Bug #17669
closedWhen removing a snapshot, VMs die
0%
Description
We are seeing this in ceph -w when removing a snapshot on 10.2.3:
2016-10-22 09:14:48.151340 osd.3 [WRN] slow request 31.698830 seconds old, received at 2016-10-22 09:14:16.452248: osd_repop(client.4861747.0:3241807 7.3f8 7:1fcbc3c9:::rbd_data.43f58c2ae8944a.0000000000015624:head v 62054'42881908) currently commit_sent 2016-10-22 09:14:48.151345 osd.3 [WRN] slow request 30.967810 seconds old, received at 2016-10-22 09:14:17.183267: osd_repop(client.4861747.0:3241816 7.3f8 7:1fcbc3c9:::rbd_data.43f58c2ae8944a.0000000000015624:head v 62054'42881917) currently commit_sent 2016-10-22 09:14:49.151560 osd.3 [WRN] 40 slow requests, 5 included below; oldest blocked for > 52.665612 secs 2016-10-22 09:14:49.151568 osd.3 [WRN] slow request 36.848522 seconds old, received at 2016-10-22 09:14:12.302939: osd_op(client.4814313.0:48584251 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:49.151576 osd.3 [WRN] slow request 39.631818 seconds old, received at 2016-10-22 09:14:09.519643: osd_op(client.4804243.0:70940705 7.13562bdf (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:49.151585 osd.3 [WRN] slow request 51.037879 seconds old, received at 2016-10-22 09:13:58.113582: osd_op(client.4804243.0:70940679 7.13562bdf rbd_data.2a85c82ae8944a.000000000000d0b2 [write 3506176~4096] snapc 6814=[6814] ack+ondisk+write+known_if_redirected e62054) currently commit_sent 2016-10-22 09:14:49.151592 osd.3 [WRN] slow request 39.630632 seconds old, received at 2016-10-22 09:14:09.520829: osd_op(client.4814313.0:48584241 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:49.151598 osd.3 [WRN] slow request 50.343677 seconds old, received at 2016-10-22 09:13:58.807784: osd_op(client.4814313.0:48584235 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:50.151831 osd.3 [WRN] 35 slow requests, 5 included below; oldest blocked for > 53.665859 secs 2016-10-22 09:14:50.151839 osd.3 [WRN] slow request 30.139173 seconds old, received at 2016-10-22 09:14:20.012536: osd_op(client.4814313.0:48584253 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:50.151848 osd.3 [WRN] slow request 48.776105 seconds old, received at 2016-10-22 09:14:01.375603: osd_op(client.4804243.0:70940702 7.13562bdf (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:50.151852 osd.3 [WRN] slow request 52.328043 seconds old, received at 2016-10-22 09:13:57.823665: osd_op(client.4814313.0:48584231 7.33a44969 rbd_data.4488312ae8944a.000000000000452b [write 2654208~4096] snapc 6803=[6803] ack+ondisk+write+known_if_redirected e62054) currently waiting for subops from 20,26 2016-10-22 09:14:50.151857 osd.3 [WRN] slow request 49.875377 seconds old, received at 2016-10-22 09:14:00.276332: osd_op(client.4804243.0:70940701 7.13562bdf (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:50.151861 osd.3 [WRN] slow request 39.515348 seconds old, received at 2016-10-22 09:14:10.636361: osd_op(client.4814313.0:48584247 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:51.152129 osd.3 [WRN] 35 slow requests, 2 included below; oldest blocked for > 54.666190 secs 2016-10-22 09:14:51.152137 osd.3 [WRN] slow request 41.630473 seconds old, received at 2016-10-22 09:14:09.521566: osd_op(client.4804243.0:70940706 7.13562bdf (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:51.152143 osd.3 [WRN] slow request 32.744557 seconds old, received at 2016-10-22 09:14:18.407482: osd_op(client.4814313.0:48584252 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:52.152325 osd.3 [WRN] 36 slow requests, 1 included below; oldest blocked for > 55.666409 secs 2016-10-22 09:14:52.152333 osd.3 [WRN] slow request 30.575033 seconds old, received at 2016-10-22 09:14:21.577225: osd_op(client.4814313.0:48584254 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:53.201966 osd.3 [WRN] 32 slow requests, 1 included below; oldest blocked for > 54.534261 secs 2016-10-22 09:14:53.201973 osd.3 [WRN] slow request 30.267825 seconds old, received at 2016-10-22 09:14:22.934076: osd_op(client.4814313.0:48584255 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:14:55.202311 osd.3 [WRN] 33 slow requests, 1 included below; oldest blocked for > 56.534612 secs 2016-10-22 09:14:55.202319 osd.3 [WRN] slow request 30.827568 seconds old, received at 2016-10-22 09:14:24.374684: osd_op(client.4814313.0:48584280 7.33a44969 (undecoded) ack+ondisk+write+known_if_redirected e62054) currently queued_for_pg 2016-10-22 09:15:03.509315 mon.0 [INF] HEALTH_WARN; 206 requests are blocked > 32 sec
This continues for a long time and after 1-2 minutes, VMs start to hang because they can't get IO.
Our cluster is running on 34 OSDs and each server has a Journal-SSD. The disks perform well on normal times and we have ~1000 Iop/s during normal usage. As a peak load we've already seen more than 4000 iops, so there should be plenty of performance.
We are running librbd based qemu VMs exclusively on this cluster.
The problems are on every night when we remove snapshots from the old backups and 1..n VMs die ("hung task timer > 120").
Any hints welcome!
Files
Updated by Jason Dillaman over 7 years ago
- Project changed from rbd to Ceph
- Priority changed from Normal to High
Updated by Samuel Just over 7 years ago
- Status changed from New to Closed
Your cluster apparently isn't fast enough to both the snap removal workload and the client IO. You could try reducing osd_snap_trim_priority to 1. Without more information, this doesn't seem to be a bug so I'm closing it.
Updated by Daniel Kraft over 7 years ago
Thanks for the hint about osd_snap_trim_priority.
What I als found out was that the problem is bigger when the VMs are NOT suspended during snapshot.
When we changed this so that the VMs are suspended during snapshot and resumed after it, the problem went away.
Currently we're trying to just fsfreeze the VM (but not suspend it) during snapshot and the problem reoccurs, however in a less heavy way - only 1-2 VMs crash during snapshot removals.
I have added the parameter osd_snap_trim_priority and verified that it is set via the admin-command asok. Let's see if that helps.
Updated by Daniel Kraft over 7 years ago
Ok, I have added
osd snap trim priority = 1
osd snap trim sleep = 0.25
The latter one more because it was recommended somewhere. Does this still have an effect on jewel?
Whatever, I haven't seen any crashes tonight, so that seems to have helped. I'll keep my fingers crossed for the next nights.
Updated by Daniel Kraft over 7 years ago
I still see this after the above changes. So no help there.
2016-11-07 23:49:54.222049 osd.6 10.14.0.77:6801/21119 230 : cluster [WRN] 24 slow requests, 5 included below; oldest blocked for > 34.925406 secs
2016-11-07 23:49:54.222061 osd.6 10.14.0.77:6801/21119 231 : cluster [WRN] slow request 34.925212 seconds old, received at 2016-11-07 23:49:19.296693: osd_op(client.4804246.0:107838743 7.cf8eab5e rbd_data.41f72e2ae8944a.00000000000176b9 [write 131072~40
96] snapc 6e29=[6e29] ack+ondisk+write+known_if_redirected e64064) currently commit_sent
2016-11-07 23:49:54.222067 osd.6 10.14.0.77:6801/21119 232 : cluster [WRN] slow request 34.925148 seconds old, received at 2016-11-07 23:49:19.296757: osd_op(client.4804246.0:107838744 7.cf8eab5e rbd_data.41f72e2ae8944a.00000000000176b9 [write 143360~40
96] snapc 6e29=[6e29] ack+ondisk+write+known_if_redirected e64064) currently commit_sent
2016-11-07 23:49:54.222072 osd.6 10.14.0.77:6801/21119 233 : cluster [WRN] slow request 34.925077 seconds old, received at 2016-11-07 23:49:19.296827: osd_op(client.4804246.0:107838745 7.cf8eab5e rbd_data.41f72e2ae8944a.00000000000176b9 [write 163840~40
96] snapc 6e29=[6e29] ack+ondisk+write+known_if_redirected e64064) currently commit_sent
2016-11-07 23:49:54.222078 osd.6 10.14.0.77:6801/21119 234 : cluster [WRN] slow request 34.925019 seconds old, received at 2016-11-07 23:49:19.296885: osd_op(client.4804246.0:107838746 7.cf8eab5e rbd_data.41f72e2ae8944a.00000000000176b9 [write 176128~40
96] snapc 6e29=[6e29] ack+ondisk+write+known_if_redirected e64064) currently commit_sent
2016-11-07 23:49:54.222084 osd.6 10.14.0.77:6801/21119 235 : cluster [WRN] slow request 34.924964 seconds old, received at 2016-11-07 23:49:19.296940: osd_op(client.4804246.0:107838747 7.cf8eab5e rbd_data.41f72e2ae8944a.00000000000176b9 [write 196608~4096] snapc 6e29=[6e29] ack+ondisk+write+known_if_redirected e64064) currently commit_sent
During the time above, our backups are running and creating and removing snapshots. We are measuring the iops per OSD. I can't see higher load then usual on the OSDs:
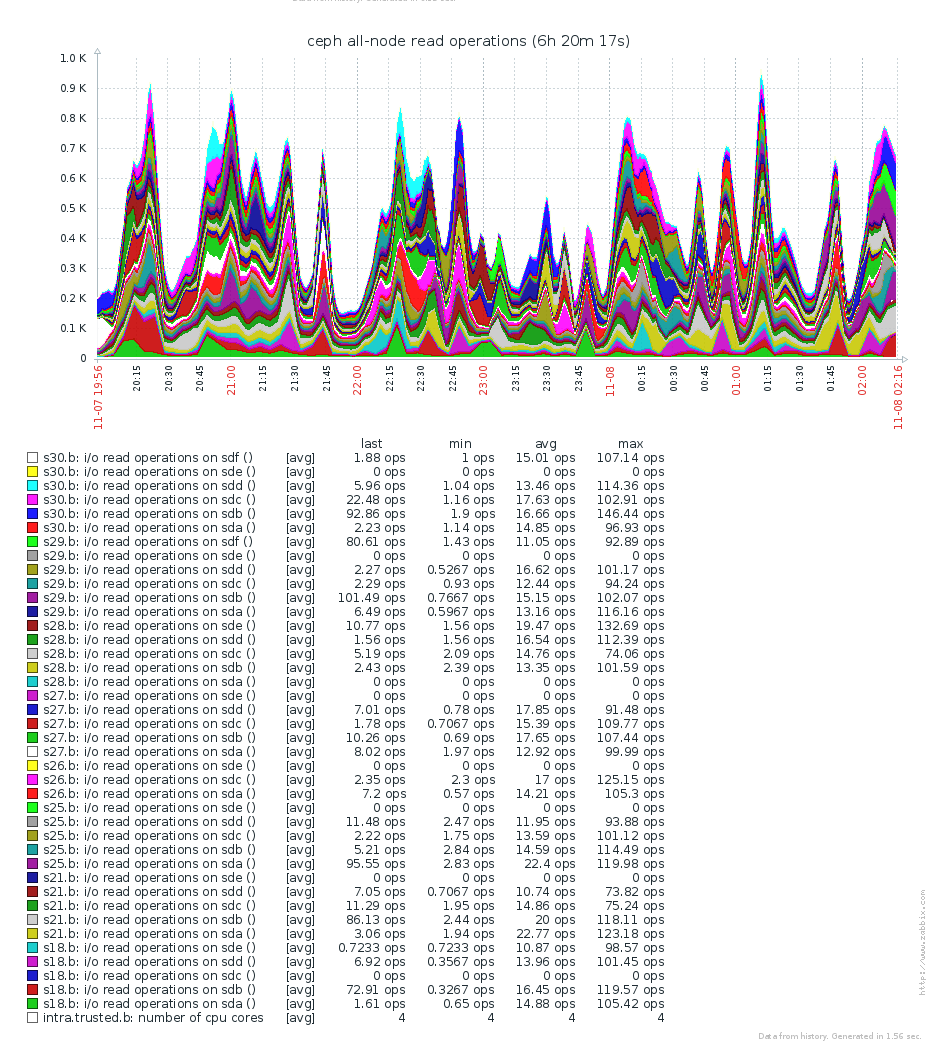
Still, any hints to solve this or how to debug this further are welcome.
I'll add 8 more OSDs next week and I'm hoping that this will help. However, according to the graph above, that's no load problem.
Updated by Christian Theune over 7 years ago
Daniel: do you have to restart the VMs or do they every recover from the hang?
Updated by Daniel Kraft over 7 years ago
It seems that some VMs recover from such a situation, however I think that might be because the time they hang is shorter than with others.
Most times I have to "destroy" (virsh) them and start them again.