Actions
Bug #21362
opencephfs ec data pool + windows fio,ceph cluster degraed several hours always, osd up and down
Status:
Need More Info
Priority:
Normal
Assignee:
-
Category:
-
Target version:
-
% Done:
0%
ceph-qa-suite:
fs
Component(FS):
Labels (FS):
Pull request ID:
Crash signature (v1):
Crash signature (v2):
Description
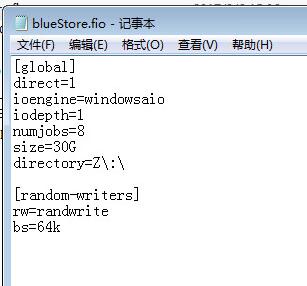
1.configure
version : 12.2.0, ceph professional rpms install,new installed env.
cephfs: meta pool (ssd 1*3 replica 2), data pool (hdd 20*3 ec 2+1).
cluster os : centos 7.3, nodes 3.
client os : windows7, fio. (8threads 1iodepth, 30g files), 1 node
2. operation
once started fio, the cluster begin degraed, pgs displayed serveral status.
ceph-osd output manys logs.
from ceph -s, it can be saw that up osds increased and decrease crossed.
even if that client ios stopped. the cluster keep those status about 2 hours,
and it canno't return to all pgs active-clean status.
Files
{kind=link}
Actions