Erasure encoding as a storage backend¶
Summary¶
For many data sets, the 3x replication in CEPH is perfectly acceptable. However, for very large data sets (such as those in Genomics) the 3x replication starts impacting business models, even assuming the continued reduction in HDD prices. Erasure encoding sharded stores should address this issue.
Owners¶
- Christopher Liljenstolpe (Annai Systems) <cdl@asgaard.org>
- Dan Maltbie (Annai Systems) <danm@annaisystems.com>
- Loic Dachary loic@dachary.org
Interested Parties¶
- Greg Farnum
- Sage Weil
- Sam Just
- Loïc Dachary
- Josh Durgin
- Xiaoxi Chen
- Zhiteng Huang
- Xiaobing Zhou(xzhou40 (AT) hawk.iit.edu)
- Yuan Zhou (yuan.zhou at intel dot com)
- Jianhui Yuan
- Da Chun (ngugc at qq.com)
Current Status¶
Not currently accepted. We are proposing this as a development effort. At this time, Annai is more than willing to help with this, but we don't have the resources (including ceph coders) to materially contribute code. We are "interested" users.
Discussions (chronological order)¶
- erasure encoding ( sorry ) http://thread.gmane.org/gmane.comp.file-systems.ceph.devel/14459
- fecpp C++ forward error correction library http://thread.gmane.org/gmane.comp.file-systems.ceph.devel/14560
- Distributed Deduplication in a Cloud-based Object Storage System http://thread.gmane.org/gmane.comp.file-systems.ceph.devel/14609
- OSD abstract class http://thread.gmane.org/gmane.comp.file-systems.ceph.devel/14627
- PG statechart http://thread.gmane.org/gmane.comp.file-systems.ceph.devel/14678
- Erasure encoding as a storage backend http://thread.gmane.org/gmane.comp.file-systems.ceph.devel/14866
Detailed Description¶
Acknowledgements¶
First of all, we want to acknowledge that the ideas presented here have been independenty tabled by Stephen Perkins and others on the ceph-devel mailing list.
Reasoning¶
For a class of users, there is a requirement for very durable data, but the cost of meeting that durability by usingxN replication becomes cost prohibitive if the size of the data to be stored is large. An example usecase where this is an issue is genomic data. By using a 3x replication, a 20PB genomic repository requires spinning 60+PB of disk. However, the other features of ceph are very attractive (such as using a common storage infrastructure for objects, blocks, and filesystems, CRUSH, self-healing infrastructure, non-disruptive scaling, etc.
Use Cases¶
Annai systems, as an organization that has an active OpenStack compute and storage fabric, needs to move to a more scalable storage system than we have today (currently 700 TB, scaling to Nx10's of PB over the immediate future, has a need for a solution that will reduce durability overhead in our fabric.
2 "tiered" storage
This model is related to the Azure storage model, as detailed in https://www.usenix.org/system/files/conference/atc12/atc12-final181_0.pdf. However, it is somewhat different.
What would be proposed here is that there are two pools of storage, however, only the first pool is seen by "normal" clients. That pool is "standard" ceph, with object replication as normal. As an OSD's used storage reaches a high-water mark, another process "demotes" one or more objects (until a low-water mark is satisfied) to the second tier, replacing the object with a "redirect object". That second tier is an erasure-encoded pool. If a "normal" client requests that object, the "redirect object" signals that the object should be re-assembled from the erasure-encoded backing store (second "tier"). The object is then placed in the first tier and the client's request is satisfied. At that point, the erasure encoded version of the object could be deleted, or could be left in place.
It is worthwhile to note that each OSD would perform this step independently. As all versions of the object would erasure encode (and be placed) in the same locations in the second tier (thanks to CRUSH), there would not be replication of the sharded data. The primary store could be seen as a cache for the backing (or erasure-encoded) store.
single "tier" storage
In this model, all data would be immediately erasure-encoded and stored. The would be replacing the current OSD replication model in all cases with an erasure-encoding backend.
Erasure Encoded Storage¶
- Ceph documentation
- References
- Facebook’s advanced erasure codes http://storagemojo.com/2013/06/21/facebooks-advanced-erasure-codes/
- XORing Elephants: Novel Erasure Codes for Big Data http://anrg.usc.edu/~maheswaran/Xorbas.pdf
- Indepth discussion of erasure coding ( section 2 ) Erasure Coding vs. Replication: A Quantitative Comparison
- A Performance Evaluation and Examination of Open-Source Erasure Coding Libraries For Storage http://www.usenix.org/events/fast09/tech/full_papers/plank/plank.pdf
- Erasure Coding in Windows Azure Storage https://www.usenix.org/system/files/conference/atc12/atc12-final181_0.pdf
- Optimizing Forward Error Correction Coding Using SIMD Instructions http://www.randombit.net/bitbashing/2009/01/19/forward_error_correction_using_simd.html
- How Good is Random Linear Coding Based Distributed Networked Storage? http://netcod.org/papers/11AcedanskiDMK-final.pdf
- Regenerating Codes: A System Perspective http://hal.archives-ouvertes.fr/docs/00/76/42/62/PDF/1204.5028v2.pdf
- Erasure Coding for Distributed Storage http://storagewiki.ece.utexas.edu/doku.php?id=start
- Rethinking Erasure Codes for Cloud File Systems: Minimizing I/O for Recovery and Degraded Reads http://static.usenix.org/event/fast12/tech/full_papers/Khan.pdf
- Software
- Xorbas Hadoop Project Page, Locally Repairable Codes (LRC) http://smahesh.com/HadoopUSC/
- GF-Complete: A Comprehensive Open Source Library for Galois Field Arithmetic http://web.eecs.utk.edu/~plank/plank/www/software.html http://web.eecs.utk.edu/~plank/plank/papers/CS-13-703/gf_complete_0.1.tar
- a fast erasure codec which can be used with the command-line, C, Python, or Haskell https://pypi.python.org/pypi/zfec
- FECpp is a BSD-licensed C++ forward error correction library. It is based on fec by Luigi Rizzo. http://www.randombit.net/code/fecpp/
- The HoloStor library for high performance erasure correcting encode/decode http://code.google.com/p/holostor/
Functional Approach¶
Below we outline a few possible paths to achieve the goal of an erasure encoded ceph backend. We are leaning to the staged approach models, but are putting all three paths that we have come up with in this document. Between the two stagged models proposed below, we can see a usecase for both, and do not find them to be mutually exclusive.
Common Considerations
Here are some design points that we believe are common to the introduction of any sharding or erasure encoding storage backend for ceph that would need to be decided on before an actual design could be completed. We have identified our prefered approach, with reasoning, but we are sure we've missed things here.
Who Does the sharding and placement?
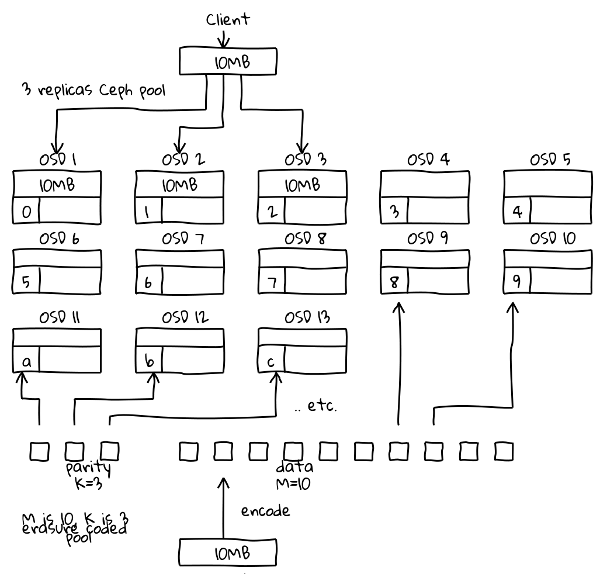
One approach would be for the primary OSD for a given object to erasure-encode the object and run CRUSH for the entire object with {num_replicas} set to be the desired k of the erasure encoding function. The OSD would store one of the shards in each OSD identified by CRUSH. Each OSD could become "primary" as in existing Ceph, and whichever OSD was "primary" would be responsible for re-calculating a missing or damaged shard when discovered by a deep scrub. Any OSD in that object's PG (the PG now encloses the shards for a given object) could assemble the object if requested by a client.
Another approach would be to have another process run on the OSD platform that would, given a set of inputs, take objects and shard them, sending the shards to a set of OSDs. In this case, this other process would be responsible for the sharding and re-assembly, as necessary.
Examples of this input could be the HWM/LWM mentioned in the two-tiered storage model above.
We now believe that the sharding OSD is the best approach.
Redirect object
In the two-tiered model, when an object is "evicted" from the primary pool, a "redirect object" could be placed in the filesystem to indicate that that object was now in the erasure-encoded backing-store. That "redirect object" could be a file with the same object name, but different meta-data, or it could be a file with the same object name, but with, perhaps, the sticky-bit set (or some other file attribute set that does not have other meaning to Ceph).
In either case, either the OSD would have to understand the meaning of that "redirect object" file, and know what to do when it processes a file that is identified as a "redirect object", or some other agent would need to understand and act transparently on that "redirect object" such that the OSD only ever sees an object file.
One possibility would be to run a "pass-through" fuse file as the file system that the OSD stores to. In most cases, that fuse filesystem would simply pass on the filesystem operations that the OSD is making. However, if the file that is being operated on is redirected, it, instead retrieves the file from the erasure-encoded backing store and replaces the redirection with the actual file, returning the actual file to the OSD. In this case, the primary pool OSD would never have to know about the erasure-encoded shard, and therefore, older versions of OSDs could interoperate in an environment where both erasure-encoded backing stores and current-mode Ceph operate.
We no longer see this as the best path forward, as it involves more "moving parts" and does not have a substantial benefit.
Erasure coded pool
A new pool type is introduced that encodes all objects using erasure codes instead of replicates. It only allows to create an object, write it sequentially and make it read-only after it is written in full. A later write would result in COW like behavior.
Staged, multiple pools
The pool R is replicated, pool E is erasure coded. When a condition is met ( object has not been modified for a long time for instance ), the object O from pool R is copied to pool E. A redirect object replaces the original object. When a write operation reaches the redirect object, the object O from pool E is copied back to pool R. The object O may, or may not be deleted from pool E. If it is not, and the object O is not modified in pool R, then it can be "copied" to pool E upon the above conditions, only in this case the "copy" is a NOOP as the object O already exists in pool E.
If this were done independenly for each OSD in pool R for a given object O, there would be no inter-OSD dependency beyond what is already requred in Ceph. Also, if pool R would comprised of faster storage (say SSD's or SAS drives), and pool E were comprised of slower media (such as SATA or spun-down drives), then pool R behaves as a cache for pool E.
Staged, single pool
The general idea could be that a pool can contain two types of objects : replicated and erasure coded. And there would be a background task such as scrubbing that would turn replicated objects into erasure coded objects under certain conditions. It would be complicated to modify the code accordingly. And since two pools can share the same hardware with a different hierarchy and rules, the complication is probably unnecessary.
Proposed model¶
Of these options, we would propose the following:
- The creation of an erasure-encoding aware PG
- The PG is configured with n and m where n = number of shards necessary to recover an object an m = the number of total shards created.
- The eraure-encoding/sharding function is run over the object, resulting in m shards being created
- The sharding process is caried out by the "primary" OSD in the PG.
- Those shards will be named as <object_handle>_<shard_suffix>_k_(m-1). The <shard_suffix> SHOULD be configurable. k = the specific shard within the m series. An example series, for object "example" with an object ID of <exmpl_id>, n = 10, m = 15 would be <exampl_id>_shard_00_14 through <example_id>_shard_14_14.
- The metadata of the shard would include the following, at a minimum:
- Original object name or handle
- The n and m settings of the PG
- The k of the shard.
- One or two hashes of the shard to validate the health of the shard during scrub.
- Each shard is then dispersed to an OSD that is part of the PG.
- Each OSD in a given PG will use the stored hash(es) for each shard that it has stored to detect if the shard has become corrupted.
- In case of corruption, the OSD that detected the corruption will signal the need for a re-shard to the primary OSD for that PG for the object who's shard is corrupted.
- The primary OSD will re-constitute the original object, and then re-shard it.
- The creation of a "redirect" object to support the use of erasure-encoding as a multi-tiered storage for Ceph.
- The non eOSD should not HAVE to know about the existence of a secondary tier of storage. However, it MAY know about it if desired.
- The use of a file-system or re-director would need to be provided to handle native OSDs.
- Some housekeeping process that is triggered by conditions (such as HWM and LWM) could be used to move objects between "tiers"
- The most simplistic model (which would meet goals) would be an "evictor" that would evict old or least-recently-used objects from the replicated pool R and place them in the erasure-encoded pool E. The return of the objects to pool R would occur on use.
- A system that only implemented erasure-encoded pools would simply be a degenerate case of the system proposed here. In which case no re-direction or housekeeping system would be necessary
Work items¶
Coding tasks¶
Etherpad: http://pad.ceph.com/p/Erasure_encoding_as_a_storage_backend
Build / release tasks¶
- TBD
Documentation tasks¶
- TBD
Updated by Jessica Mack almost 9 years ago · 2 revisions