Bug #21362
opencephfs ec data pool + windows fio,ceph cluster degraed several hours always, osd up and down
0%
Description
1.configure
version : 12.2.0, ceph professional rpms install,new installed env.
cephfs: meta pool (ssd 1*3 replica 2), data pool (hdd 20*3 ec 2+1).
cluster os : centos 7.3, nodes 3.
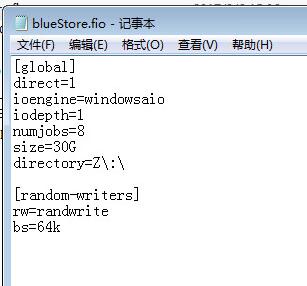
client os : windows7, fio. (8threads 1iodepth, 30g files), 1 node
2. operation
once started fio, the cluster begin degraed, pgs displayed serveral status.
ceph-osd output manys logs.
from ceph -s, it can be saw that up osds increased and decrease crossed.
even if that client ios stopped. the cluster keep those status about 2 hours,
and it canno't return to all pgs active-clean status.
Files
{kind=link}
Updated by Patrick Donnelly over 6 years ago
- Project changed from Ceph to CephFS
- Category deleted (
129) - Status changed from New to Need More Info
- Assignee deleted (
Jos Collin)
cephfs: meta pool (ssd 1*3 replica 2), data pool (hdd 20*3 ec 2+1).
Using replica 2 is strongly advised against. see also: https://www.spinics.net/lists/ceph-users/msg32895.html
We also need more information to advise you on what's wrong. `ceph status` and debug logs would be helpful.