Bug #53926
closedrocksdb's Option.ttl may be beneficial for RGW index workload
100%
Description
Background
In our environment a lot of RGW workloads have lifecycle or customers doing a lot of DELETE/PUT on their buckets. These workload create a lot of tombstones which slows omap_iterator until the OSD eventually start to complain:
2021-12-22 19:10:22.201 7f19eb59f700 0 bluestore(/var/lib/ceph/osd/ceph-19) log_latency_fn slow operation observed for upper_bound, latency = 6.25955s, after = <redacted_key_name> omap_iterator(cid = 14.311_head, oid = <redacted_object_name> 2021-12-22 19:10:34.370 7f19eb59f700 0 bluestore(/var/lib/ceph/osd/ceph-19) log_latency_fn slow operation observed for upper_bound, latency = 6.0164s, after = <redacted_key_name> omap_iterator(cid = 14.311_head, oid = <redacted_object_name>
In the most extreme scenarios, this issue created a lot of slow requests (10k+) on the PG which results in an outage. On some clusters we have no alternatives but to trigger a compaction thrice a day.
Options.ttl
While looking at rocksdb options, the following was discovered: https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide#periodic-and-ttl-compaction. Because our production runs on Nautilus we decided to investigate options.ttl instead of option.periodic_compation_seconds. Note: ttl is disabled on Nautilus version of rocksdb and set at 30 days with Pacific
I ran two sets of benchmarks:
- On a 10M keys omap object: with a rate capped at 10k keys/s list 10k keys -> delete listed keys -> repeat until all keys are deleted. ttl was set at 30min
- On a 10M keys omap object: Send the following distribution (max: 100/s): 11 keys list, 44 keys insert, 44 keys delete. ttl was set at 60min
Results
All OSDs were manually compacted prior to running the bench.
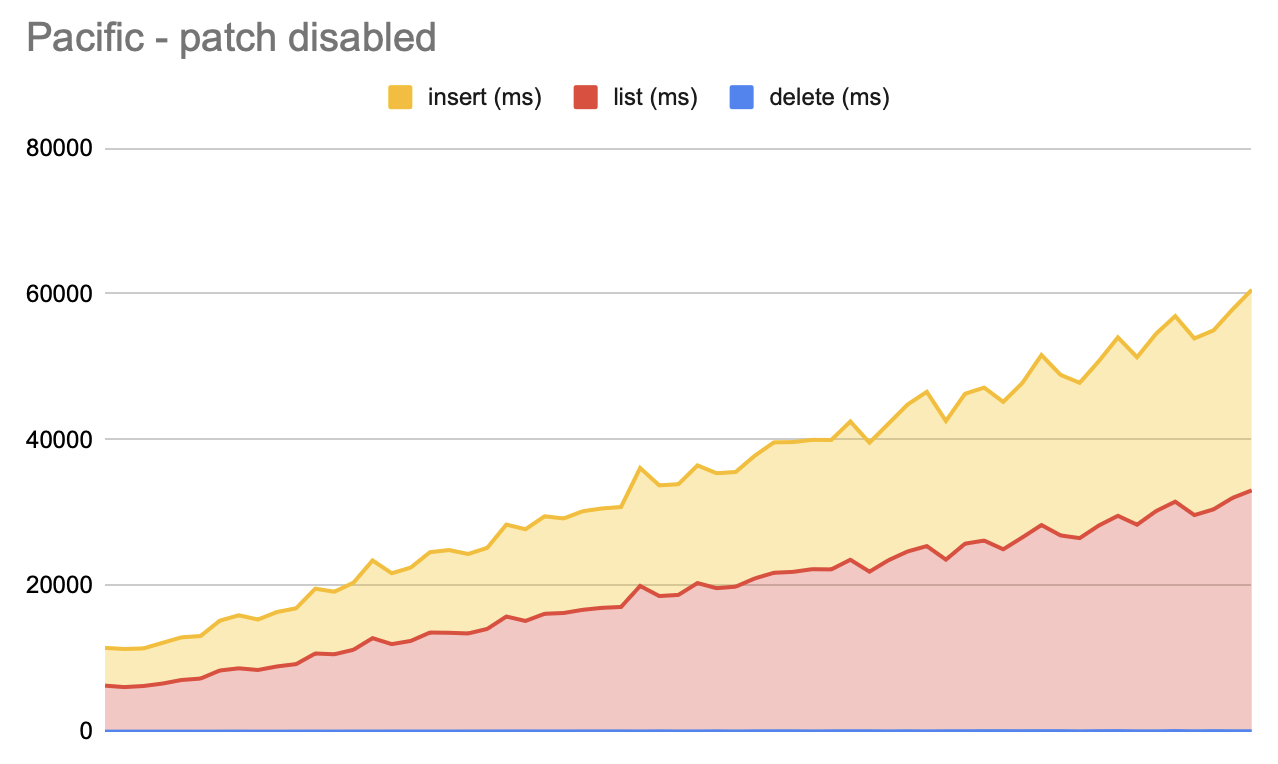
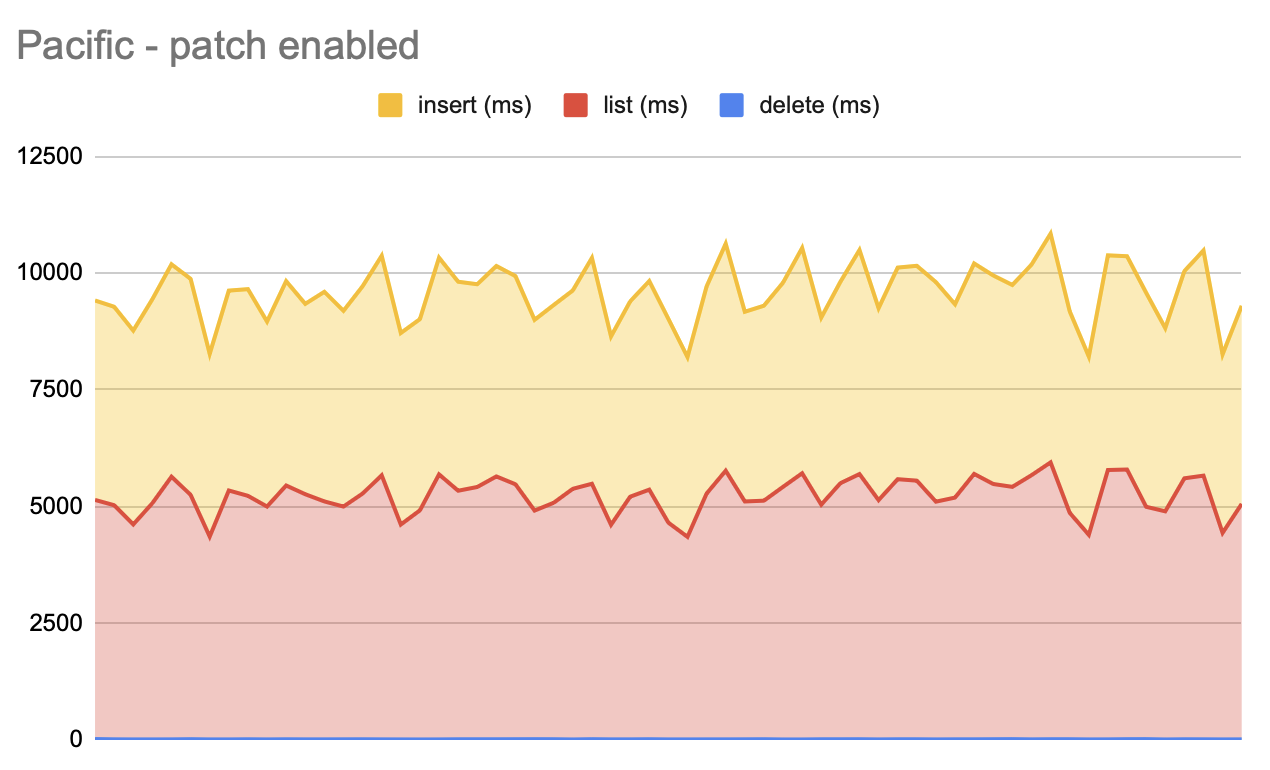
For the 10k list -> deletes (ran on Pacific):
Default non-ttl: Showed an increase in latency some drops happen due to general compaction but latency never returns to its start value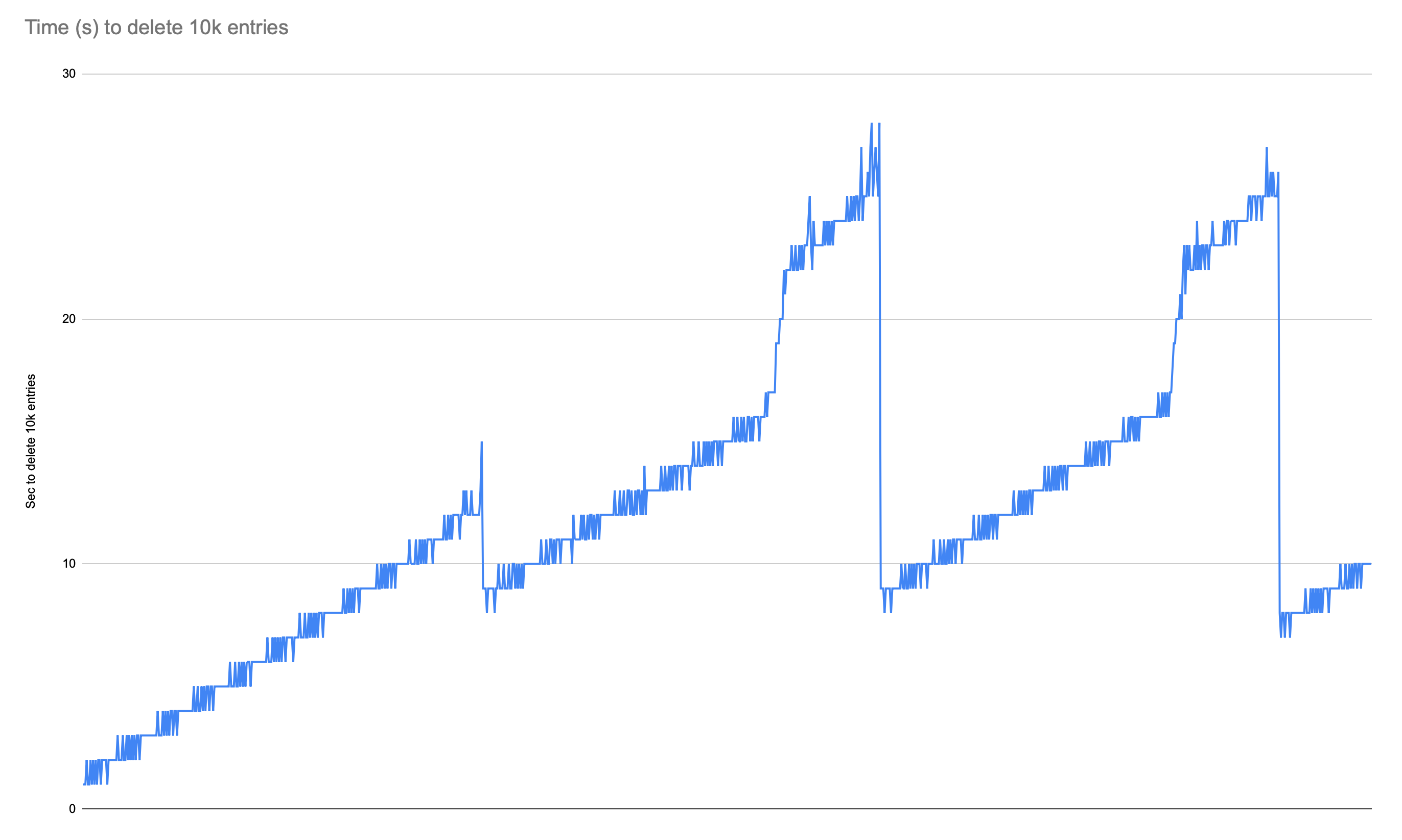
ttl=30min: Steady increase of latency followed by a drop to start value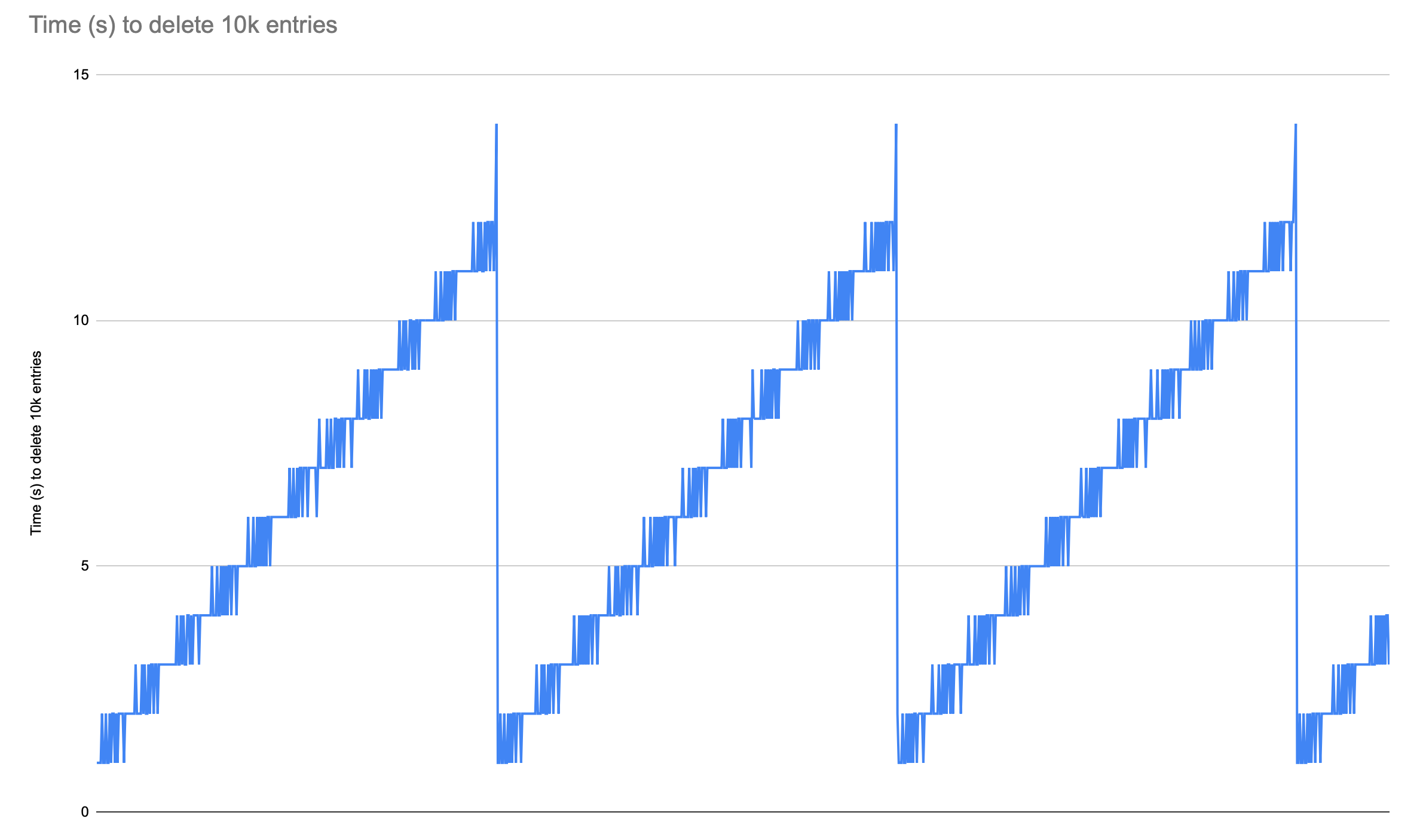
For the workload distribution test (ran on Nautilus)
Default non-ttl:You can clearly see latency increasing over time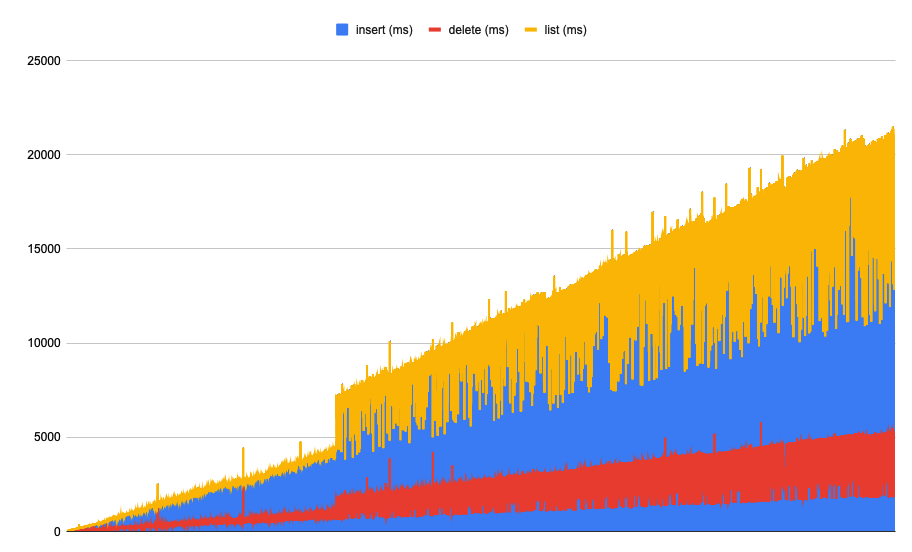
ttl=1h: latency still increases over time. When TTL compaction is triggered there's a high latency spike followed by a significant drop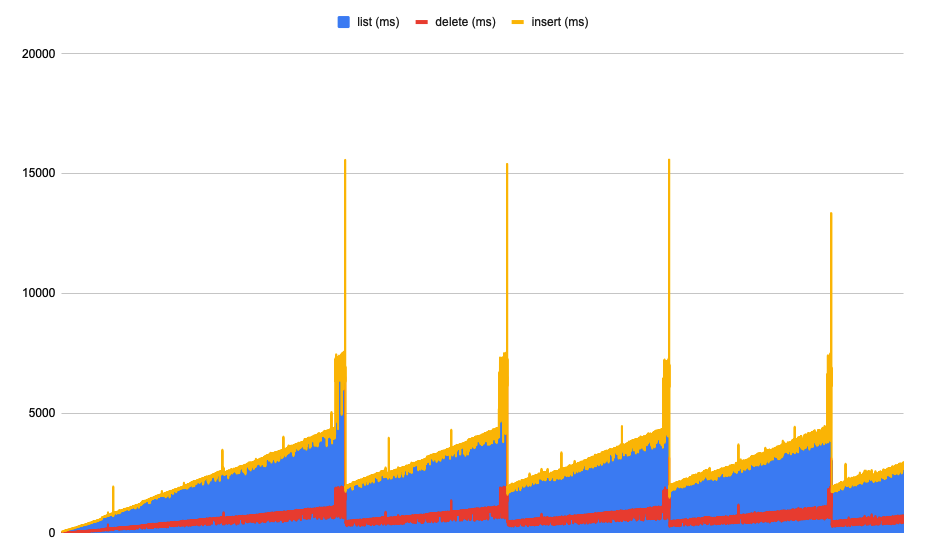
Conclusion
We started to deploy ttl compaction in prod but based off of this I'm not sure whether TTL should be changed upstream or not. I think it needs more investigation to make sure it doesn't negatively affect some workloads but I'm not sure to how to proceed with this. This ticket to gather more data or tests we could run.
Files
{kind=link}
{kind=link}