Osd - Faster Peering » History » Revision 3
« Previous |
Revision 3/5
(diff)
| Next »
Jessica Mack, 07/10/2015 09:58 PM
Osd - Faster Peering¶
Summary¶
For correctness reasons, peering requires a series of serial message transmissions and filestore syncs prior to completion. This puts something of a lower bound on the latency client IO suffers on cluster change.
Owners¶
- Sam Just (RedHat)
- Name (Affiliation)
- Name
Interested Parties¶
- Guang Yang (Yahoo!)
- Name (Affiliation)
- Name
Current Status¶
Detailed Description¶
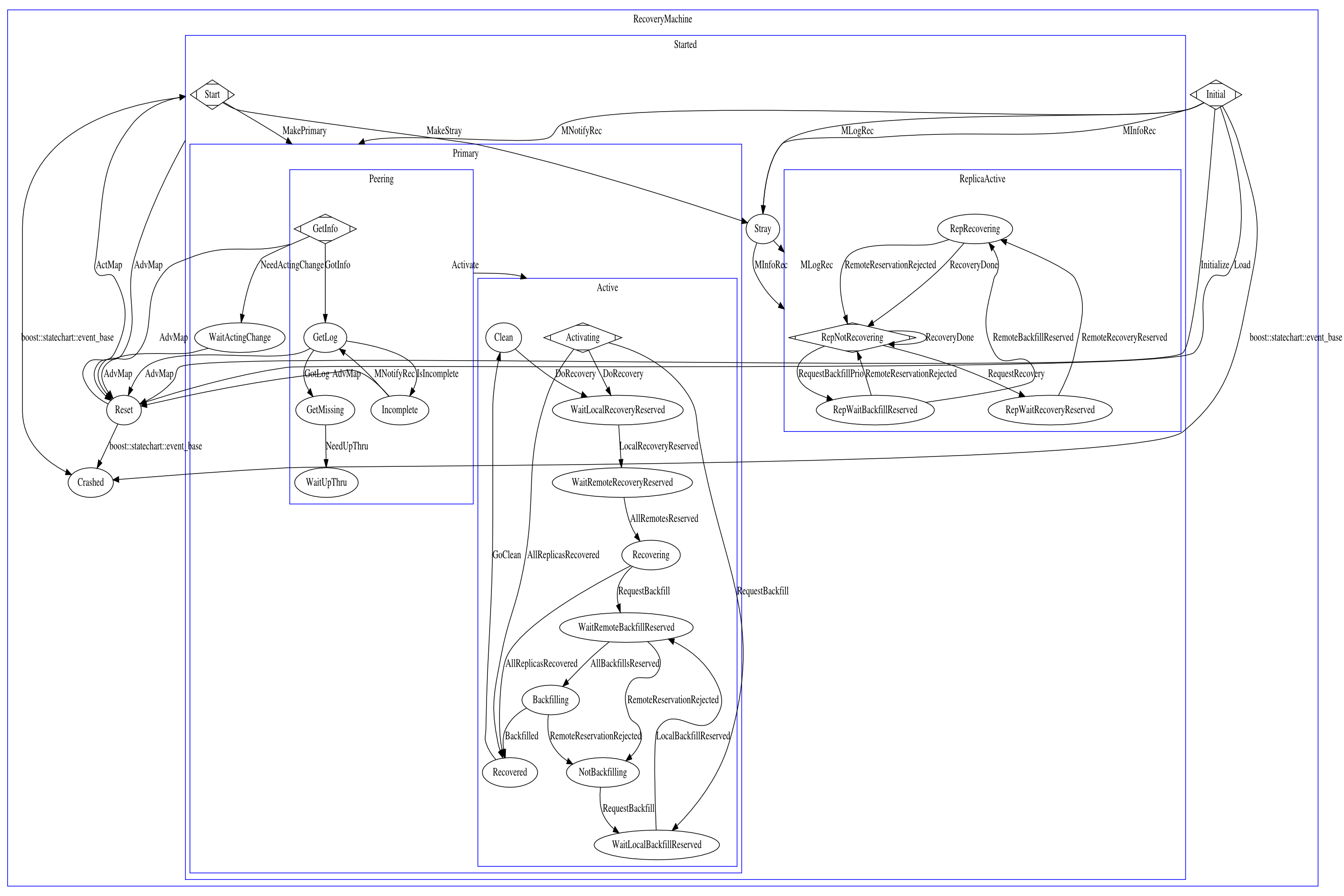
The above is the peering state chart generated from the source. GetInfo->GetLog->GetMissing requires three round trips to replicas. First, we get pg infos from every osd in the prior set, acting set, and up set in order to choose an authoritative log. Second, we fetch the authoritative log. Last, we fetch missing sets from each acting set replica for use during recovery.
1) Can we preemptively request the log+missing for osds in the most recent prior set interval to hopefully skip the GetLog step?
2) Can we preemptively request the log+missing for acting and up osds in the GetInfo set to hopefully skip the GetMissing step?
Another wrinkle is that replicas do not send the info requested in GetInfo and the primary cannot start peering until the previous acting interval has been flushed.
1) We might be able to relax this to waiting for a commit (journal only) if we track unstable objects across intervals. We need to track unstable objects for replicas going forward anyway to get replica reads right, so this might not be so bad.
Work items¶
Coding tasks¶
- Task 1
- Task 2
- Task 3
Build / release tasks¶
- Task 1
- Task 2
- Task 3
Documentation tasks¶
- Task 1
- Task 2
- Task 3
Deprecation tasks¶
- Task 1
- Task 2
- Task 3
Updated by Jessica Mack almost 9 years ago · 3 revisions