt=1711'7365 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.162+0800 7fd475d20700 1 osd.49 pg_epoch: 1727 pg[3.238s2( v 1715'7512 (1437'6100,1715'7512] local-lis/les=1724/1725 n=5 ec=206/206 lis/c=1724/1706 les/c/f=1725/1709/0 sis=1727) [NONE,NONE,49,43,27,31]p49(2) r=2 lpr=1727 pi=[1706,1727)/2 crt=1715'7512 lcod 1711'7511 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.162+0800 7fd474d1e700 1 osd.49 pg_epoch: 1727 pg[3.30cs0( v 1711'7012 (1441'5570,1711'7012] local-lis/les=1724/1725 n=4 ec=206/206 lis/c=1724/1705 les/c/f=1725/1709/0 sis=1727 pruub=0.102266182s) [49,NONE,22,NONE,37,36]p49(0) r=0 lpr=1727 pi=[1705,1727)/2 crt=1711'7012 lcod 1711'7011 mlcod 0'0 unknown pruub 6390.288700116s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.162+0800 7fd47551f700 1 osd.49 pg_epoch: 1727 pg[3.20cs0( v 1722'7626 (1433'6146,1722'7626] local-lis/les=1724/1725 n=7 ec=206/206 lis/c=1724/1704 les/c/f=1725/1707/0 sis=1727 pruub=0.271422246s) [49,38,27,13,NONE,47]p49(0) r=0 lpr=1727 pi=[1704,1727)/2 crt=1722'7626 lcod 1718'7625 mlcod 0'0 unknown pruub 6390.457936308s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.164+0800 7fd478525700 1 osd.49 pg_epoch: 1727 pg[3.1bbs0( v 1717'6616 (1432'5207,1717'6616] local-lis/les=1724/1725 n=8 ec=206/206 lis/c=1724/1704 les/c/f=1725/1707/0 sis=1727 pruub=0.241142712s) [49,18,NONE,13,47,32]p49(0) r=0 lpr=1727 pi=[1704,1727)/2 crt=1717'6616 lcod 1717'6615 mlcod 0'0 unknown pruub 6390.429355515s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.165+0800 7fd479527700 1 osd.49 pg_epoch: 1727 pg[3.236s0( v 1725'7056 (1437'5664,1725'7056] local-lis/les=1716/1717 n=9 ec=206/206 lis/c=1716/1704 les/c/f=1717/1707/0 sis=1727 pruub=14.468227066s) [49,36,13,23,47,51]p49(0) r=0 lpr=1727 pi=[1704,1727)/1 crt=1725'7056 lcod 1720'7055 mlcod 0'0 unknown pruub 6404.657961515s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.165+0800 7fd472d1a700 1 osd.49 pg_epoch: 1727 pg[3.356s0( v 1725'7113 (1437'5676,1725'7113] local-lis/les=1724/1725 n=9 ec=206/206 lis/c=1724/1706 les/c/f=1725/1709/0 sis=1727 pruub=0.272948061s) [49,NONE,47,18,NONE,31]p49(0) r=0 lpr=1727 pi=[1706,1727)/1 crt=1725'7113 lcod 1725'7112 mlcod 0'0 unknown pruub 6390.458642978s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.167+0800 7fd477d24700 1 osd.49 pg_epoch: 1727 pg[3.13s0( v 1717'7190 (1436'5780,1717'7190] local-lis/les=1724/1725 n=5 ec=206/206 lis/c=1724/1705 les/c/f=1725/1709/0 sis=1727 pruub=0.266415042s) [49,23,37,NONE,36,22]p49(0) r=0 lpr=1727 pi=[1705,1727)/2 crt=1717'7190 lcod 1713'7189 mlcod 0'0 unknown pruub 6390.458094853s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.168+0800 7fd477523700 1 osd.49 pg_epoch: 1727 pg[3.25ds0( v 1711'7170 (1514'5778,1711'7170] local-lis/les=1716/1717 n=7 ec=206/206 lis/c=1716/1705 les/c/f=1717/1709/0 sis=1727 pruub=14.493144164s) [49,36,48,47,3,5]p49(0) r=0 lpr=1727 pi=[1705,1727)/1 crt=1711'7170 lcod 1711'7169 mlcod 0'0 unknown pruub 6404.685651330s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.169+0800 7fd473d1c700 1 osd.49 pg_epoch: 1727 pg[3.7as0( v 1711'7509 (1437'6075,1711'7509] local-lis/les=1724/1725 n=7 ec=206/206 lis/c=1724/1724 les/c/f=1725/1725/0 sis=1727 pruub=0.230683399s) [49,NONE,1,3,13,40]p49(0) r=0 lpr=1727 pi=[1724,1727)/1 crt=1711'7509 lcod 1711'7508 mlcod 0'0 unknown pruub 6390.423852523s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.169+0800 7fd47551f700 1 osd.49 pg_epoch: 1727 pg[3.15ds0( v 1711'7054 (1436'5627,1711'7054] local-lis/les=1724/1725 n=4 ec=206/206 lis/c=1724/1705 les/c/f=1725/1709/0 sis=1727 pruub=0.263895669s) [49,NONE,5,47,1,38]p49(0) r=0 lpr=1727 pi=[1705,1727)/2 crt=1711'7054 lcod 1711'7053 mlcod 0'0 unknown pruub 6390.457735905s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.171+0800 7fd473d1c700 1 osd.49 pg_epoch: 1727 pg[3.340s1( v 1717'6976 (1436'5500,1717'6976] local-lis/les=1724/1725 n=3 ec=206/206 lis/c=1724/1705 les/c/f=1725/1709/0 sis=1727) [NONE,49,22,37,38,10]p49(1) r=1 lpr=1727 pi=[1705,1727)/2 crt=1717'6976 lcod 1717'6975 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.173+0800 7fd47551f700 1 osd.49 pg_epoch: 1727 pg[3.22fs1( v 1725'6939 (1433'5500,1725'6939] local-lis/les=1724/1725 n=9 ec=206/206 lis/c=1724/1705 les/c/f=1725/1709/0 sis=1727) [NONE,49,NONE,36,22,37]p49(1) r=1 lpr=1727 pi=[1705,1727)/2 crt=1725'6939 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:39.957+0800 7fd478525700 1 osd.49 pg_epoch: 1730 pg[3.3f5s0( v 1711'7842 (1514'6426,1711'7842] local-lis/les=1721/1722 n=1 ec=206/206 lis/c=1721/1719 les/c/f=1722/1720/0 sis=1730 pruub=7.973734693s) [49,14,50,36,43,5]p49(0) r=0 lpr=1730 pi=[1719,1730)/1 crt=1711'7842 lcod 1711'7841 mlcod 0'0 unknown pruub 6416.955299085s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:39.961+0800 7fd478525700 1 osd.49 pg_epoch: 1730 pg[3.1cfs0( v 1728'7134 (1436'5708,1728'7134] local-lis/les=1721/1722 n=6 ec=206/206 lis/c=1721/1705 les/c/f=1722/1709/0 sis=1730 pruub=8.001143714s) [49,50,10,37,14,22]p49(0) r=0 lpr=1730 pi=[1705,1730)/1 crt=1728'7134 lcod 1717'7133 mlcod 0'0 unknown pruub 6416.986505162s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:39.963+0800 7fd479527700 1 osd.49 pg_epoch: 1730 pg[3.286s0( v 1711'7232 (1437'5793,1711'7232] local-lis/les=1721/1722 n=4 ec=206/206 lis/c=1721/1719 les/c/f=1722/1720/0 sis=1730 pruub=7.975275327s) [49,14,43,50,31,36]p49(0) r=0 lpr=1730 pi=[1719,1730)/1 crt=1711'7232 lcod 1711'7231 mlcod 0'0 unknown pruub 6416.962290636s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:39.967+0800 7fd474d1e700 1 osd.49 pg_epoch: 1730 pg[3.30cs0( v 1711'7012 (1441'5570,1711'7012] local-lis/les=1727/1728 n=4 ec=206/206 lis/c=1727/1705 les/c/f=1728/1709/0 sis=1730 pruub=14.248222709s) [49,NONE,22,14,37,36]p49(0) r=0 lpr=1730 pi=[1705,1730)/2 crt=1711'7012 lcod 1711'7011 mlcod 0'0 unknown pruub 6423.239806178s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:39.968+0800 7fd477d24700 1 osd.49 pg_epoch: 1730 pg[3.356s0( v 1725'7113 (1437'5676,1725'7113] local-lis/les=1727/1728 n=9 ec=206/206 lis/c=1727/1706 les/c/f=1728/1709/0 sis=1730 pruub=14.391752598s) [49,NONE,47,18,14,31]p49(0) r=0 lpr=1730 pi=[1706,1730)/1 crt=1725'7113 lcod 1725'7112 mlcod 0'0 unknown pruub 6423.384479984s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:39.974+0800 7fd47551f700 1 osd.49 pg_epoch: 1730 pg[3.22fs1( v 1728'6940 (1433'5500,1728'6940] local-lis/les=1727/1728 n=9 ec=206/206 lis/c=1727/1705 les/c/f=1728/1709/0 sis=1730 pruub=14.272295043s) [NONE,49,14,36,22,37]p49(1) r=1 lpr=1730 pi=[1705,1730)/2 crt=1728'6940 lcod 1725'6939 mlcod 0'0 unknown pruub 6423.270580834s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.924+0800 7fd479d28700 1 osd.49 pg_epoch: 1733 pg[3.30cs0( v 1711'7012 (1441'5570,1711'7012] local-lis/les=1730/1731 n=4 ec=206/206 lis/c=1730/1705 les/c/f=1731/1709/0 sis=1733 pruub=12.158817025s) [49,44,22,14,37,36]p49(0) r=0 lpr=1733 pi=[1705,1733)/2 crt=1711'7012 lcod 1711'7011 mlcod 0'0 unknown pruub 6442.108464591s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.924+0800 7fd478525700 1 osd.49 pg_epoch: 1733 pg[3.346s0( v 1717'7436 (1514'6018,1717'7436] local-lis/les=1727/1728 n=4 ec=206/206 lis/c=1727/1706 les/c/f=1728/1709/0 sis=1733 pruub=9.309413454s) [49,43,44,22,23,27]p49(0) r=0 lpr=1733 pi=[1706,1733)/1 crt=1717'7436 lcod 1717'7435 mlcod 0'0 unknown pruub 6439.259332793s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.925+0800 7fd476521700 1 osd.49 pg_epoch: 1733 pg[3.7as0( v 1711'7509 (1437'6075,1711'7509] local-lis/les=1727/1728 n=7 ec=206/206 lis/c=1727/1724 les/c/f=1728/1725/0 sis=1733 pruub=9.298105913s) [49,44,1,3,13,40]p49(0) r=0 lpr=1733 pi=[1724,1733)/1 crt=1711'7509 lcod 1711'7508 mlcod 0'0 unknown pruub 6439.248528815s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.926+0800 7fd47551f700 1 osd.49 pg_epoch: 1733 pg[3.13s0( v 1717'7190 (1436'5780,1717'7190] local-lis/les=1727/1728 n=5 ec=206/206 lis/c=1727/1705 les/c/f=1728/1709/0 sis=1733 pruub=9.319159902s) [49,23,37,44,36,22]p49(0) r=0 lpr=1733 pi=[1705,1733)/1 crt=1717'7190 lcod 1713'7189 mlcod 0'0 unknown pruub 6439.270355428s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.927+0800 7fd478525700 1 osd.49 pg_epoch: 1733 pg[3.1bbs0( v 1732'6623 (1432'5207,1732'6623] local-lis/les=1727/1728 n=8 ec=206/206 lis/c=1727/1704 les/c/f=1728/1707/0 sis=1733 pruub=9.426526441s) [49,18,44,13,47,32]p49(0) r=0 lpr=1733 pi=[1704,1733)/2 crt=1732'6623 lcod 1732'6622 mlcod 0'0 unknown pruub 6439.379179384s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.928+0800 7fd477d24700 1 osd.49 pg_epoch: 1733 pg[3.356s0( v 1725'7113 (1437'5676,1725'7113] local-lis/les=1730/1731 n=9 ec=206/206 lis/c=1730/1706 les/c/f=1731/1709/0 sis=1733 pruub=12.155126028s) [49,44,47,18,14,31]p49(0) r=0 lpr=1733 pi=[1706,1733)/2 crt=1725'7113 lcod 1725'7112 mlcod 0'0 unknown pruub 6442.108659290s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.935+0800 7fd477d24700 1 osd.49 pg_epoch: 1733 pg[3.20cs0( v 1731'7631 (1438'6246,1731'7631] local-lis/les=1727/1728 n=7 ec=206/206 lis/c=1727/1704 les/c/f=1728/1707/0 sis=1733 pruub=9.424873799s) [49,38,27,13,44,47]p49(0) r=0 lpr=1733 pi=[1704,1733)/2 crt=1731'7631 lcod 1731'7630 mlcod 0'0 unknown pruub 6439.385268036s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.937+0800 7fd477d24700 1 osd.49 pg_epoch: 1733 pg[3.15ds0( v 1711'7054 (1436'5627,1711'7054] local-lis/les=1727/1728 n=4 ec=206/206 lis/c=1727/1705 les/c/f=1728/1709/0 sis=1733 pruub=9.304974685s) [49,44,5,47,1,38]p49(0) r=0 lpr=1733 pi=[1705,1733)/2 crt=1711'7054 lcod 1711'7053 mlcod 0'0 unknown pruub 6439.267919522s@ mbc={}] state<Start>: transitioning to Primary
Updated by jianwei zhang about 2 years ago
[root@jianwei 10.128.130.71]# cat pg-unfound/3.356.pg.map
osdmap e1786 pg 3.356 (3.356) -> up [49,44,47,18,14,31] acting [49,44,47,18,14,31]
3.356s0 osd.49
[root@jianwei ceph]# grep 'transitioning to Primary' ceph-osd.49.log-20220308|grep '3\.356s'
2022-03-07T04:43:05.767+0800 7f3e1a7f6700 1 osd.49 pg_epoch: 752 pg[3.356s0( v 714'3263 (470'1800,714'3263] local-lis/les=686/687 n=2 ec=206/206 lis/c=686/686 les/c/f=687/710/0 sis=752) [49,44,47,18,14,31]p49(0) r=0 lpr=752 pi=[686,752)/1 crt=714'3263 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:13:52.110+0800 7f3e17ff1700 1 osd.49 pg_epoch: 756 pg[3.356s0( v 755'3477 (499'2000,755'3477] local-lis/les=752/753 n=0 ec=206/206 lis/c=752/752 les/c/f=753/754/0 sis=756 pruub=3.387825013s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=756 pi=[752,756)/1 crt=755'3477 lcod 755'3476 mlcod 0'0 unknown pruub 1876.590044324s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:20:02.519+0800 7f3e1a7f6700 1 osd.49 pg_epoch: 779 pg[3.356s0( v 760'3547 (551'2100,760'3547] local-lis/les=756/757 n=6 ec=206/206 lis/c=756/752 les/c/f=757/754/0 sis=779 pruub=15.047071016s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=779 pi=[752,779)/1 crt=760'3547 lcod 760'3546 mlcod 0'0 unknown pruub 2258.658375667s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:20:05.745+0800 7f3e17ff1700 1 osd.49 pg_epoch: 782 pg[3.356s0( v 760'3547 (551'2100,760'3547] local-lis/les=779/780 n=6 ec=206/206 lis/c=779/752 les/c/f=780/754/0 sis=782 pruub=14.359355389s) [49,44,47,18,14,31]p49(0) r=0 lpr=782 pi=[752,782)/1 crt=760'3547 lcod 760'3546 mlcod 0'0 unknown pruub 2261.196691521s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:36:35.710+0800 7f3e157ec700 1 osd.49 pg_epoch: 883 pg[3.356s0( v 882'3610 (578'2200,882'3610] local-lis/les=782/783 n=0 ec=206/206 lis/c=782/782 les/c/f=783/855/0 sis=883 pruub=3.334171732s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=883 pi=[782,883)/1 crt=882'3610 lcod 882'3609 mlcod 0'0 unknown pruub 3240.135984937s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:40:08.198+0800 7f3e1a7f6700 1 osd.49 pg_epoch: 898 pg[3.356s0( v 888'3614 (578'2200,888'3614] local-lis/les=883/884 n=1 ec=206/206 lis/c=883/782 les/c/f=884/855/0 sis=898 pruub=12.471105861s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=898 pi=[782,898)/1 crt=888'3614 lcod 888'3613 mlcod 0'0 unknown pruub 3461.760442011s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:40:09.237+0800 7f3e157ec700 1 osd.49 pg_epoch: 899 pg[3.356s0( v 888'3614 (578'2200,888'3614] local-lis/les=883/884 n=1 ec=206/206 lis/c=883/782 les/c/f=884/855/0 sis=899) [49,44,47,18,14,31]p49(0) r=0 lpr=899 pi=[782,899)/1 crt=888'3614 lcod 888'3613 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:41:01.292+0800 7f3e17ff1700 1 osd.49 pg_epoch: 903 pg[3.356s0( v 888'3614 (578'2200,888'3614] local-lis/les=899/900 n=1 ec=206/206 lis/c=899/899 les/c/f=900/902/0 sis=903 pruub=5.092500613s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=903 pi=[899,903)/1 crt=888'3614 lcod 888'3613 mlcod 0'0 unknown pruub 3507.477443987s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:44:19.815+0800 7f3e17ff1700 1 osd.49 pg_epoch: 915 pg[3.356s0( v 888'3614 (578'2200,888'3614] local-lis/les=903/904 n=1 ec=206/206 lis/c=903/899 les/c/f=904/902/0 sis=915 pruub=10.527068917s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=915 pi=[899,915)/1 crt=888'3614 lcod 888'3613 mlcod 0'0 unknown pruub 3711.434036785s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T05:44:20.976+0800 7f3e1a7f6700 1 osd.49 pg_epoch: 916 pg[3.356s0( v 888'3614 (578'2200,888'3614] local-lis/les=903/904 n=1 ec=206/206 lis/c=903/899 les/c/f=904/902/0 sis=916) [49,44,47,18,14,31]p49(0) r=0 lpr=916 pi=[899,916)/1 crt=888'3614 lcod 888'3613 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:22:47.590+0800 7fed89f80700 1 osd.49 pg_epoch: 955 pg[3.356s0( v 921'3815 (611'2400,921'3815] local-lis/les=916/917 n=2 ec=206/206 lis/c=916/916 les/c/f=917/917/0 sis=955) [49,44,47,18,14,31]p49(0) r=0 lpr=955 pi=[916,955)/1 crt=921'3815 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:27:23.594+0800 7ffa08b9d700 1 osd.49 pg_epoch: 962 pg[3.356s0( v 926'3819 lc 926'3818 (611'2400,926'3819] local-lis/les=955/956 n=3 ec=206/206 lis/c=955/916 les/c/f=956/917/0 sis=955 pruub=12.899344440s) [49,44,47,18,14,31]p49(0) r=0 lpr=956 pi=[916,955)/1 crt=926'3819 lcod 0'0 mlcod 0'0 unknown m=1 mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:27:24.699+0800 7ffa0b3a2700 1 osd.49 pg_epoch: 982 pg[3.356s0( v 926'3819 lc 926'3818 (611'2400,926'3819] local-lis/les=955/956 n=3 ec=206/206 lis/c=955/916 les/c/f=956/917/0 sis=982) [49,44,47,NONE,14,31]p49(0) r=0 lpr=982 pi=[916,982)/1 crt=926'3819 lcod 0'0 mlcod 0'0 unknown m=1 mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:27:25.799+0800 7ffa0b3a2700 1 osd.49 pg_epoch: 983 pg[3.356s0( v 967'3834 lc 926'3818 (611'2400,967'3834] local-lis/les=963/964 n=0 ec=206/206 lis/c=963/916 les/c/f=964/917/0 sis=983) [49,44,47,18,14,31]p49(0) r=0 lpr=983 pi=[916,983)/1 crt=967'3834 lcod 0'0 mlcod 0'0 unknown m=3 mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:37:34.974+0800 7f7f5809f700 1 osd.49 pg_epoch: 1002 pg[3.356s0( v 967'3834 (611'2400,967'3834] local-lis/les=983/984 n=0 ec=206/206 lis/c=983/983 les/c/f=984/985/0 sis=1002) [49,44,47,NONE,14,31]p49(0) r=0 lpr=1002 pi=[983,1002)/1 crt=967'3834 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:37:36.143+0800 7f7f5809f700 1 osd.49 pg_epoch: 1003 pg[3.356s0( v 967'3834 (611'2400,967'3834] local-lis/les=986/987 n=0 ec=206/206 lis/c=986/983 les/c/f=987/985/0 sis=1003) [49,44,47,18,14,31]p49(0) r=0 lpr=1003 pi=[983,1003)/1 crt=967'3834 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:55:44.403+0800 7f7f5809f700 1 osd.49 pg_epoch: 1017 pg[3.356s0( v 1005'3847 (611'2400,1005'3847] local-lis/les=1003/1004 n=0 ec=206/206 lis/c=1003/1003 les/c/f=1004/1004/0 sis=1017) [49,44,47,NONE,14,31]p49(0) r=0 lpr=1017 pi=[1003,1017)/1 crt=1005'3847 lcod 1005'3846 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:55:45.441+0800 7f7f5809f700 1 osd.49 pg_epoch: 1018 pg[3.356s0( v 1014'3875 lc 1005'3847 (611'2400,1014'3875] local-lis/les=1010/1011 n=5 ec=206/206 lis/c=1010/1003 les/c/f=1011/1004/0 sis=1018) [49,44,47,18,14,31]p49(0) r=0 lpr=1018 pi=[1003,1018)/1 crt=1014'3875 lcod 1005'3846 mlcod 0'0 unknown m=6 mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:06:58.800+0800 7f5fb15bb700 1 osd.49 pg_epoch: 1059 pg[3.356s0( v 1036'3913 (653'2500,1036'3913] local-lis/les=1018/1019 n=4 ec=206/206 lis/c=1018/1018 les/c/f=1019/1030/0 sis=1059) [49,44,47,18,14,31]p49(0) r=0 lpr=1059 pi=[1018,1059)/1 crt=1036'3913 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:12:07.207+0800 7f7da4232700 1 osd.49 pg_epoch: 1075 pg[3.356s0( v 1061'3931 (653'2500,1061'3931] local-lis/les=1059/1060 n=8 ec=206/206 lis/c=1059/1059 les/c/f=1060/1061/0 sis=1075) [49,44,47,18,14,31]p49(0) r=0 lpr=1075 pi=[1059,1075)/1 crt=1061'3931 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:21:05.210+0800 7f5f31fd2700 1 osd.49 pg_epoch: 1094 pg[3.356s0( v 1077'3961 (653'2500,1077'3961] local-lis/les=1075/1076 n=1 ec=206/206 lis/c=1075/1075 les/c/f=1076/1077/0 sis=1094) [49,44,47,NONE,14,31]p49(0) r=0 lpr=1094 pi=[1075,1094)/1 crt=1077'3961 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:21:06.175+0800 7f5f36fdc700 1 osd.49 pg_epoch: 1095 pg[3.356s0( v 1084'3972 lc 1077'3961 (653'2500,1084'3972] local-lis/les=1078/1079 n=3 ec=206/206 lis/c=1078/1075 les/c/f=1079/1077/0 sis=1095) [49,44,47,18,14,31]p49(0) r=0 lpr=1095 pi=[1075,1095)/1 crt=1084'3972 lcod 0'0 mlcod 0'0 unknown m=3 mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:28:15.698+0800 7f5f31fd2700 1 osd.49 pg_epoch: 1105 pg[3.356s0( v 1104'3975 (653'2500,1104'3975] local-lis/les=1095/1096 n=0 ec=206/206 lis/c=1095/1095 les/c/f=1096/1104/0 sis=1105 pruub=4.404266455s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=1105 pi=[1095,1105)/1 crt=1104'3975 mlcod 0'0 unknown pruub 463.006552918s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:32:28.964+0800 7f5f31fd2700 1 osd.49 pg_epoch: 1125 pg[3.356s0( v 1121'3983 (653'2600,1121'3983] local-lis/les=1105/1106 n=2 ec=206/206 lis/c=1105/1095 les/c/f=1106/1104/0 sis=1125 pruub=11.775467522s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=1125 pi=[1095,1125)/1 crt=1121'3983 lcod 1121'3982 mlcod 0'0 unknown pruub 725.002598214s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:32:33.253+0800 7f5f347d7700 1 osd.49 pg_epoch: 1129 pg[3.356s0( v 1121'3983 (653'2600,1121'3983] local-lis/les=1125/1126 n=2 ec=206/206 lis/c=1125/1095 les/c/f=1126/1104/0 sis=1129 pruub=12.909403206s) [49,44,47,18,14,31]p49(0) r=0 lpr=1129 pi=[1095,1129)/1 crt=1121'3983 lcod 1121'3982 mlcod 0'0 unknown pruub 730.424547163s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T08:23:16.035+0800 7f78d1596700 1 osd.49 pg_epoch: 1143 pg[3.356s0( v 1142'4181 (653'2700,1142'4181] local-lis/les=1129/1130 n=0 ec=206/206 lis/c=1129/1129 les/c/f=1130/1136/0 sis=1129) [49,44,47,18,14,31]p49(0) r=0 lpr=1142 crt=1142'4181 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T08:23:17.060+0800 7f78ced91700 1 osd.49 pg_epoch: 1168 pg[3.356s0( v 1142'4181 (653'2700,1142'4181] local-lis/les=1129/1130 n=0 ec=206/206 lis/c=1129/1129 les/c/f=1130/1136/0 sis=1168) [49,44,47,NONE,14,31]p49(0) r=0 lpr=1168 pi=[1129,1168)/1 crt=1142'4181 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T08:23:18.972+0800 7f78ced91700 1 osd.49 pg_epoch: 1170 pg[3.356s0( v 1150'4214 lc 1148'4184 (653'2700,1150'4214] local-lis/les=1168/1169 n=4 ec=206/206 lis/c=1168/1129 les/c/f=1169/1136/0 sis=1170 pruub=15.289489036s) [49,44,47,18,14,31]p49(0) r=0 lpr=1170 pi=[1129,1170)/1 crt=1150'4214 lcod 0'0 mlcod 0'0 unknown pruub 47.249660001s@ m=4 mbc={}] state<Start>: transitioning to Primary
2022-03-07T08:28:16.512+0800 7f78ced91700 1 osd.49 pg_epoch: 1263 pg[3.356s0( v 1205'4227 (691'2832,1205'4227] local-lis/les=1170/1171 n=0 ec=206/206 lis/c=1170/1170 les/c/f=1171/1250/0 sis=1263) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=1263 pi=[1170,1263)/1 crt=1205'4227 lcod 1205'4226 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T08:33:05.734+0800 7f78d1596700 1 osd.49 pg_epoch: 1271 pg[3.356s0( v 1270'4235 (691'2832,1270'4235] local-lis/les=1263/1264 n=2 ec=206/206 lis/c=1263/1170 les/c/f=1264/1250/0 sis=1271 pruub=7.983456401s) [49,44,NONE,18,14,31]p49(0) r=0 lpr=1271 pi=[1170,1271)/1 crt=1270'4235 lcod 1270'4234 mlcod 0'0 unknown pruub 626.710077004s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T08:33:06.090+0800 7f78ced91700 1 osd.49 pg_epoch: 1272 pg[3.356s0( v 1270'4235 (691'2832,1270'4235] local-lis/les=1263/1264 n=2 ec=206/206 lis/c=1263/1170 les/c/f=1264/1250/0 sis=1272) [49,44,47,18,14,31]p49(0) r=0 lpr=1272 pi=[1170,1272)/1 crt=1270'4235 lcod 1270'4234 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T09:15:24.806+0800 7fd7efaae700 1 osd.49 pg_epoch: 1288 pg[3.356s0( v 1287'4342 (712'2932,1287'4342] local-lis/les=1272/1273 n=0 ec=206/206 lis/c=1272/1272 les/c/f=1273/1287/0 sis=1272) [49,44,47,18,14,31]p49(0) r=0 lpr=1287 crt=1287'4342 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T09:15:25.772+0800 7fd7ed2a9700 1 osd.49 pg_epoch: 1311 pg[3.356s0( v 1287'4342 (712'2932,1287'4342] local-lis/les=1272/1273 n=0 ec=206/206 lis/c=1272/1272 les/c/f=1273/1287/0 sis=1311) [49,44,47,18,14,31]p49(0) r=0 lpr=1311 pi=[1272,1311)/1 crt=1287'4342 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T10:08:22.740+0800 7fd7ed2a9700 1 osd.49 pg_epoch: 1368 pg[3.356s0( v 1359'4631 (714'3232,1359'4631] local-lis/les=1311/1312 n=0 ec=206/206 lis/c=1311/1311 les/c/f=1312/1319/0 sis=1368) [49,44,47,NONE,14,31]p49(0) r=0 lpr=1368 pi=[1311,1368)/1 crt=1359'4631 lcod 1359'4630 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T10:08:24.723+0800 7fd7ed2a9700 1 osd.49 pg_epoch: 1370 pg[3.356s0( v 1367'4639 lc 1367'4634 (714'3232,1367'4639] local-lis/les=1368/1369 n=2 ec=206/206 lis/c=1361/1311 les/c/f=1362/1319/0 sis=1370) [49,44,47,18,14,31]p49(0) r=0 lpr=1370 pi=[1311,1370)/1 crt=1367'4639 lcod 1359'4630 mlcod 0'0 unknown m=2 mbc={}] state<Start>: transitioning to Primary
2022-03-07T11:53:19.931+0800 7f22101b6700 1 osd.49 pg_epoch: 1402 pg[3.356s0( v 1375'5216 (967'3832,1375'5216] local-lis/les=1370/1371 n=3 ec=206/206 lis/c=1370/1370 les/c/f=1371/1373/0 sis=1402) [49,44,47,NONE,14,31]p49(0) r=0 lpr=1402 pi=[1370,1402)/1 crt=1375'5216 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T11:53:21.966+0800 7f220d9b1700 1 osd.49 pg_epoch: 1404 pg[3.356s0( v 1396'5234 lc 1381'5217 (967'3832,1396'5234] local-lis/les=1402/1403 n=3 ec=206/206 lis/c=1402/1370 les/c/f=1403/1373/0 sis=1404 pruub=15.162469524s) [49,44,47,18,14,31]p49(0) r=0 lpr=1404 pi=[1370,1404)/1 crt=1396'5234 lcod 0'0 mlcod 0'0 unknown pruub 48.431984952s@ m=2 mbc={}] state<Start>: transitioning to Primary
2022-03-07T12:04:03.899+0800 7f22129bb700 1 osd.49 pg_epoch: 1420 pg[3.356s0( v 1412'5250 (967'3832,1412'5250] local-lis/les=1404/1405 n=0 ec=206/206 lis/c=1404/1404 les/c/f=1405/1408/0 sis=1420) [49,44,47,18,14,31]p49(0) r=0 lpr=1420 pi=[1404,1420)/1 crt=1412'5250 lcod 1412'5249 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T13:35:10.023+0800 7f220d9b1700 1 osd.49 pg_epoch: 1440 pg[3.356s0( v 1438'5804 (1287'4332,1438'5804] local-lis/les=1420/1421 n=0 ec=206/206 lis/c=1420/1420 les/c/f=1421/1428/0 sis=1440 pruub=0.014617768s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=1440 pi=[1420,1440)/1 crt=1438'5804 lcod 1438'5803 mlcod 0'0 unknown pruub 6141.340736276s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T13:40:37.055+0800 7f22101b6700 1 osd.49 pg_epoch: 1467 pg[3.356s0( v 1441'5827 (1357'4432,1441'5827] local-lis/les=1440/1441 n=3 ec=206/206 lis/c=1440/1420 les/c/f=1441/1428/0 sis=1467 pruub=9.936245401s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=1467 pi=[1420,1467)/1 crt=1441'5827 lcod 1441'5826 mlcod 0'0 unknown pruub 6478.295605916s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T13:40:46.787+0800 7f220d9b1700 1 osd.49 pg_epoch: 1476 pg[3.356s0( v 1441'5827 (1357'4432,1441'5827] local-lis/les=1467/1468 n=3 ec=206/206 lis/c=1467/1420 les/c/f=1468/1428/0 sis=1476 pruub=14.838306375s) [49,44,47,18,14,31]p49(0) r=0 lpr=1476 pi=[1420,1476)/1 crt=1441'5827 lcod 1441'5826 mlcod 0'0 unknown pruub 6492.930267081s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T13:56:57.036+0800 7f220d9b1700 1 osd.49 pg_epoch: 1515 pg[3.356s0( v 1514'5856 (1357'4432,1514'5856] local-lis/les=1476/1477 n=2 ec=206/206 lis/c=1476/1476 les/c/f=1477/1495/0 sis=1515) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=1515 pi=[1476,1515)/1 crt=1514'5856 lcod 1514'5855 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:00:31.803+0800 7f22101b6700 1 osd.49 pg_epoch: 1530 pg[3.356s0( v 1518'5860 (1357'4432,1518'5860] local-lis/les=1515/1516 n=3 ec=206/206 lis/c=1515/1476 les/c/f=1516/1495/0 sis=1530 pruub=10.155194583s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=1530 pi=[1476,1530)/1 crt=1518'5860 lcod 1518'5859 mlcod 0'0 unknown pruub 7673.261751322s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:00:32.940+0800 7f220d9b1700 1 osd.49 pg_epoch: 1531 pg[3.356s0( v 1518'5860 (1357'4432,1518'5860] local-lis/les=1515/1516 n=3 ec=206/206 lis/c=1515/1476 les/c/f=1516/1495/0 sis=1531) [49,44,47,18,14,31]p49(0) r=0 lpr=1531 pi=[1476,1531)/1 crt=1518'5860 lcod 1518'5859 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:01:22.423+0800 7f22129bb700 1 osd.49 pg_epoch: 1535 pg[3.356s0( v 1518'5860 (1357'4432,1518'5860] local-lis/les=1531/1532 n=3 ec=206/206 lis/c=1531/1476 les/c/f=1532/1495/0 sis=1535) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=1535 pi=[1476,1535)/1 crt=1518'5860 lcod 1518'5859 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:05:20.841+0800 7f22129bb700 1 osd.49 pg_epoch: 1549 pg[3.356s0( v 1538'5863 (1357'4432,1538'5863] local-lis/les=1535/1536 n=0 ec=206/206 lis/c=1535/1476 les/c/f=1536/1495/0 sis=1549 pruub=10.578262840s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=1549 pi=[1476,1549)/1 crt=1538'5863 lcod 1538'5862 mlcod 0'0 unknown pruub 7962.723704073s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:05:21.877+0800 7f22101b6700 1 osd.49 pg_epoch: 1550 pg[3.356s0( v 1538'5863 (1357'4432,1538'5863] local-lis/les=1535/1536 n=0 ec=206/206 lis/c=1535/1476 les/c/f=1536/1495/0 sis=1550) [49,44,47,18,14,31]p49(0) r=0 lpr=1550 pi=[1476,1550)/1 crt=1538'5863 lcod 1538'5862 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:10:07.019+0800 7f22101b6700 1 osd.49 pg_epoch: 1553 pg[3.356s0( v 1552'5871 (1357'4432,1552'5871] local-lis/les=1550/1551 n=2 ec=206/206 lis/c=1550/1550 les/c/f=1551/1552/0 sis=1553 pruub=4.499744547s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=1553 pi=[1550,1553)/1 crt=1552'5871 lcod 1552'5870 mlcod 0'0 unknown pruub 8242.823273815s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:13:28.176+0800 7f220d9b1700 1 osd.49 pg_epoch: 1570 pg[3.356s0( v 1557'5888 (1357'4432,1557'5888] local-lis/les=1553/1554 n=6 ec=206/206 lis/c=1553/1550 les/c/f=1554/1552/0 sis=1570 pruub=7.956085356s) [49,44,47,18,14,31]p49(0) r=0 lpr=1570 pi=[1550,1570)/1 crt=1557'5888 lcod 1557'5887 mlcod 0'0 unknown pruub 8447.436389261s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:14:31.711+0800 7f22129bb700 1 osd.49 pg_epoch: 1573 pg[3.356s0( v 1572'5895 (1357'4432,1572'5895] local-lis/les=1570/1571 n=6 ec=206/206 lis/c=1570/1550 les/c/f=1571/1552/0 sis=1573 pruub=2.000026611s) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=1573 pi=[1550,1573)/1 crt=1572'5895 lcod 1572'5894 mlcod 0'0 unknown pruub 8505.013889707s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T14:17:51.170+0800 7f22101b6700 1 osd.49 pg_epoch: 1588 pg[3.356s0( v 1576'5913 (1357'4432,1576'5913] local-lis/les=1573/1574 n=6 ec=206/206 lis/c=1573/1550 les/c/f=1574/1552/0 sis=1588 pruub=9.387071094s) [49,44,47,18,14,31]p49(0) r=0 lpr=1588 pi=[1550,1588)/1 crt=1576'5913 lcod 1576'5912 mlcod 0'0 unknown pruub 8711.861862160s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T16:03:18.699+0800 7fd47551f700 1 osd.49 pg_epoch: 1615 pg[3.356s0( v 1595'6387 (1373'4932,1595'6387] local-lis/les=1588/1589 n=0 ec=206/206 lis/c=1588/1588 les/c/f=1589/1589/0 sis=1615) [49,44,47,NONE,14,31]p49(0) r=0 lpr=1615 pi=[1588,1615)/1 crt=1595'6387 lcod 0'0 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T16:03:25.916+0800 7fd472d1a700 1 osd.49 pg_epoch: 1622 pg[3.356s0( v 1614'6458 lc 1598'6425 (1373'4932,1614'6458] local-lis/les=1615/1616 n=8 ec=206/206 lis/c=1615/1588 les/c/f=1616/1589/0 sis=1622 pruub=10.184004930s) [49,44,47,18,14,31]p49(0) r=0 lpr=1622 pi=[1588,1622)/1 crt=1614'6458 lcod 0'0 mlcod 0'0 unknown pruub 45.125538477s@ m=8 mbc={}] state<Start>: transitioning to Primary
2022-03-07T16:36:45.767+0800 7fd477d24700 1 osd.49 pg_epoch: 1656 pg[3.356s0( v 1647'6598 (1374'5176,1647'6598] local-lis/les=1622/1623 n=0 ec=206/206 lis/c=1622/1622 les/c/f=1623/1644/0 sis=1656) [49,44,47,18,14,31]p49(0) r=0 lpr=1656 pi=[1622,1656)/1 crt=1647'6598 lcod 1647'6597 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:04:09.568+0800 7fd47551f700 1 osd.49 pg_epoch: 1674 pg[3.356s0( v 1673'6773 (1432'5376,1673'6773] local-lis/les=1656/1657 n=0 ec=206/206 lis/c=1656/1656 les/c/f=1657/1663/0 sis=1674) [49,44,NONE,18,14,NONE]p49(0) r=0 lpr=1674 pi=[1656,1674)/1 crt=1673'6773 lcod 1673'6772 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:10:21.513+0800 7fd47551f700 1 osd.49 pg_epoch: 1701 pg[3.356s0( v 1695'6815 (1432'5376,1695'6815] local-lis/les=1674/1675 n=11 ec=206/206 lis/c=1674/1656 les/c/f=1675/1663/0 sis=1701 pruub=13.214422459s) [49,44,47,18,14,NONE]p49(0) r=0 lpr=1701 pi=[1656,1701)/1 crt=1695'6815 lcod 1695'6814 mlcod 0'0 unknown pruub 4063.751950218s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:10:27.063+0800 7fd477d24700 1 osd.49 pg_epoch: 1706 pg[3.356s0( v 1695'6815 (1432'5376,1695'6815] local-lis/les=1701/1702 n=11 ec=206/206 lis/c=1701/1656 les/c/f=1702/1663/0 sis=1706 pruub=11.732252029s) [49,44,47,18,14,31]p49(0) r=0 lpr=1706 pi=[1656,1706)/1 crt=1695'6815 lcod 1695'6814 mlcod 0'0 unknown pruub 4067.820660932s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:47:52.170+0800 7fd472d1a700 1 osd.49 pg_epoch: 1712 pg[3.356s0( v 1711'7107 (1437'5676,1711'7107] local-lis/les=1706/1707 n=9 ec=206/206 lis/c=1706/1706 les/c/f=1707/1709/0 sis=1712 pruub=4.391165257s) [49,44,47,18,NONE,31]p49(0) r=0 lpr=1712 pi=[1706,1712)/1 crt=1711'7107 lcod 1711'7106 mlcod 0'0 unknown pruub 6305.584885278s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:17.583+0800 7fd472d1a700 1 osd.49 pg_epoch: 1714 pg[3.356s0( v 1711'7107 (1437'5676,1711'7107] local-lis/les=1712/1713 n=9 ec=206/206 lis/c=1712/1706 les/c/f=1713/1709/0 sis=1714) [49,NONE,47,18,NONE,31]p49(0) r=0 lpr=1714 pi=[1706,1714)/1 crt=1711'7107 lcod 1711'7106 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:30.490+0800 7fd47551f700 1 osd.49 pg_epoch: 1716 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1716 pruub=4.332741706s) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1716 pi=[1706,1716)/1 crt=1715'7109 lcod 1715'7108 mlcod 0'0 unknown pruub 6343.848557841s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:44.378+0800 7fd47551f700 1 osd.49 pg_epoch: 1719 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1719) [49,NONE,NONE,18,14,31]p49(0) r=0 lpr=1719 pi=[1706,1719)/1 crt=1715'7109 lcod 1715'7108 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.819+0800 7fd472d1a700 1 osd.49 pg_epoch: 1721 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1721 pruub=2.823632061s) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1721 pi=[1706,1721)/1 crt=1720'7111 lcod 1715'7110 mlcod 0'0 unknown pruub 6370.667211529s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.114+0800 7fd47551f700 1 osd.49 pg_epoch: 1724 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1724) [49,44,NONE,18,NONE,31]p49(0) r=0 lpr=1724 pi=[1706,1724)/1 crt=1720'7111 lcod 1715'7110 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:21.165+0800 7fd472d1a700 1 osd.49 pg_epoch: 1727 pg[3.356s0( v 1725'7113 (1437'5676,1725'7113] local-lis/les=1724/1725 n=9 ec=206/206 lis/c=1724/1706 les/c/f=1725/1709/0 sis=1727 pruub=0.272948061s) [49,NONE,47,18,NONE,31]p49(0) r=0 lpr=1727 pi=[1706,1727)/1 crt=1725'7113 lcod 1725'7112 mlcod 0'0 unknown pruub 6390.458642978s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:39.968+0800 7fd477d24700 1 osd.49 pg_epoch: 1730 pg[3.356s0( v 1725'7113 (1437'5676,1725'7113] local-lis/les=1727/1728 n=9 ec=206/206 lis/c=1727/1706 les/c/f=1728/1709/0 sis=1730 pruub=14.391752598s) [49,NONE,47,18,14,31]p49(0) r=0 lpr=1730 pi=[1706,1730)/1 crt=1725'7113 lcod 1725'7112 mlcod 0'0 unknown pruub 6423.384479984s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:50:00.928+0800 7fd477d24700 1 osd.49 pg_epoch: 1733 pg[3.356s0( v 1725'7113 (1437'5676,1725'7113] local-lis/les=1730/1731 n=9 ec=206/206 lis/c=1730/1706 les/c/f=1731/1709/0 sis=1733 pruub=12.155126028s) [49,44,47,18,14,31]p49(0) r=0 lpr=1733 pi=[1706,1733)/2 crt=1725'7113 lcod 1725'7112 mlcod 0'0 unknown pruub 6442.108659290s@ mbc={}] state<Start>: transitioning to Primary
3.356 s1 osd.44
[root@jianwei ceph]# grep 'transitioning to Primary' ceph-osd.44.log-20220308|grep '3\.356s'
2022-03-07T04:38:20.524+0800 7fe048eae700 1 osd.44 pg_epoch: 715 pg[3.356s1( v 714'3263 (470'1800,714'3263] local-lis/les=686/687 n=2 ec=206/206 lis/c=686/686 les/c/f=687/710/0 sis=715 pruub=2.975404717s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=715 pi=[686,715)/1 crt=714'3263 mlcod 0'0 unknown pruub 61302.687664491s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T04:42:45.437+0800 7fe0466a9700 1 osd.44 pg_epoch: 744 pg[3.356s1( v 718'3279 (470'1800,718'3279] local-lis/les=715/716 n=5 ec=206/206 lis/c=715/686 les/c/f=716/710/0 sis=744 pruub=8.149126257s) [NONE,44,47,18,14,31]p44(1) r=1 lpr=744 pi=[686,744)/1 crt=718'3279 lcod 718'3278 mlcod 0'0 unknown pruub 61572.775895016s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:19:08.696+0800 7fe0466a9700 1 osd.44 pg_epoch: 922 pg[3.356s1( v 921'3815 (611'2400,921'3815] local-lis/les=916/917 n=2 ec=206/206 lis/c=916/916 les/c/f=917/917/0 sis=922 pruub=1.439601099s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=922 pi=[916,922)/1 crt=921'3815 mlcod 0'0 unknown pruub 67349.323961255s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:23:53.271+0800 7fe0466a9700 1 osd.44 pg_epoch: 963 pg[3.356s1( v 926'3819 (611'2400,926'3819] local-lis/les=955/956 n=3 ec=206/206 lis/c=955/916 les/c/f=956/917/0 sis=963) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=963 pi=[916,963)/1 crt=926'3819 lcod 926'3818 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:31:14.566+0800 7fe048eae700 1 osd.44 pg_epoch: 986 pg[3.356s1( v 967'3834 (611'2400,967'3834] local-lis/les=983/984 n=0 ec=206/206 lis/c=983/983 les/c/f=984/985/0 sis=986 pruub=5.015776138s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=986 pi=[983,986)/1 crt=967'3834 lcod 967'3833 mlcod 0'0 unknown pruub 68078.771856717s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T06:50:54.093+0800 7fe048eae700 1 osd.44 pg_epoch: 1010 pg[3.356s1( v 1005'3847 (611'2400,1005'3847] local-lis/les=1003/1004 n=0 ec=206/206 lis/c=1003/1003 les/c/f=1004/1004/0 sis=1010) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1010 pi=[1003,1010)/1 crt=1005'3847 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:03:10.547+0800 7fe048eae700 1 osd.44 pg_epoch: 1037 pg[3.356s1( v 1036'3913 (653'2500,1036'3913] local-lis/les=1018/1019 n=4 ec=206/206 lis/c=1018/1018 les/c/f=1019/1030/0 sis=1037 pruub=4.516165934s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1037 pi=[1018,1037)/1 crt=1036'3913 mlcod 0'0 unknown pruub 69994.253224512s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:07:56.498+0800 7fe0466a9700 1 osd.44 pg_epoch: 1062 pg[3.356s1( v 1061'3931 (653'2500,1061'3931] local-lis/les=1059/1060 n=8 ec=206/206 lis/c=1059/1059 les/c/f=1060/1061/0 sis=1062) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1062 pi=[1059,1062)/1 crt=1061'3931 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:12:06.113+0800 7fe0466a9700 1 osd.44 pg_epoch: 1074 pg[3.356s1( v 1065'3957 (653'2500,1065'3957] local-lis/les=1062/1063 n=0 ec=206/206 lis/c=1062/1059 les/c/f=1063/1061/0 sis=1074 pruub=15.566190741s) [NONE,44,47,18,14,31]p44(1) r=1 lpr=1074 pi=[1059,1074)/1 crt=1065'3957 lcod 1065'3956 mlcod 0'0 unknown pruub 70540.868240779s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T07:16:51.108+0800 7fe0466a9700 1 osd.44 pg_epoch: 1078 pg[3.356s1( v 1077'3961 (653'2500,1077'3961] local-lis/les=1075/1076 n=1 ec=206/206 lis/c=1075/1075 les/c/f=1076/1077/0 sis=1078) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1078 pi=[1075,1078)/1 crt=1077'3961 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T08:17:08.315+0800 7fe048eae700 1 osd.44 pg_epoch: 1144 pg[3.356s1( v 1142'4181 (653'2700,1142'4181] local-lis/les=1129/1130 n=0 ec=206/206 lis/c=1129/1129 les/c/f=1130/1136/0 sis=1144 pruub=5.551545723s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1144 pi=[1129,1144)/1 crt=1142'4181 mlcod 0'0 unknown pruub 74434.377600285s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T09:08:44.571+0800 7fe04b6b3700 1 osd.44 pg_epoch: 1289 pg[3.356s1( v 1287'4342 (712'2932,1287'4342] local-lis/les=1272/1273 n=0 ec=206/206 lis/c=1272/1272 les/c/f=1273/1287/0 sis=1289 pruub=4.322712692s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1289 pi=[1272,1289)/1 crt=1287'4342 mlcod 0'0 unknown pruub 77529.404941274s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T09:15:24.127+0800 7fe0466a9700 1 osd.44 pg_epoch: 1309 pg[3.356s1( v 1306'4393 (712'2932,1306'4393] local-lis/les=1289/1290 n=5 ec=206/206 lis/c=1289/1272 les/c/f=1290/1287/0 sis=1309 pruub=9.373693711s) [NONE,44,47,18,14,31]p44(1) r=1 lpr=1309 pi=[1272,1309)/1 crt=1306'4393 lcod 1306'4392 mlcod 0'0 unknown pruub 77934.011658553s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T10:03:31.423+0800 7fe0466a9700 1 osd.44 pg_epoch: 1361 pg[3.356s1( v 1359'4631 (714'3232,1359'4631] local-lis/les=1311/1312 n=0 ec=206/206 lis/c=1311/1311 les/c/f=1312/1319/0 sis=1361) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1361 pi=[1311,1361)/1 crt=1359'4631 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T11:48:30.363+0800 7fe0466a9700 1 osd.44 pg_epoch: 1376 pg[3.356s1( v 1375'5216 (967'3832,1375'5216] local-lis/les=1370/1371 n=3 ec=206/206 lis/c=1370/1370 les/c/f=1371/1373/0 sis=1376 pruub=3.565702195s) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1376 pi=[1370,1376)/1 crt=1375'5216 mlcod 0'0 unknown pruub 87114.438955025s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T11:59:14.607+0800 7fe048eae700 1 osd.44 pg_epoch: 1414 pg[3.356s1( v 1412'5250 (967'3832,1412'5250] local-lis/les=1404/1405 n=0 ec=206/206 lis/c=1404/1404 les/c/f=1405/1408/0 sis=1414) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1414 pi=[1404,1414)/1 crt=1412'5250 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T12:04:02.882+0800 7fe04b6b3700 1 osd.44 pg_epoch: 1419 pg[3.356s1( v 1417'5274 (967'3832,1417'5274] local-lis/les=1414/1415 n=3 ec=206/206 lis/c=1414/1404 les/c/f=1415/1408/0 sis=1419 pruub=8.892279612s) [NONE,44,47,18,14,31]p44(1) r=1 lpr=1419 pi=[1404,1419)/1 crt=1417'5274 lcod 1417'5273 mlcod 0'0 unknown pruub 88052.285088204s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T15:57:32.152+0800 7fe0466a9700 1 osd.44 pg_epoch: 1596 pg[3.356s1( v 1595'6387 (1373'4932,1595'6387] local-lis/les=1588/1589 n=0 ec=206/206 lis/c=1588/1588 les/c/f=1589/1589/0 sis=1596) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1596 pi=[1588,1596)/1 crt=1595'6387 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T16:31:56.683+0800 7fe048eae700 1 osd.44 pg_epoch: 1650 pg[3.356s1( v 1647'6598 (1374'5176,1647'6598] local-lis/les=1622/1623 n=0 ec=206/206 lis/c=1622/1622 les/c/f=1623/1644/0 sis=1650) [NONE,44,47,NONE,14,31]p44(1) r=1 lpr=1650 pi=[1622,1650)/1 crt=1647'6598 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
3.356 s2 osd.47
[root@jianwei ceph]# grep 'transitioning to Primary' ceph-osd.47.log-20220308|grep '3\.356s'
[root@jianwei ceph]#
3.356 s3 osd.18
[root@jianwei ceph]# grep 'transitioning to Primary' ceph-osd.18.log-20220308|grep '3\.356s'
[root@jianwei ceph]#
3.356 s4 osd.14
[root@jianwei ceph]# grep 'transitioning to Primary' ceph-osd.14.log-20220308|grep '3\.356s'
[root@jianwei ceph]#
3.356 s5 osd.31
[root@jianwei ceph]# grep 'transitioning to Primary' ceph-osd.31.log-20220308|grep '3\.356s'
[root@jianwei ceph]#
Updated by jianwei zhang about 2 years ago
Radoslaw Zarzynski wrote:
the all osds is up&in, so the case doesn't involve recovery_unfound due to osd down.
A note from the bug scrub: this looks confusing. In the comment #22 a following info can be found:
[...]
which would mean that, at least for some time, 3 OSDs were down and this is enough to cause the issue.
Anyway, there is no another thing we can use to double check: the
can_rollback_to(aka.crtin the logs) value which is present in a log entry. Here is an example:[...]
Could you please provide similar entries for the affected PG?
Hi,
(1) my code version is ceph tag v15.2.13
commit c44bc49e7a57a87d84dfff2a077a2058aa2172e2 (HEAD, tag: v15.2.13)
Author: Jenkins <jenkins@ceph.com>
Date: Wed May 26 19:24:07 2021 +0000
15.2.13
(2) I found a patch (code branch octopus) for ec min_size and it can cause ec data inconsistent
commit 66dbd3d70935165eaba233908a55a1e356b8ac8b
Merge: 1642b6a1013 158916bd6a0
Author: Yuri Weinstein <yuriw@redhat.com>
Date: Tue Jun 22 10:20:47 2021 -0700
Merge pull request #41609 from dvanders/dvanders_40572_octopus
octopus: osd/PeeringState: fix acting_set_writeable min_size check
Reviewed-by: Neha Ojha <nojha@redhat.com>
Reviewed-by: Samuel Just <sjust@redhat.com>
commit 158916bd6a034f9fb43d125f0b62b008ed1b0794
Author: Samuel Just <sjust@redhat.com>
Date: Fri Apr 2 22:30:54 2021 +0000
osd/PeeringState: fix acting_set_writeable min_size check
acting.size() >= pool.info.min_size is meant to check min_size against
acting set participants, but acting is a vector with placeholders.
actingset is the representation with placeholders removed.
The upshot of this bug is that the activation process will basically
ignore min_size for an ec pool allowing writes in cases where it
shouldn't. PastIntervals::check_new_interval, however, performs
the check correctly, and will therefore discount intervals in which
we really did serve writes as not writeable. This can trigger many
different problem conditions including but not limited to:
- Unfound objects due to accepting a last_update with insufficient
osds
- Lost writes
- Crashes due to peering rules being violated
This bug was originally introduced with recovery below min_size in
e5a96fd, and then preserved through refactors in 749a13d and 95bec9.
7cb818a exposed it with with expansion of recovery below min_size
to include ec pools (acting.size() is sufficient for replicated
pools).
Fixes: https://tracker.ceph.com/issues/48613
Fixes: https://tracker.ceph.com/issues/48417
Signed-off-by: Samuel Just <sjust@redhat.com>
(cherry picked from commit 642a1c165499bcbd4cfdf907af313ac7ffe44ff4)
Conflicts:
src/osd/PeeringState.h
Fixes the callers rather than also backporting 95bec9873.
(3) My code(v15.2.13) does not contain this patch
(4) I'm thinking about the root cause described in this patch, will it cause the problem I reported ?
Thank you!
Updated by Radoslaw Zarzynski about 2 years ago
- Status changed from New to Need More Info
I'm thinking about the root cause described in this patch, will it cause the problem I reported ?
Yes, I think so. It explains your case but it also means we still need to find a replicator of the original problem described by Vikhyat as it happened on Quincy (ceph version 17.0.0-10229-g7e035110 (7e035110784fba02ba81944e444be9a36932c6a3) quincy (dev)).
Updated by jianwei zhang about 2 years ago
[root@jianwei 20220308-log]# grep "1715'7110" ceph-osd.49.log-20220308 |grep -e NONE -e "1715'7110" -e crt -e lcod -e mlcod -e luod
2022-03-07T17:48:30.490+0800 7fd47551f700 1 osd.49 pg_epoch: 1716 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1716 pruub=4.332741706s) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1716 pi=[1706,1716)/1 luod=1715'7109 crt=1715'7109 lcod 1715'7108 mlcod 1715'7108 active pruub 6343.848557841s@ mbc={}] start_peering_interval up [49,2147483647,47,18,2147483647,31] -> [49,2147483647,2147483647,18,2147483647,31], acting [49,2147483647,47,18,2147483647,31] -> [49,2147483647,2147483647,18,2147483647,31], acting_primary 49(0) -> 49, up_primary 49(0) -> 49, role 0 -> 0, features acting 4540138292840890367 upacting 4540138292840890367
2022-03-07T17:48:30.490+0800 7fd47551f700 1 osd.49 pg_epoch: 1716 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1716 pruub=4.332741706s) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1716 pi=[1706,1716)/1 crt=1715'7109 lcod 1715'7108 mlcod 0'0 unknown pruub 6343.848557841s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:44.377+0800 7fd47551f700 1 osd.49 pg_epoch: 1719 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1716) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1716 pi=[1706,1716)/1 crt=1715'7109 lcod 1715'7108 mlcod 0'0 incomplete mbc={}] state<Started/Primary/Peering>: Peering, affected_by_map, going to Reset
2022-03-07T17:48:44.377+0800 7fd47551f700 1 osd.49 pg_epoch: 1719 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1719) [49,NONE,NONE,18,14,31]p49(0) r=0 lpr=1719 pi=[1706,1719)/1 crt=1715'7109 lcod 1715'7108 mlcod 0'0 unknown mbc={}] start_peering_interval up [49,2147483647,2147483647,18,2147483647,31] -> [49,2147483647,2147483647,18,14,31], acting [49,2147483647,2147483647,18,2147483647,31] -> [49,2147483647,2147483647,18,14,31], acting_primary 49(0) -> 49, up_primary 49(0) -> 49, role 0 -> 0, features acting 4540138292840890367 upacting 4540138292840890367
2022-03-07T17:48:44.378+0800 7fd47551f700 1 osd.49 pg_epoch: 1719 pg[3.356s0( v 1715'7110 (1437'5676,1715'7110] local-lis/les=1714/1715 n=9 ec=206/206 lis/c=1714/1706 les/c/f=1715/1709/0 sis=1719) [49,NONE,NONE,18,14,31]p49(0) r=0 lpr=1719 pi=[1706,1719)/1 crt=1715'7109 lcod 1715'7108 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:48:58.819+0800 7fd472d1a700 1 osd.49 pg_epoch: 1721 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1721 pruub=2.823632061s) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1721 pi=[1706,1721)/1 crt=1720'7111 lcod 1715'7110 mlcod 1715'7109 active pruub 6370.667211529s@ mbc={0={(1+0)=1},1={(0+0)=1},2={(0+0)=1},3={(1+0)=1},4={(0+0)=1},5={(1+0)=1}}] start_peering_interval up [49,2147483647,2147483647,18,14,31] -> [49,2147483647,2147483647,18,2147483647,31], acting [49,2147483647,2147483647,18,14,31] -> [49,2147483647,2147483647,18,2147483647,31], acting_primary 49(0) -> 49, up_primary 49(0) -> 49, role 0 -> 0, features acting 4540138292840890367 upacting 4540138292840890367
2022-03-07T17:48:58.819+0800 7fd472d1a700 1 osd.49 pg_epoch: 1721 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1721 pruub=2.823632061s) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1721 pi=[1706,1721)/1 crt=1720'7111 lcod 1715'7110 mlcod 0'0 unknown pruub 6370.667211529s@ mbc={}] state<Start>: transitioning to Primary
2022-03-07T17:49:04.114+0800 7fd47551f700 1 osd.49 pg_epoch: 1724 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1721) [49,NONE,NONE,18,NONE,31]p49(0) r=0 lpr=1721 pi=[1706,1721)/1 crt=1720'7111 lcod 1715'7110 mlcod 0'0 incomplete mbc={}] state<Started/Primary/Peering>: Peering, affected_by_map, going to Reset
2022-03-07T17:49:04.114+0800 7fd47551f700 1 osd.49 pg_epoch: 1724 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1724) [49,44,NONE,18,NONE,31]p49(0) r=0 lpr=1724 pi=[1706,1724)/1 crt=1720'7111 lcod 1715'7110 mlcod 0'0 unknown mbc={}] start_peering_interval up [49,2147483647,2147483647,18,2147483647,31] -> [49,44,2147483647,18,2147483647,31], acting [49,2147483647,2147483647,18,2147483647,31] -> [49,44,2147483647,18,2147483647,31], acting_primary 49(0) -> 49, up_primary 49(0) -> 49, role 0 -> 0, features acting 4540138292840890367 upacting 4540138292840890367
2022-03-07T17:49:04.114+0800 7fd47551f700 1 osd.49 pg_epoch: 1724 pg[3.356s0( v 1720'7111 (1437'5676,1720'7111] local-lis/les=1719/1720 n=9 ec=206/206 lis/c=1719/1706 les/c/f=1720/1709/0 sis=1724) [49,44,NONE,18,NONE,31]p49(0) r=0 lpr=1724 pi=[1706,1724)/1 crt=1720'7111 lcod 1715'7110 mlcod 0'0 unknown mbc={}] state<Start>: transitioning to Primary
Updated by jianwei zhang about 2 years ago
jianwei zhang wrote:
Radoslaw Zarzynski wrote:
the all osds is up&in, so the case doesn't involve recovery_unfound due to osd down.
A note from the bug scrub: this looks confusing. In the comment #22 a following info can be found:
[...]
which would mean that, at least for some time, 3 OSDs were down and this is enough to cause the issue.
Anyway, there is no another thing we can use to double check: the
can_rollback_to(aka.crtin the logs) value which is present in a log entry. Here is an example:[...]
Could you please provide similar entries for the affected PG?
Hi,
(1) my code version is ceph tag v15.2.13
[...]
(2) I found a patch (code branch octopus) for ec min_size and it can cause ec data inconsistent
[...]
(3) My code(v15.2.13) does not contain this patch
(4) I'm thinking about the root cause described in this patch, will it cause the problem I reported ?
Thank you!
============================================without osd/PeeringState: fix acting_set_writeable min_size check ============================================
(1) I found a reproduce method on ceph v15.2.13 without the patch(osd/PeeringState: fix acting_set_writeable min_size check)
pool info
# ceph osd erasure-code-profile set ecprofile k=4 m=2 crush-failure-domain=osd root=default
# ceph osd crush rule create-erasure ecrule ecprofile
# ceph osd pool create cephfs.a.data 128 128 erasure ecprofile ecrule
# ceph osd pool set cephfs.a.data allow_ec_overwrites true
# ./bin/ceph osd pool ls detail
pool 3 'cephfs.a.data' erasure profile ecprofile size 6 min_size 4 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 776 lfor 0/490/488 flags hashpspool,ec_overwrites stripe_width 16384 application cephfs
# ./bin/ceph osd erasure-code-profile get ecprofile
crush-device-class=
crush-failure-domain=osd
crush-root=default
jerasure-per-chunk-alignment=false
k=4
m=2
plugin=jerasure
root=default
technique=reed_sol_van
w=8
# ./bin/ceph osd df tree
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS TYPE NAME
-1 0.88728 - 909 GiB 19 GiB 700 MiB 318 KiB 9.0 GiB 890 GiB 2.06 1.00 - root default
-3 0.88728 - 909 GiB 19 GiB 700 MiB 318 KiB 9.0 GiB 890 GiB 2.06 1.00 - host ln-ceph-rpm
0 hdd 0.09859 1.00000 101 GiB 2.1 GiB 80 MiB 41 KiB 1024 MiB 99 GiB 2.06 1.00 36 up osd.0
1 hdd 0.09859 1.00000 101 GiB 2.1 GiB 79 MiB 42 KiB 1024 MiB 99 GiB 2.06 1.00 33 up osd.1
2 hdd 0.09859 1.00000 101 GiB 2.1 GiB 77 MiB 42 KiB 1024 MiB 99 GiB 2.06 1.00 27 up osd.2
3 hdd 0.09859 1.00000 101 GiB 2.1 GiB 76 MiB 40 KiB 1024 MiB 99 GiB 2.05 1.00 31 up osd.3
4 hdd 0.09859 1.00000 101 GiB 2.1 GiB 77 MiB 25 KiB 1024 MiB 99 GiB 2.05 1.00 27 up osd.4
5 hdd 0.09859 1.00000 101 GiB 2.1 GiB 84 MiB 51 KiB 1024 MiB 99 GiB 2.06 1.00 37 up osd.5
6 hdd 0.09859 1.00000 101 GiB 2.1 GiB 77 MiB 31 KiB 1024 MiB 99 GiB 2.05 1.00 28 up osd.6
7 hdd 0.09859 1.00000 101 GiB 2.1 GiB 72 MiB 19 KiB 1024 MiB 99 GiB 2.05 1.00 32 up osd.7
8 hdd 0.09859 1.00000 101 GiB 2.1 GiB 77 MiB 27 KiB 1024 MiB 99 GiB 2.06 1.00 40 up osd.8
TOTAL 909 GiB 19 GiB 700 MiB 322 KiB 9.0 GiB 890 GiB 2.06
MIN/MAX VAR: 1.00/1.00 STDDEV: 0.00
# ./bin/ceph df detail
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 909 GiB 890 GiB 9.7 GiB 19 GiB 2.06
TOTAL 909 GiB 890 GiB 9.7 GiB 19 GiB 2.06
--- POOLS ---
POOL ID PGS STORED (DATA) (OMAP) OBJECTS USED (DATA) (OMAP) %USED MAX AVAIL QUOTA OBJECTS QUOTA BYTES DIRTY USED COMPR UNDER COMPR
device_health_metrics 1 1 0 B 0 B 0 B 0 0 B 0 B 0 B 0 294 GiB N/A N/A 0 0 B 0 B
cephfs.a.data 3 32 120 KiB 120 KiB 0 B 1 512 KiB 512 KiB 0 B 0 587 GiB N/A N/A 1 0 B 0 B
(2) running IO
# cat rados_put.sh
#!/bin/sh
while [[ 1 ]]; do
for i in $(find /root/thinkfs-ssh/src/osd -type f); do
echo ./bin/rados put myobj $i -p cephfs.a.data
./bin/rados put myobj $i -p cephfs.a.data
sleep 0.001
done
done
# sh rados_put.sh
(3) kill and start osd
# cat kill_osd.sh
#!/bin/sh
set -x
#ps aux|grep ceph-osd|grep -v -e grep|grep -e 'i 4' -e 'i 7' -e 'i 5'
kill -6 $(ps aux|grep ceph-osd|grep -v -e grep|grep 'i 7'|awk '{print $2}')
kill -6 $(ps aux|grep ceph-osd|grep -v -e grep|grep 'i 5'|awk '{print $2}')
sleep 30
kill -6 $(ps aux|grep ceph-osd|grep -v -e grep|grep 'i 4'|awk '{print $2}')
sleep 10
/root/thinkfs-ssh/build/bin/ceph-osd -i 5 -c /root/thinkfs-ssh/build/ceph.conf
sleep 10
kill -6 $(ps aux|grep ceph-osd|grep -v -e grep|grep 'i 5'|awk '{print $2}')
/root/thinkfs-ssh/build/bin/ceph-osd -i 7 -c /root/thinkfs-ssh/build/ceph.conf
sleep 30
/root/thinkfs-ssh/build/bin/ceph-osd -i 5 -c /root/thinkfs-ssh/build/ceph.conf
/root/thinkfs-ssh/build/bin/ceph-osd -i 4 -c /root/thinkfs-ssh/build/ceph.conf
(4) ceph pg dump_stuck recovery_unfound (myobj)
============================================add the patch osd/PeeringState: fix acting_set_writeable min_size check ============================================
# ./bin/ceph osd pool set cephfs.a.data min_size 4
running (1)(2)(3)(4) and not stuck recovery_unfound
Updated by jianwei zhang about 2 years ago
the pacth
osd/PeeringState: fix acting_set_writeable min_size check
can resolve ceph v15.2.13 recovery_unfound BUG
Updated by Radoslaw Zarzynski about 2 years ago
Good to know and thanks for your testing!
Just to the record: leaving the bug in the Need More Info state as the previous replication of the problem happened 2 months ago (comment #12).