Bug #62512
openosd msgr-worker high cpu 300% due to throttle-osd_client_messages get_or_fail_fail (osd_client_message_cap=256)
0%
Description
problem:
osd high cpu
# ceph daemon osd.0 perf dump throttle-osd_client_messages
{
"throttle-osd_client_messages": {
"val": 256,
"max": 256,
"get_started": 0,
"get": 147211691,
"get_sum": 147211691,
"get_or_fail_fail": 539294322,
"get_or_fail_success": 147211691,
"take": 0,
"take_sum": 0,
"put": 147211435,
"put_sum": 147211435,
"wait": {
"avgcount": 0,
"sum": 0.000000000,
"avgtime": 0.000000000
}
}
}
osd_client_message_cap change history :
1. https://github.com/ceph/ceph/commit/9087e3b751a78211011b39377394ceb297078f76
Revert "ceph_osd: remove client message cap limit"
This reverts commit 45d5ac3.
Without a msg throttler, we can't change osd_client_message_cap cap.
The throttler is designed to work with 0 as a max, so change the
default to 0 to disable it by default instead.
This doesn't affect the default behavior, it only lets us use this
option again.
Fixes: https://tracker.ceph.com/issues/46143
Conflicts:
src/ceph_osd.cc - new style of gconf() access
Signed-off-by: Josh Durgin <jdurgin@redhat.com>
Signed-off-by: Neha Ojha <nojha@redhat.com>
2. https://github.com/ceph/ceph/commit/ac8cf275a6d191d71c104f6822b62ba67a0a4fcd
common/options: Set osd_client_message_cap to 256.
This seems like a reasonable default value based on testing results here:
https://docs.google.com/spreadsheets/d/1dwKcxFKpAOWzDPekgojrJhfiCtPgiIf8CGGMG1rboRU/edit?usp=sharing
Eventually we may want to rethink how the throttles and even how flow control
works, but this at least gives us some basic limits now ( a little higher than
the old value of 100 that we used for many years).
Signed-off-by: Mark Nelson <mnelson@redhat.com>
Files
Updated by jianwei zhang 8 months ago
Question:
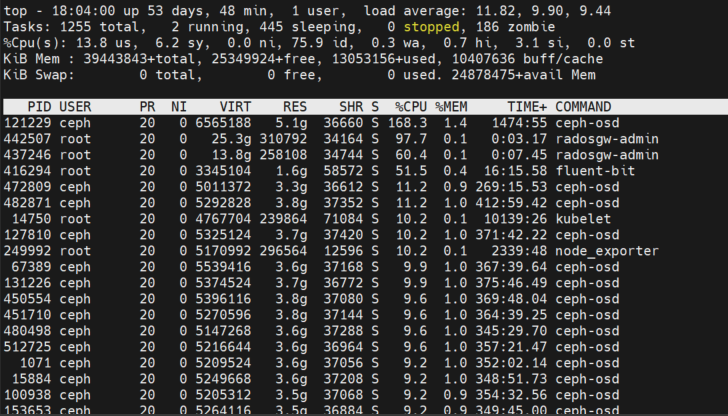
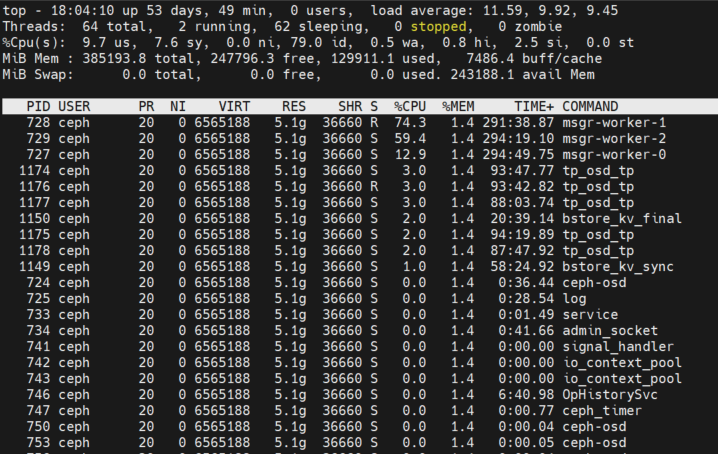
Osd throttle-osd_client_messages has been producing a lot of get_or_fail_fail.
Top-p < osd.pid > see that the total consumption of ceph-osd CPU is 168%.
Top-H-p < osd.pid > found that 3 msgr-worker-0/1/2 consumed cpu.
Updated by jianwei zhang 8 months ago
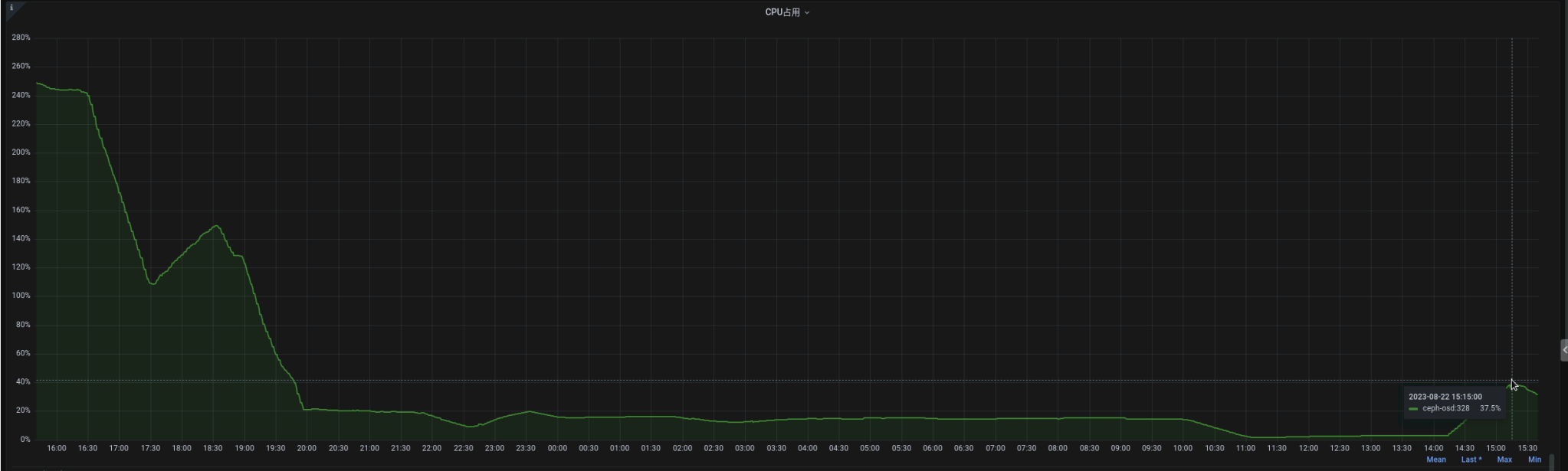
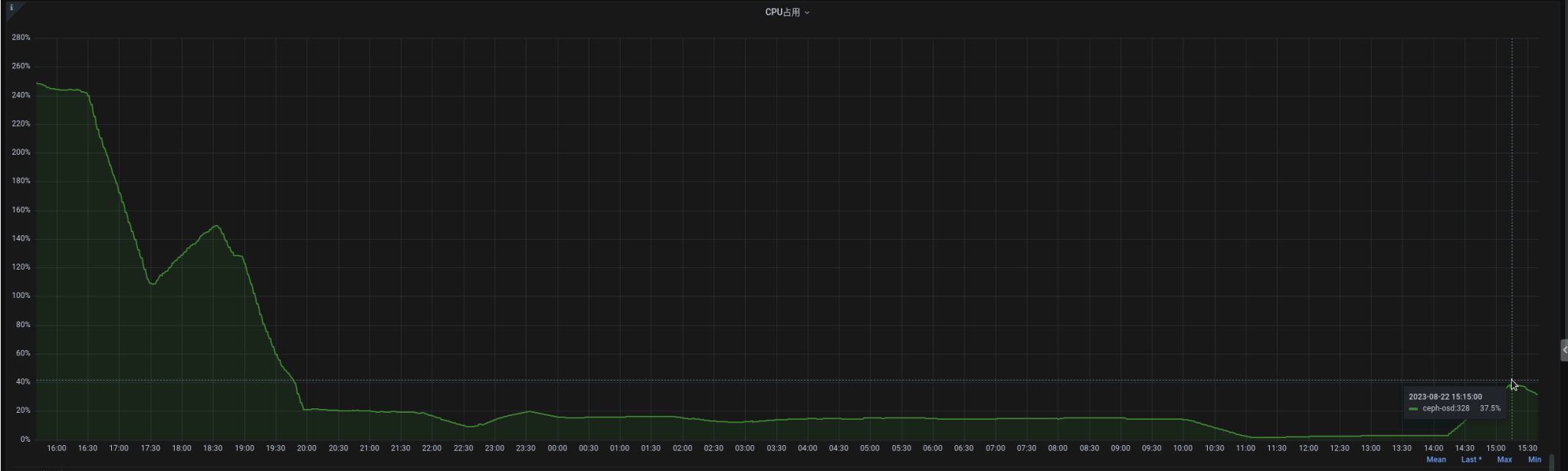
- File osd-cpu变化曲线.jpg osd-cpu变化曲线.jpg added
Updated by jianwei zhang 8 months ago
As shown in the figure,
16:00 ~ 20:00 osd_client_message_cap=256, cpu high to 200%
after 20:00 osd_client_message_cap=1000000, cpu reduce to 20%
When I change osd_client_message_cap to 1000000 (which means no limit).
Osd's msgr-worker thread cpu consumption was immediately reduced from 200% to 20%.
I was thinking that this problem might also be caused by the depletion of the osd_client_message_size_cap (500m) throttle_bytes.
Question:
When an osd receives a large amount of connection and reads tcp data, after reaching the throttle limit, how can we avoid the high cpu consumption of msgr-worker?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Updated by jianwei zhang 8 months ago
CtPtr ProtocolV2::throttle_message() {
ldout(cct, 20) << __func__ << dendl;
if (connection->policy.throttler_messages) {
ldout(cct, 10) << __func__ << " wants " << 1
<< " message from policy throttler "
<< connection->policy.throttler_messages->get_current()
<< "/" << connection->policy.throttler_messages->get_max()
<< dendl;
if (!connection->policy.throttler_messages->get_or_fail()) {
ldout(cct, 1) << __func__ << " wants 1 message from policy throttle "
<< connection->policy.throttler_messages->get_current()
<< "/" << connection->policy.throttler_messages->get_max()
<< " failed, just wait." << dendl;
// following thread pool deal with th full message queue isn't a
// short time, so we can wait a ms.
if (connection->register_time_events.empty()) {
connection->register_time_events.insert(
connection->center->create_time_event(1000,
connection->wakeup_handler));
}
return nullptr;
}
}
state = THROTTLE_BYTES;
return CONTINUE(throttle_bytes);
}
CtPtr ProtocolV2::throttle_bytes() {
ldout(cct, 20) << __func__ << dendl;
const size_t cur_msg_size = get_current_msg_size();
if (cur_msg_size) {
if (connection->policy.throttler_bytes) {
ldout(cct, 10) << __func__ << " wants " << cur_msg_size
<< " bytes from policy throttler "
<< connection->policy.throttler_bytes->get_current() << "/"
<< connection->policy.throttler_bytes->get_max() << dendl;
if (!connection->policy.throttler_bytes->get_or_fail(cur_msg_size)) {
ldout(cct, 1) << __func__ << " wants " << cur_msg_size
<< " bytes from policy throttler "
<< connection->policy.throttler_bytes->get_current()
<< "/" << connection->policy.throttler_bytes->get_max()
<< " failed, just wait." << dendl;
// following thread pool deal with th full message queue isn't a
// short time, so we can wait a ms.
if (connection->register_time_events.empty()) {
connection->register_time_events.insert(
connection->center->create_time_event(
1000, connection->wakeup_handler));
}
return nullptr;
}
}
}
state = THROTTLE_DISPATCH_QUEUE;
return CONTINUE(throttle_dispatch_queue);
}
CtPtr ProtocolV2::throttle_dispatch_queue() {
ldout(cct, 20) << __func__ << dendl;
const size_t cur_msg_size = get_current_msg_size();
if (cur_msg_size) {
if (!connection->dispatch_queue->dispatch_throttler.get_or_fail(
cur_msg_size)) {
ldout(cct, 1)
<< __func__ << " wants " << cur_msg_size
<< " bytes from dispatch throttle "
<< connection->dispatch_queue->dispatch_throttler.get_current() << "/"
<< connection->dispatch_queue->dispatch_throttler.get_max()
<< " failed, just wait." << dendl;
// following thread pool deal with th full message queue isn't a
// short time, so we can wait a ms.
if (connection->register_time_events.empty()) {
connection->register_time_events.insert(
connection->center->create_time_event(1000,
connection->wakeup_handler));
}
return nullptr;
}
}
throttle_stamp = ceph_clock_now();
state = THROTTLE_DONE;
return read_frame_segment();
}
uint64_t EventCenter::create_time_event(uint64_t microseconds, EventCallbackRef ctxt)
{
ceph_assert(in_thread());
uint64_t id = time_event_next_id++;
ldout(cct, 30) << __func__ << " id=" << id << " trigger after " << microseconds << "us"<< dendl;
EventCenter::TimeEvent event;
clock_type::time_point expire = clock_type::now() + std::chrono::microseconds(microseconds);
event.id = id;
event.time_cb = ctxt;
std::multimap<clock_type::time_point, TimeEvent>::value_type s_val(expire, event);
auto it = time_events.insert(std::move(s_val));
event_map[id] = it;
return id;
}
std::function<void ()> NetworkStack::add_thread(Worker* w)
{
return [this, w]() {
rename_thread(w->id);
const unsigned EventMaxWaitUs = 30000000;
w->center.set_owner();
ldout(cct, 10) << __func__ << " starting" << dendl;
w->initialize();
w->init_done();
while (!w->done) {
ldout(cct, 30) << __func__ << " calling event process" << dendl;
ceph::timespan dur;
int r = w->center.process_events(EventMaxWaitUs, &dur);
if (r < 0) {
ldout(cct, 20) << __func__ << " process events failed: "
<< cpp_strerror(errno) << dendl;
// TODO do something?
}
w->perf_logger->tinc(l_msgr_running_total_time, dur);
}
w->reset();
w->destroy();
};
}
int EventCenter::process_events(unsigned timeout_microseconds, ceph::timespan *working_dur)
{
struct timeval tv;
int numevents;
bool trigger_time = false;
auto now = clock_type::now();
clock_type::time_point end_time = now + std::chrono::microseconds(timeout_microseconds);
auto it = time_events.begin();
if (it != time_events.end() && end_time >= it->first) {
trigger_time = true;
end_time = it->first;
if (end_time > now) {
timeout_microseconds = std::chrono::duration_cast<std::chrono::microseconds>(end_time - now).count();
} else {
timeout_microseconds = 0;
}
}
bool blocking = pollers.empty() && !external_num_events.load();
if (!blocking)
timeout_microseconds = 0;
tv.tv_sec = timeout_microseconds / 1000000;
tv.tv_usec = timeout_microseconds % 1000000;
ldout(cct, 30) << __func__ << " wait second " << tv.tv_sec << " usec " << tv.tv_usec << dendl;
std::vector<FiredFileEvent> fired_events;
numevents = driver->event_wait(fired_events, &tv);
auto working_start = ceph::mono_clock::now();
for (int event_id = 0; event_id < numevents; event_id++) {
int rfired = 0;
FileEvent *event;
EventCallbackRef cb;
event = _get_file_event(fired_events[event_id].fd);
/* note the event->mask & mask & ... code: maybe an already processed
* event removed an element that fired and we still didn't
* processed, so we check if the event is still valid. */
if (event->mask & fired_events[event_id].mask & EVENT_READABLE) {
rfired = 1;
cb = event->read_cb;
cb->do_request(fired_events[event_id].fd);
}
if (event->mask & fired_events[event_id].mask & EVENT_WRITABLE) {
if (!rfired || event->read_cb != event->write_cb) {
cb = event->write_cb;
cb->do_request(fired_events[event_id].fd);
}
}
ldout(cct, 30) << __func__ << " event_wq process is " << fired_events[event_id].fd
<< " mask is " << fired_events[event_id].mask << dendl;
}
if (trigger_time)
numevents += process_time_events();
if (external_num_events.load()) {
external_lock.lock();
std::deque<EventCallbackRef> cur_process;
cur_process.swap(external_events);
external_num_events.store(0);
external_lock.unlock();
numevents += cur_process.size();
while (!cur_process.empty()) {
EventCallbackRef e = cur_process.front();
ldout(cct, 30) << __func__ << " do " << e << dendl;
e->do_request(0);
cur_process.pop_front();
}
}
if (!numevents && !blocking) {
for (uint32_t i = 0; i < pollers.size(); i++)
numevents += pollers[i]->poll();
}
if (working_dur)
*working_dur = ceph::mono_clock::now() - working_start;
return numevents;
}
int EventCenter::process_time_events()
{
int processed = 0;
clock_type::time_point now = clock_type::now();
using ceph::operator <<;
ldout(cct, 30) << __func__ << " cur time is " << now << dendl;
while (!time_events.empty()) {
auto it = time_events.begin();
if (now >= it->first) {
TimeEvent &e = it->second;
EventCallbackRef cb = e.time_cb;
uint64_t id = e.id;
time_events.erase(it);
event_map.erase(id);
ldout(cct, 30) << __func__ << " process time event: id=" << id << dendl;
processed++;
cb->do_request(id);
} else {
break;
}
}
return processed;
}
Updated by jianwei zhang 8 months ago
reproduce :
# ceph versions
{
"mon": {
"ceph version 18.1.0-0 (c2214eb5df9fa034cc571d81a32a5414d60f0405) reef (rc)": 1
},
"mgr": {
"ceph version 18.1.0-0 (c2214eb5df9fa034cc571d81a32a5414d60f0405) reef (rc)": 1
},
"osd": {
"ceph version 18.1.0-0 (c2214eb5df9fa034cc571d81a32a5414d60f0405) reef (rc)": 1
},
"overall": {
"ceph version 18.1.0-0 (c2214eb5df9fa034cc571d81a32a5414d60f0405) reef (rc)": 3
}
}
# ceph -s
cluster:
id: dcc749b4-c686-453b-8f25-6b965cdb360f
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 119s)
mgr: x(active, since 106s)
osd: 1 osds: 1 up (since 104s), 1 in (since 2w)
data:
pools: 2 pools, 129 pgs
objects: 17.80M objects, 1.7 TiB
usage: 2.0 TiB used, 7.4 TiB / 9.4 TiB avail
pgs: 129 active+clean
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 9.39259 root default
-3 9.39259 host node-01
0 hdd 9.39259 osd.0 up 1.00000 1.00000
# ceph osd crush rule dump
[
{
"rule_id": 0,
"rule_name": "replicated_rule",
"type": 1,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "choose_firstn",
"num": 0,
"type": "osd"
},
{
"op": "emit"
}
]
}
]
# ceph osd pool ls detail
pool 1 '.mgr' replicated size 1 min_size 1 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 8 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 1.00
pool 2 'test-pool' replicated size 1 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode off last_change 20 flags hashpspool stripe_width 0 application rgw read_balance_score 1.00
# ceph daemon osd.0 config show | grep _message_
"osd_client_message_cap": "256",
"osd_client_message_size_cap": "524288000",
# ceph daemon osd.0 perf dump throttle-osd_client_messages
{
"throttle-osd_client_messages": {
"val": 0,
"max": 256,
"get_started": 0,
"get": 45,
"get_sum": 45,
"get_or_fail_fail": 0,
"get_or_fail_success": 45,
"take": 0,
"take_sum": 0,
"put": 45,
"put_sum": 45,
"wait": {
"avgcount": 0,
"sum": 0.000000000,
"avgtime": 0.000000000
}
}
}
# cat test-bench-write.sh
for i in {1..4000} ; do
name1=$(echo $RANDOM)
name2=$(echo $RANDOM)
echo "test-bench-write-$name1-$name2"
nohup rados -c ./ceph.conf bench 7201 write --no-cleanup -t 1 -p test-pool -b 102434 --show-time --run-name "test-bench-write-$name1-$name2" >> writelog 2>&1 &
done
# netstat -apn |grep 207791 |wc -l
4008
# ps aux |grep 7201 | grep bench | wc -l
4000
Every 2.0s: ceph daemon osd.0 perf dump throttle-osd_client_messages SZJD-YFQ-PM-OS01-BCONEST-06: Tue Aug 22 09:03:21 2023
{
"throttle-osd_client_messages": {
"val": 256,
"max": 256,
"get_started": 0,
"get": 165176,
"get_sum": 165176,
"get_or_fail_fail": 1083021238,
"get_or_fail_success": 165176,
"take": 0,
"take_sum": 0,
"put": 164920,
"put_sum": 164920,
"wait": {
"avgcount": 0,
"sum": 0.000000000,
"avgtime": 0.000000000
}
}
}
Every 2.0s: ceph daemon osd.0 perf dump throttle-osd_client_messages SZJD-YFQ-PM-OS01-BCONEST-06: Tue Aug 22 09:03:33 2023
{
"throttle-osd_client_messages": {
"val": 256,
"max": 256,
"get_started": 0,
"get": 165797,
"get_sum": 165797,
"get_or_fail_fail": 1116869671,
"get_or_fail_success": 165797,
"take": 0,
"take_sum": 0,
"put": 165541,
"put_sum": 165541,
"wait": {
"avgcount": 0,
"sum": 0.000000000,
"avgtime": 0.000000000
}
}
}
# top -d 1
top - 09:04:52 up 32 days, 2:52, 0 users, load average: 15.92, 18.04, 14.95
Tasks: 12 total, 1 running, 11 sleeping, 0 stopped, 0 zombie
%Cpu(s): 17.8 us, 14.3 sy, 0.0 ni, 66.2 id, 1.5 wa, 0.0 hi, 0.2 si, 0.0 st
MiB Mem : 128653.1 total, 6153.0 free, 83353.8 used, 39146.2 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 43776.2 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
207791 root 20 0 1299468 645520 19008 S 302.0 0.5 24:44.35 ceph-osd
199716 root 20 0 668520 110400 14044 S 3.3 0.1 0:56.61 ceph-mon
200019 root 20 0 5632212 436192 18904 S 0.3 0.3 0:21.70 ceph-mgr
# top -H -d 1 -p 207791
top - 09:03:51 up 32 days, 2:51, 0 users, load average: 20.18, 19.05, 15.03
Threads: 64 total, 3 running, 61 sleeping, 0 stopped, 0 zombie
%Cpu(s): 18.6 us, 16.3 sy, 0.0 ni, 63.9 id, 0.9 wa, 0.0 hi, 0.3 si, 0.0 st
MiB Mem : 128653.1 total, 3911.6 free, 83255.9 used, 41485.5 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 43874.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
207806 root 20 0 1299468 645496 19008 R 99.9 0.5 7:00.66 msgr-worker-2
207804 root 20 0 1299468 645496 19008 R 99.0 0.5 7:00.55 msgr-worker-0
207805 root 20 0 1299468 645496 19008 R 99.0 0.5 7:00.41 msgr-worker-1
208289 root 20 0 1299468 645496 19008 S 1.0 0.5 0:04.05 tp_osd_tp
208292 root 20 0 1299468 645496 19008 S 1.0 0.5 0:03.55 tp_osd_tp
207791 root 20 0 1299468 645496 19008 S 0.0 0.5 0:01.02 ceph-osd
207793 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 log
207794 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.04 service
207795 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.32 admin_socket
207807 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 signal_handler
207808 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 io_context_pool
207809 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 io_context_pool
207819 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.77 OpHistorySvc
207820 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.01 ceph_timer
207827 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ceph-osd
207836 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ceph-osd
207844 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ceph-osd
207853 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ceph-osd
207863 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ceph-osd
207864 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ceph-osd
207865 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.13 safe_timer
207866 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.42 safe_timer
207867 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 safe_timer
207868 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 safe_timer
207869 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 fn_anonymous
207870 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.97 bstore_aio
207879 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 rocksdb:low
207880 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 rocksdb:low
207881 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 rocksdb:low
207882 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 rocksdb:high
208065 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.22 bstore_aio
208067 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.19 bstore_aio
208068 root 20 0 1299468 645496 19008 S 0.0 0.5 0:01.02 bstore_aio
208255 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ceph-osd
208257 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 cfin
208258 root 20 0 1299468 645496 19008 S 0.0 0.5 0:08.01 bstore_kv_sync
208259 root 20 0 1299468 645496 19008 S 0.0 0.5 0:01.39 bstore_kv_final
208260 root 20 0 1299468 645496 19008 S 0.0 0.5 0:02.26 bstore_mempool
208267 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.14 ms_dispatch
208268 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ms_local
208269 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.10 safe_timer
208270 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.04 safe_timer
208271 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ms_dispatch
208272 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ms_local
208273 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ms_dispatch
208274 root 20 0 1299468 645496 19008 S 0.0 0.5 0:00.00 ms_local
Updated by jianwei zhang 8 months ago
Samples: 916K of event 'cycles:u', 4000 Hz, Event count (approx.): 96318727172 lost: 0/0 drop: 0/0
Children Self Shared Object Symbol
+ 83.50% 7.21% ceph-osd [.] EventCenter::process_time_events
+ 75.71% 0.02% ceph-osd [.] EventCenter::process_events
+ 69.53% 0.31% ceph-osd [.] AsyncConnection::wakeup_from
+ 69.09% 0.02% ceph-osd [.] std::_Function_handler<void (), NetworkStack::add_thread(Worker*)::{lambda()#1}>::_M_invoke
+ 65.16% 6.31% ceph-osd [.] AsyncConnection::process
+ 51.00% 0.95% ceph-osd [.] ProtocolV2::throttle_message
+ 50.00% 0.42% ceph-osd [.] ProtocolV2::run_continuation
+ 31.46% 13.14% ceph-osd [.] EventCenter::create_time_event
+ 18.95% 5.42% ceph-osd [.] Throttle::get_or_fail
+ 16.20% 12.84% ceph-osd [.] std::_Rb_tree<std::chrono::time_point<ceph::coarse_mono_clock, std::chrono::duration<unsigned long, std::ratio<1l, 1000000000l> > >, std::p
+ 13.09% 12.46% libpthread-2.28.so [.] __pthread_mutex_lock
+ 11.84% 0.01% ceph-osd [.] pthread_mutex_lock@plt
+ 6.65% 6.65% libstdc++.so.6.0.25 [.] std::_Rb_tree_rebalance_for_erase
+ 6.55% 1.12% libc-2.28.so [.] clock_gettime@GLIBC_2.2.5
+ 6.53% 0.10% ceph-osd [.] std::_Rb_tree_rebalance_for_erase@plt
+ 5.83% 5.67% libpthread-2.28.so [.] __pthread_mutex_unlock_usercnt
+ 5.62% 5.62% [vdso] [.] __vdso_clock_gettime
+ 4.65% 4.65% libstdc++.so.6.0.25 [.] std::_Rb_tree_insert_and_rebalance
+ 4.50% 0.05% ceph-osd [.] std::_Rb_tree_insert_and_rebalance@plt
+ 4.45% 0.06% ceph-osd [.] pthread_mutex_unlock@plt
+ 4.41% 4.41% ceph-osd [.] ceph::common::PerfCounters::inc
+ 2.90% 2.90% libtcmalloc.so.4.5.3 [.] tc_deletearray_aligned_nothrow
+ 2.89% 0.10% ceph-osd [.] operator delete@plt
+ 2.72% 1.98% ceph-osd [.] std::_Rb_tree<unsigned long, unsigned long, std::_Identity<unsigned long>, std::less<unsigned long>, std::allocator<unsigned long> >::erase
2.57% 0.00% ceph-osd [.] rocksdb::DBImpl::WriteToWAL
2.40% 0.00% ceph-osd [.] rocksdb::DBImpl::WriteImpl
+ 1.72% 1.31% ceph-osd [.] ProtocolV2::read_event
+ 1.71% 1.70% ceph-osd [.] ceph::common::PerfCounters::tinc
+ 1.40% 0.12% ceph-osd [.] operator new@plt
+ 1.34% 1.34% libtcmalloc.so.4.5.3 [.] operator new[]
+ 1.17% 0.09% ceph-osd [.] clock_gettime@plt
+ 1.03% 0.10% ceph-osd [.] CtFun<ProtocolV2>::call
0.87% 0.00% ceph-osd [.] rocksdb::WritableFileWriter::SyncInternal
0.79% 0.49% ceph-osd [.] C_time_wakeup::do_request
0.76% 0.36% ceph-osd [.] std::_Rb_tree<unsigned long, unsigned long, std::_Identity<unsigned long>, std::less<unsigned long>, std::allocator<unsigned long> >::_M_er
0.66% 0.64% libpthread-2.28.so [.] __lll_lock_wait
0.56% 0.00% ceph-osd [.] rocksdb::(anonymous namespace)::LegacyWritableFileWrapper::Sync
0.41% 0.00% ceph-osd [.] rocksdb::DBImpl::Write
+ 0.36% 0.00% ceph-osd [.] RocksDBStore::submit_transaction_sync
0.32% 0.00% ceph-osd [.] RocksDBStore::submit_common
0.29% 0.29% ceph-osd [.] std::_Rb_tree<unsigned long, std::pair<unsigned long const, std::_Rb_tree_iterator<std::pair<std::chrono::time_point<ceph::coarse_mono_cloc
0.21% 0.21% libstdc++.so.6.0.25 [.] std::_Rb_tree_increment
0.21% 0.00% ceph-osd [.] std::_Rb_tree_increment@plt
0.17% 0.09% libpthread-2.28.so [.] __lll_unlock_wake
0.16% 0.16% libpthread-2.28.so [.] __pthread_mutex_unlock
0.11% 0.11% [kernel] [k] system_call
0.09% 0.00% [unknown] [.] 0x0000000000000051
0.08% 0.00% ceph-osd [.] PrimaryLogPG::do_op
0.08% 0.00% ceph-osd [.] PrimaryLogPG::execute_ctx
0.07% 0.00% ceph-osd [.] ReplicatedBackend::submit_transaction
0.07% 0.00% ceph-osd [.] PrimaryLogPG::issue_repop
0.06% 0.00% [unknown] [.] 0x0000000000000121
0.06% 0.00% ceph-osd [.] BlueStore::queue_transactions
0.06% 0.00% [unknown] [.] 0x0000000000000071
Samples: 1M of event 'cycles:u', 4000 Hz, Event count (approx.): 171944543804 lost: 0/0 drop: 0/0
Children Self Shared Object Symbol
- 77.43% 7.32% ceph-osd [.] EventCenter::process_time_events ◆
- 13.13% EventCenter::process_time_events ▒
- 16.27% AsyncConnection::wakeup_from ▒
- 16.36% AsyncConnection::process ▒
+ 3.73% clock_gettime@GLIBC_2.2.5 ▒
- 2.84% ProtocolV2::run_continuation ▒
- 14.31% ProtocolV2::throttle_message ▒
- 19.39% EventCenter::create_time_event ▒
10.53% std::_Rb_tree<std::chrono::time_point<ceph::coarse_mono_clock, std::chrono::duration<unsigned long, std::ratio<1l, 1000000000l> > >, std::pair<std::chrono::▒
- 12.51% Throttle::get_or_fail ▒
3.85% pthread_mutex_lock@plt ▒
2.91% ceph::common::PerfCounters::inc ▒
4.24% pthread_mutex_lock@plt ▒
6.04% std::_Rb_tree_rebalance_for_erase@plt ▒
+ 72.99% 0.02% ceph-osd [.] EventCenter::process_events ▒
+ 68.35% 0.02% ceph-osd [.] std::_Function_handler<void (), NetworkStack::add_thread(Worker*)::{lambda()#1}>::_M_invoke ▒
+ 66.86% 0.32% ceph-osd [.] AsyncConnection::wakeup_from ▒
+ 62.80% 6.40% ceph-osd [.] AsyncConnection::process ▒
+ 50.23% 1.00% ceph-osd [.] ProtocolV2::throttle_message ▒
+ 48.29% 0.46% ceph-osd [.] ProtocolV2::run_continuation ▒
+ 31.39% 12.97% ceph-osd [.] EventCenter::create_time_event ▒
+ 18.51% 5.20% ceph-osd [.] Throttle::get_or_fail ▒
+ 16.22% 12.82% ceph-osd [.] std::_Rb_tree<std::chrono::time_point<ceph::coarse_mono_clock, std::chrono::duration<unsigned long, std::ratio<1l, 1000000000l> > >, s▒
+ 12.89% 12.28% libpthread-2.28.so [.] __pthread_mutex_lock ▒
+ 11.62% 0.01% ceph-osd [.] pthread_mutex_lock@plt ▒
+ 6.73% 6.73% libstdc++.so.6.0.25 [.] std::_Rb_tree_rebalance_for_erase ▒
+ 6.44% 1.17% libc-2.28.so [.] clock_gettime@GLIBC_2.2.5 ▒
+ 6.34% 0.09% ceph-osd [.] std::_Rb_tree_rebalance_for_erase@plt ▒
+ 5.67% 5.50% libpthread-2.28.so [.] __pthread_mutex_unlock_usercnt ▒
+ 5.53% 5.53% [vdso] [.] __vdso_clock_gettime ▒
5.47% 0.00% ceph-osd [.] rocksdb::DBImpl::WriteToWAL ▒
+ 4.76% 4.76% libstdc++.so.6.0.25 [.] std::_Rb_tree_insert_and_rebalance ▒
+ 4.61% 0.04% ceph-osd [.] std::_Rb_tree_insert_and_rebalance@plt ▒
+ 4.55% 4.55% ceph-osd [.] ceph::common::PerfCounters::inc ▒
+ 4.29% 0.06% ceph-osd [.] pthread_mutex_unlock@plt ▒
3.21% 0.00% ceph-osd [.] rocksdb::DBImpl::WriteImpl ▒
+ 2.96% 2.96% libtcmalloc.so.4.5.3 [.] tc_deletearray_aligned_nothrow ▒
+ 2.86% 0.11% ceph-osd [.] operator delete@plt
Updated by jianwei zhang 8 months ago
# ceph daemon osd.0 config set osd_client_message_cap 0
{
"success": "osd_client_message_cap = '0' "
}
Threads: 64 total, 0 running, 64 sleeping, 0 stopped, 0 zombie
%Cpu(s): 11.4 us, 14.1 sy, 0.0 ni, 71.1 id, 3.1 wa, 0.0 hi, 0.3 si, 0.0 st
MiB Mem : 128653.1 total, 3271.9 free, 83446.0 used, 41935.2 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 43684.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
207804 root 20 0 1595404 941988 19244 S 1.0 0.7 26:56.29 msgr-worker-0
207806 root 20 0 1595404 941988 19244 S 1.0 0.7 26:56.37 msgr-worker-2
208258 root 20 0 1595404 941988 19244 S 1.0 0.7 0:12.45 bstore_kv_sync
208293 root 20 0 1595404 941988 19244 S 1.0 0.7 0:06.02 tp_osd_tp
207791 root 20 0 1595404 941988 19244 S 0.0 0.7 0:01.02 ceph-osd
207793 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.03 log
207794 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.06 service
207795 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.34 admin_socket
207805 root 20 0 1595404 941988 19244 S 0.0 0.7 26:56.19 msgr-worker-1
207807 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 signal_handler
207808 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 io_context_pool
207809 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 io_context_pool
207819 root 20 0 1595404 941988 19244 S 0.0 0.7 0:01.22 OpHistorySvc
207820 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.02 ceph_timer
207827 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ceph-osd
207836 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ceph-osd
207844 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ceph-osd
207853 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ceph-osd
207863 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ceph-osd
207864 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ceph-osd
207865 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.19 safe_timer
207866 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.69 safe_timer
207867 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 safe_timer
207868 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 safe_timer
207869 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 fn_anonymous
207870 root 20 0 1595404 941988 19244 S 0.0 0.7 0:01.57 bstore_aio
207879 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 rocksdb:low
207880 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 rocksdb:low
207881 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 rocksdb:low
207882 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 rocksdb:high
208065 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.35 bstore_aio
208067 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.30 bstore_aio
208068 root 20 0 1595404 941988 19244 S 0.0 0.7 0:01.64 bstore_aio
208255 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.01 ceph-osd
208257 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 cfin
208259 root 20 0 1595404 941988 19244 S 0.0 0.7 0:02.09 bstore_kv_final
208260 root 20 0 1595404 941988 19244 S 0.0 0.7 0:03.58 bstore_mempool
208267 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.14 ms_dispatch
208268 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_local
208269 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.15 safe_timer
208270 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.06 safe_timer
208271 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_dispatch
208272 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_local
208273 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_dispatch
208274 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_local
208275 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_dispatch
208276 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_local
208277 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_dispatch
208278 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_local
208279 root 20 0 1595404 941988 19244 S 0.0 0.7 0:00.00 ms_dispatch
Updated by jianwei zhang 8 months ago
After loosening the restriction on osd_client_message_cap, msgr-worker cpu is reduced to 1%.
But the throttle-osd_client_bytes reached 400 M.
Every 2.0s: ceph daemon osd.0 perf dump throttle-osd_client_messages SZJD-YFQ-PM-OS01-BCONEST-06: Tue Aug 22 09:26:22 2023
{
"throttle-osd_client_messages": {
"val": 259,
"max": 0,
"get_started": 0,
"get": 935894,
"get_sum": 935894,
"get_or_fail_fail": 4699479874,
"get_or_fail_success": 935894,
"take": 0,
"take_sum": 0,
"put": 935636,
"put_sum": 935636,
"wait": {
"avgcount": 0,
"sum": 0.000000000,
"avgtime": 0.000000000
}
}
}
[root@SZJD-YFQ-PM-OS01-BCONEST-06 qos-vstart-ceph-shequ]# ceph daemon osd.0 perf dump throttle-osd_client_bytes
{
"throttle-osd_client_bytes": {
"val": 410956347,
"max": 524288000,
"get_started": 0,
"get": 53106,
"get_sum": 5455545794,
"get_or_fail_fail": 0,
"get_or_fail_success": 53106,
"take": 0,
"take_sum": 0,
"put": 1507472,
"put_sum": 5044589447,
"wait": {
"avgcount": 0,
"sum": 0.000000000,
"avgtime": 0.000000000
}
}
}
Updated by jianwei zhang 8 months ago
Continue to increase client traffic
When the. osd_client_message_size_cap upper limit is reached, it will still cause the problem of high msgr worker cpu.
- ps aux | grep rados | grep 7201 | wc -l
6352
top - 09:34:02 up 32 days, 3:22, 0 users, load average: 19.39, 21.14, 18.35
Threads: 64 total, 2 running, 62 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.8 us, 12.2 sy, 0.0 ni, 76.7 id, 3.1 wa, 0.0 hi, 0.3 si, 0.0 st
MiB Mem : 128653.1 total, 835.6 free, 97647.2 used, 30170.3 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 29483.1 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
207804 root 20 0 1797132 1.1g 13856 R 34.7 0.9 28:09.42 msgr-worker-0
207805 root 20 0 1797132 1.1g 13856 S 33.7 0.9 28:08.33 msgr-worker-1
207806 root 20 0 1797132 1.1g 13856 R 33.7 0.9 28:12.87 msgr-worker-2
207791 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:01.02 ceph-osd
207793 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.08 log
207794 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.08 service
207795 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.46 admin_socket
207807 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 signal_handler
207808 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 io_context_pool
207809 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 io_context_pool
207819 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:01.48 OpHistorySvc
207820 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.02 ceph_timer
207827 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 ceph-osd
207836 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 ceph-osd
207844 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 ceph-osd
207853 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 ceph-osd
207863 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 ceph-osd
207864 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.01 ceph-osd
207865 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.23 safe_timer
207866 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:01.53 safe_timer
207867 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 safe_timer
207868 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 safe_timer
207869 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:00.00 fn_anonymous
207870 root 20 0 1797132 1.1g 13856 S 0.0 0.9 0:01.90 bstore_aioEvery 2.0s: ceph daemon osd.0 perf dump throttle-osd_client_bytes SZJD-YFQ-PM-OS01-BCONEST-06: Tue Aug 22 09:33:35 2023
{
"throttle-osd_client_bytes": {
"val": 524277488,
"max": 524288000,
"get_started": 0,
"get": 60394,
"get_sum": 6204308242,
"get_or_fail_fail": 158171033,
"get_or_fail_success": 60394,
"take": 0,
"take_sum": 0,
"put": 1892304,
"put_sum": 5680030754,
"wait": {
"avgcount": 0,
"sum": 0.000000000,
"avgtime": 0.000000000
}
}
}
Every 2.0s: ceph daemon osd.0 perf dump throttle-osd_client_bytes SZJD-YFQ-PM-OS01-BCONEST-06: Tue Aug 22 09:33:46 2023
{
"throttle-osd_client_bytes": {
"val": 524277486,
"max": 524288000,
"get_started": 0,
"get": 60574,
"get_sum": 6222801278,
"get_or_fail_fail": 169469646,
"get_or_fail_success": 60574,
"take": 0,
"take_sum": 0,
"put": 1906583,
"put_sum": 5698523792,
"wait": {
"avgcount": 0,
"sum": 0.000000000,
"avgtime": 0.000000000
}
}
}
Samples: 34K of event 'cycles:u', 4000 Hz, Event count (approx.): 11419273250 lost: 0/0 drop: 0/0
Children Self Shared Object Symbol
+ 75.39% 7.96% ceph-osd [.] EventCenter::process_time_events
+ 74.80% 6.55% ceph-osd [.] AsyncConnection::process
+ 73.15% 0.32% ceph-osd [.] AsyncConnection::wakeup_from
+ 69.68% 0.46% ceph-osd [.] ProtocolV2::run_continuation
+ 67.01% 0.13% ceph-osd [.] EventCenter::process_events
+ 62.15% 0.05% ceph-osd [.] std::_Function_handler<void (), NetworkStack::add_thread(Worker*)::{lambda()#1}>::_M_invoke
+ 44.44% 1.00% ceph-osd [.] ProtocolV2::throttle_bytes
+ 29.77% 11.62% ceph-osd [.] EventCenter::create_time_event
+ 16.65% 12.89% ceph-osd [.] std::_Rb_tree<std::chrono::time_point<ceph::coarse_mono_clock, std::chrono::duration<unsigned long, std::ratio<1l, 1000000000l> > >, std::p
+ 11.91% 4.29% ceph-osd [.] Throttle::get_or_fail
+ 10.19% 10.00% libpthread-2.28.so [.] __pthread_mutex_lock
+ 9.59% 0.02% ceph-osd [.] pthread_mutex_lock@plt
+ 7.39% 7.39% libstdc++.so.6.0.25 [.] std::_Rb_tree_rebalance_for_erase
+ 6.78% 0.08% ceph-osd [.] std::_Rb_tree_rebalance_for_erase@plt
+ 6.46% 1.35% libc-2.28.so [.] clock_gettime@GLIBC_2.2.5
+ 5.67% 5.67% [vdso] [.] __vdso_clock_gettime
+ 5.28% 5.28% libstdc++.so.6.0.25 [.] std::_Rb_tree_insert_and_rebalance
+ 4.97% 0.06% ceph-osd [.] std::_Rb_tree_insert_and_rebalance@plt
+ 4.63% 4.59% libpthread-2.28.so [.] __pthread_mutex_unlock_usercnt
+ 3.57% 3.57% libtcmalloc.so.4.5.3 [.] tc_deletearray_aligned_nothrow
+ 3.34% 3.34% ceph-osd [.] ceph::common::PerfCounters::inc
+ 3.33% 0.07% ceph-osd [.] pthread_mutex_unlock@plt
+ 3.33% 0.15% ceph-osd [.] operator delete@plt
+ 3.02% 2.34% ceph-osd [.] std::_Rb_tree<unsigned long, unsigned long, std::_Identity<unsigned long>, std::less<unsigned long>, std::allocator<unsigned long> >::erase
1.83% 1.41% ceph-osd [.] ProtocolV2::read_event
+ 1.76% 0.14% ceph-osd [.] operator new@plt
1.76% 1.76% libtcmalloc.so.4.5.3 [.] operator new[]
+ 1.64% 1.63% ceph-osd [.] ceph::common::PerfCounters::tinc
1.44% 1.44% ceph-osd [.] ProtocolV2::get_current_msg_size
+ 1.37% 0.09% ceph-osd [.] clock_gettime@plt
+ 1.14% 0.16% ceph-osd [.] CtFun<ProtocolV2>::call
0.84% 0.54% ceph-osd [.] C_time_wakeup::do_request
0.69% 0.33% ceph-osd [.] std::_Rb_tree<unsigned long, unsigned long, std::_Identity<unsigned long>, std::less<unsigned long>, std::allocator<unsigned long> >::_M_er
0.53% 0.00% [unknown] [.] 0x00000000000001d1
0.48% 0.00% [unknown] [.] 0x0000000000000051
0.38% 0.06% ceph-osd [.] ProtocolV2::handle_message
0.30% 0.30% ceph-osd [.] std::_Rb_tree<unsigned long, std::pair<unsigned long const, std::_Rb_tree_iterator<std::pair<std::chrono::time_point<ceph::coarse_mono_cloc
0.24% 0.00% ceph-osd [.] PrimaryLogPG::do_op
0.24% 0.24% libstdc++.so.6.0.25 [.] std::_Rb_tree_increment
0.24% 0.00% ceph-osd [.] PrimaryLogPG::issue_repop
0.21% 0.20% libpthread-2.28.so [.] __lll_lock_wait
0.21% 0.00% [unknown] [.] 0000000000000000
0.21% 0.21% libpthread-2.28.so [.] __pthread_mutex_unlock
0.19% 0.19% [kernel] [k] page_fault
0.17% 0.07% ceph-osd [.] EpollDriver::event_wait
0.15% 0.00% [unknown] [.] 0x0000000000000071
0.14% 0.01% ceph-osd [.] AsyncConnection::read
0.14% 0.02% ceph-osd [.] AsyncConnection::read_until
0.13% 0.01% ceph-osd [.] CtRxNode<ProtocolV2>::call
0.13% 0.07% ceph-osd [.] OpTracker::visit_ops_in_flight
Updated by jianwei zhang 8 months ago
- ceph daemon osd.0 config show | grep message
"osd_client_message_cap": "0",
"osd_client_message_size_cap": "524288000",
- ps aux | grep rados | grep 7201 | wc -l
2000
- cat test-bench-write.sh
for i in {1..2000} ; do
name1=$(echo $RANDOM)
name2=$(echo $RANDOM)
echo "test-bench-write-$name1-$name2"
nohup radosc ./ceph.conf bench 7201 write --no-cleanup -t 1 -p test-pool -b 1048576 --show-time --run-name "test-bench-write$name1-$name2" >> writelog 2>&1 &
done
Updated by Radoslaw Zarzynski 8 months ago
Oops, perhaps (CHECK ME!) we aren't randomizing the retry times nor enlarging them with each failed attemp.
Anyway, this case if a perfect topic for Ceph Perf Weekly meetings. Let's bring it there.
Updated by Radoslaw Zarzynski 8 months ago
Updated by jianwei zhang 8 months ago
2023-09-15 problem analysis:
reproduce:
1. cluster information:
osd_client_message_cap = 2048
osd_client_message_size_cap = 500_M
# ./bin/ceph -s 2>/dev/null
cluster:
id: f07ca5dd-b3ef-4360-a009-75223c04b928
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 17m)
mgr: x(active, since 17m)
osd: 1 osds: 1 up (since 17m), 1 in (since 45h)
flags noout,nobackfill,norebalance,norecover,noscrub,nodeep-scrub
data:
pools: 1 pools, 128 pgs
objects: 14.72M objects, 1.4 TiB
usage: 1.6 TiB used, 7.7 TiB / 9.3 TiB avail
pgs: 128 active+clean
# ./bin/ceph osd tree 2>/dev/null
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 9.27039 root default
-3 9.27039 host zjw-cmain-dev
0 hdd 9.27039 osd.0 up 1.00000 1.00000
[root@zjw-cmain-dev build]# ./bin/ceph osd crush rule dump 2>/dev/null
[
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "choose_firstn",
"num": 0,
"type": "osd"
},
{
"op": "emit"
}
]
}
]
# ./bin/ceph osd pool ls detail 2>/dev/null
pool 1 'test-pool' replicated size 1 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode off last_change 9 flags hashpspool stripe_width 0 application rgw
# ./bin/ceph df 2>/dev/null
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 9.3 TiB 7.7 TiB 1.6 TiB 1.6 TiB 17.27
TOTAL 9.3 TiB 7.7 TiB 1.6 TiB 1.6 TiB 17.27
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
test-pool 1 128 1.4 TiB 14.72M 1.4 TiB 16.52 7.2 TiB
# ./bin/ceph osd dump 2>/dev/null
epoch 88
fsid f07ca5dd-b3ef-4360-a009-75223c04b928
created 2023-09-13T15:29:35.926253+0800
modified 2023-09-15T13:10:28.203204+0800
flags noout,nobackfill,norebalance,norecover,noscrub,nodeep-scrub,sortbitwise,recovery_deletes,purged_snapdirs,pglog_hardlimit
crush_version 16
full_ratio 0.95
backfillfull_ratio 0.9
nearfull_ratio 0.85
require_min_compat_client luminous
min_compat_client jewel
require_osd_release pacific
stretch_mode_enabled false
pool 1 'test-pool' replicated size 1 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode off last_change 9 flags hashpspool stripe_width 0 application rgw
max_osd 1
osd.0 up in weight 1 up_from 85 up_thru 85 down_at 84 last_clean_interval [80,81) v2:127.0.0.1:6800/1561908 v2:127.0.0.1:6801/1561908 exists,up 3d3d685e-3768-4a3f-8890-7dc8874913c4
2. test information:
# cat test-bench-write-6000client-100K.sh
> writelog
for i in {1..6000} ; do
name1=$(echo $RANDOM)
name2=$(echo $RANDOM)
echo "test-bench-write-$name1-$name2"
nohup rados -c ./ceph.conf bench 7201 write --no-cleanup -t 1 -p test-pool -b 102434 --show-time --run-name "test-bench-write-$name1-$name2" >> writelog 2>&1 &
done
3. running test-bench
# sh test-bench-write-6000client-100K.sh
# ps aux |grep rados | grep bench | wc -l
6000
<details><summary> EventCenter::process_events debug code modify </summary>
int EventCenter::process_events(unsigned timeout_microseconds, ceph::timespan *working_dur)
{
auto one_time = ceph::mono_clock::now();
auto base_timeout_us = timeout_microseconds;
bool time_event_is_reached = false;
unsigned wait_time1 = 0;
unsigned wait_time2 = 0;
unsigned wait_time3 = 0;
unsigned wait_time4 = 0;
struct timeval tv;
int numevents;
bool trigger_time = false;
auto now = clock_type::now();
clock_type::time_point end_time = now + std::chrono::microseconds(timeout_microseconds);
clock_type::time_point diff_end_time1 = clock_type::zero();
clock_type::time_point diff_now2 = clock_type::zero();
auto it = time_events.begin();
if (it != time_events.end() && end_time >= it->first) {
trigger_time = true;
end_time = it->first;
if (end_time > now) {
timeout_microseconds = std::chrono::duration_cast<std::chrono::microseconds>(end_time - now).count();
diff_end_time1 = end_time;
diff_now2 = now;
wait_time1 = timeout_microseconds;
} else {
time_event_is_reached = true;
timeout_microseconds = 0;
wait_time2 = timeout_microseconds;
}
}
bool blocking = pollers.empty() && !external_num_events.load();
if (!blocking) {
timeout_microseconds = 0;
wait_time3 = timeout_microseconds;
} else {
wait_time4 = timeout_microseconds;
}
tv.tv_sec = timeout_microseconds / 1000000;
tv.tv_usec = timeout_microseconds % 1000000;
auto is_not_block = !blocking;
auto time_events_sum = time_events.size();
auto two_time = ceph::mono_clock::now();
auto poollers_is_empty = pollers.empty();
auto external_num_events_count = external_num_events.load();
ldout(cct, 30) << __func__ << " wait second " << tv.tv_sec << " usec " << tv.tv_usec << dendl;
std::vector<FiredFileEvent> fired_events;
numevents = driver->event_wait(fired_events, &tv);
auto epoll_numevents = numevents;
auto three_time = ceph::mono_clock::now();
auto working_start = ceph::mono_clock::now();
for (int event_id = 0; event_id < numevents; event_id++) {
int rfired = 0;
FileEvent *event;
EventCallbackRef cb;
event = _get_file_event(fired_events[event_id].fd);
/* note the event->mask & mask & ... code: maybe an already processed
* event removed an element that fired and we still didn't
* processed, so we check if the event is still valid. */
if (event->mask & fired_events[event_id].mask & EVENT_READABLE) {
rfired = 1;
cb = event->read_cb;
cb->do_request(fired_events[event_id].fd);
}
if (event->mask & fired_events[event_id].mask & EVENT_WRITABLE) {
if (!rfired || event->read_cb != event->write_cb) {
cb = event->write_cb;
cb->do_request(fired_events[event_id].fd);
}
}
ldout(cct, 30) << __func__ << " event_wq process is " << fired_events[event_id].fd
<< " mask is " << fired_events[event_id].mask << dendl;
}
auto four_time = ceph::mono_clock::now();
int time_running_numevents = 0;
if (trigger_time) {
time_running_numevents = process_time_events();
numevents += time_running_numevents;
}
auto five_time = ceph::mono_clock::now();
int external_running_numevents = 0;
if (external_num_events.load()) {
external_lock.lock();
std::deque<EventCallbackRef> cur_process;
cur_process.swap(external_events);
external_num_events.store(0);
external_lock.unlock();
external_running_numevents = cur_process.size();
numevents += external_running_numevents;
while (!cur_process.empty()) {
EventCallbackRef e = cur_process.front();
ldout(cct, 30) << __func__ << " do " << e << dendl;
e->do_request(0);
cur_process.pop_front();
}
}
auto six_time = ceph::mono_clock::now();
int pollers_running_numevents = 0;
if (!numevents && !blocking) {
for (uint32_t i = 0; i < pollers.size(); i++)
pollers_running_numevents += pollers[i]->poll();
numevents += pollers_running_numevents;
}
if (working_dur)
*working_dur = ceph::mono_clock::now() - working_start;
auto seven_time = ceph::mono_clock::now();
auto all_latency = seven_time - one_time;
auto latency1 = two_time - one_time;
auto latency2 = three_time - two_time;
auto latency3 = four_time - three_time;
auto latency4 = five_time - four_time;
auto latency5 = six_time - five_time;
auto latency6 = seven_time - six_time;
lderr(cct) << __func__ << " all_latency=" << all_latency
<< " yupan-phase=" << latency1
<< " epoll_wait-phase=" << latency2
<< " epoll_event_consume-phase=" << latency3
<< " time_event_consume-phase=" << latency4
<< " external_event_consume-phase=" << latency5
<< " poller_event_consume-phase=" << latency6
<< " base_timeout_us=" << base_timeout_us
<< " epoll_wait=" << tv.tv_sec << "." << (tv.tv_usec / 1000.0 / 1000.0) << "s"
<< " diff_end_time1=" << diff_end_time1
<< " diff_now2=" << diff_now2
<< " wait_time1=" << wait_time1
<< " wait_time2=" << wait_time2
<< " wait_time3=" << wait_time3
<< " wait_time4=" << wait_time4
<< " poollers_is_empty=" << poollers_is_empty
<< " trigger_time=" << trigger_time
<< " time_event_is_reached=" << time_event_is_reached
<< " is_not_block=" << is_not_block
<< " epoll_numevents=" << epoll_numevents
<< " time_events_sum=" << time_events_sum
<< " time_running_numevents=" << time_running_numevents
<< " external_num_events_count=" << external_num_events_count
<< " external_running_numevents=" << external_running_numevents
<< " pollers_running_numevents=" << pollers_running_numevents
<< " numevents_running_sum=" << numevents
<< dendl;
return numevents;
}
</details>
Updated by jianwei zhang 8 months ago
- After msgr-worker-thread was awakened, 93.34% (1756073 / 1881227) processed 0 events.
- There are a large number of invalid wake-ups in the EventCenter::process_events function.
2023-09-14T15:00:14.487+0800
7f8ce7520700
-1
Event(0x55f7f9bc9040
nevent=20000
time_id=35536575).process_events
all_latency=0.000000696s
yupan-phase=0.000000044s
epoll_wait-phase=0.000000482s
epoll_event_consume-phase=0.000000047s
time_event_consume-phase=0.000000043s
external_event_consume-phase=0.000000029s
poller_event_consume-phase=0.000000051s
base_timeout_us=30000000
diff_end_time1=95376.460342s
diff_now2=95376.460342s
wait_time1=0
wait_time2=0
wait_time3=0
wait_time4=0
poollers_is_empty=1
trigger_time=1
time_event_is_reached=0
is_not_block=0
epoll_numevents=0
time_events_sum=3286
time_running_numevents=0
external_num_events_count=0
external_running_numevents=0
pollers_running_numevents=0
numevents_running_sum=0
# tail -n 2000000 out/osd.0.log | grep numevents_running_sum | wc -l
1881227
# tail -n 2000000 out/osd.0.log | grep -w numevents_running_sum=0 | wc -l
1763556
# tail -n 2000000 out/osd.0.log | grep -w numevents_running_sum=0 | grep -w wait_time1=0 | wc -l
1756073
1763556 / 1881227 = 93.74%
1756073 / 1881227 = 93.34%
Updated by jianwei zhang 8 months ago
- clock accuracy issue
- end_time > now : Nanosecond comparison, but converted to microseconds difference --> timeout_microseconds=0 --> epoll_wait not sleep
int EventCenter::process_events(unsigned timeout_microseconds, ceph::timespan *working_dur)
{
struct timeval tv;
int numevents;
bool trigger_time = false;
auto now = clock_type::now();
clock_type::time_point end_time = now + std::chrono::microseconds(timeout_microseconds);
auto it = time_events.begin();
if (it != time_events.end() && end_time >= it->first) {
trigger_time = true;
end_time = it->first;
if (end_time > now) { // here is Nanosecond comparison, but converted to microseconds difference
timeout_microseconds = std::chrono::duration_cast<std::chrono::microseconds>(end_time - now).count();
diff_end_time1 = end_time; //diff_end_time1=95376.460342s
diff_now2 = now; //diff_now2 =95376.460342s
wait_time1 = timeout_microseconds; //wait_time1 = 0, not epoll_wait sleep
}
... ...
}
... ...
tv.tv_sec = timeout_microseconds / 1000000;
tv.tv_usec = timeout_microseconds % 1000000;
numevents = driver->event_wait(fired_events, &tv);
... ...
}
int EpollDriver::event_wait(std::vector<FiredFileEvent> &fired_events, struct timeval *tvp)
{
int retval, numevents = 0;
retval = epoll_wait(epfd, events, nevent, tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1); //milliseconds
if (retval > 0) {
numevents = retval;
fired_events.resize(numevents);
for (int event_id = 0; event_id < numevents; event_id++) {
int mask = 0;
struct epoll_event *e = &events[event_id];
if (e->events & EPOLLIN) mask |= EVENT_READABLE;
if (e->events & EPOLLOUT) mask |= EVENT_WRITABLE;
if (e->events & EPOLLERR) mask |= EVENT_READABLE|EVENT_WRITABLE;
if (e->events & EPOLLHUP) mask |= EVENT_READABLE|EVENT_WRITABLE;
fired_events[event_id].fd = e->data.fd;
fired_events[event_id].mask = mask;
}
}
return numevents;
}
https://man7.org/linux/man-pages/man2/epoll_wait.2.html
NAME top
epoll_wait, epoll_pwait, epoll_pwait2 - wait for an I/O event on
an epoll file descriptor
LIBRARY top
Standard C library (libc, -lc)
SYNOPSIS top
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout); --> timeout is milliseconds
The timeout argument specifies the number of milliseconds that
epoll_wait() will block. Time is measured against the
CLOCK_MONOTONIC clock.
A call to epoll_wait() will block until either:
• a file descriptor delivers an event;
• the call is interrupted by a signal handler; or
• the timeout expires.
Note that the timeout interval will be rounded up to the system
clock granularity, and kernel scheduling delays mean that the
blocking interval may overrun by a small amount. Specifying a
timeout of -1 causes epoll_wait() to block indefinitely, while
specifying a timeout equal to zero cause epoll_wait() to return
immediately, even if no events are available.
class coarse_mono_clock {
public:
typedef timespan duration;
typedef duration::rep rep;
typedef duration::period period;
typedef std::chrono::time_point<coarse_mono_clock> time_point;
static constexpr const bool is_steady = true;
static time_point now() noexcept {
struct timespec ts;
#if defined(CLOCK_MONOTONIC_COARSE)
// Linux systems have _COARSE clocks.
clock_gettime(CLOCK_MONOTONIC_COARSE, &ts);
#elif defined(CLOCK_MONOTONIC_FAST)
// BSD systems have _FAST clocks.
clock_gettime(CLOCK_MONOTONIC_FAST, &ts);
#else
// And if we find neither, you may wish to consult your system's documentation.
#warning Falling back to CLOCK_MONOTONIC, may be slow.
clock_gettime(CLOCK_MONOTONIC, &ts);
#endif
return time_point(std::chrono::seconds(ts.tv_sec) + std::chrono::nanoseconds(ts.tv_nsec)); //nanoseconds
}
static bool is_zero(const time_point& t) {
return (t == time_point::min());
}
static time_point zero() {
return time_point::min();
}
};
Updated by jianwei zhang 8 months ago
solution:
The core idea is that after the first time_event timeout expires in nanoseconds,
Force alignment to epoll_wait milliseconds, wait at least 1 millisecond
https://github.com/ceph/ceph/pull/53477
please review, thanks!
Updated by jianwei zhang 8 months ago
Avoid meaningless idling of msgr worker thread
Updated by jianwei zhang 8 months ago
- ms_time_events_min_wait_interval=1000us
- osd cpu
* osd cpu : 176
* osd msgr worker : 3 * 35% = 105%
* 6000 个 rados bench
```
top - 14:27:42 up 2 days, 1:57, 0 users, load average: 13.01, 5.62, 7.17
Tasks: 6024 total, 1 running, 6023 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.8 us, 5.0 sy, 0.0 ni, 70.7 id, 16.1 wa, 0.0 hi, 0.3 si, 0.0 st
MiB Mem : 128649.0 total, 4129.7 free, 42223.5 used, 82295.9 buff/cache
MiB Swap: 4096.0 total, 4008.2 free, 87.8 used. 85775.3 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1713908 root 20 0 2103616 1.2g 19412 S 176.0 1.0 2:24.01 ceph-osdPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1713933 root 20 0 2667840 1.7g 19428 S 35.0 1.4 0:41.61 msgr-worker-2
1713931 root 20 0 2667840 1.7g 19428 S 34.0 1.4 0:41.89 msgr-worker-0
1713932 root 20 0 2667840 1.7g 19428 S 34.0 1.4 0:41.16 msgr-worker-1
1714538 root 20 0 2667840 1.7g 19428 D 11.0 1.4 0:12.89 tp_osd_tp
1714537 root 20 0 2667840 1.7g 19428 D 10.0 1.4 0:12.71 tp_osd_tp
1714540 root 20 0 2667840 1.7g 19428 D 10.0 1.4 0:12.46 tp_osd_tp
1714541 root 20 0 2667840 1.7g 19428 D 10.0 1.4 0:12.62 tp_osd_tp
1714539 root 20 0 2667840 1.7g 19428 D 8.0 1.4 0:12.87 tp_osd_tp
1713910 root 20 0 2667840 1.7g 19428 S 7.0 1.4 0:08.89 log
1714035 root 20 0 2667840 1.7g 19428 S 3.0 1.4 0:02.20 bstore_aio
1714508 root 20 0 2667840 1.7g 19428 D 3.0 1.4 0:04.48 bstore_kv_sync
1713943 root 20 0 2667840 1.7g 19428 S 1.0 1.4 0:00.53 OpHistorySvc
1714509 root 20 0 2667840 1.7g 19428 S 1.0 1.4 0:01.54 bstore_kv_final
1713908 root 20 0 2667840 1.7g 19428 S 0.0 1.4 0:08.39 ceph-osd
```
- 0 events running ratio
```
[root@zjw-cmain-dev build]# cat out/osd.0.log | grep numevents_running_sum | wc -l
1201611
[root@zjw-cmain-dev build]# cat out/osd.0.log | grep -w numevents_running_sum=0 | wc -l
58254
58254 / 1201611 = 4.84%
```
Updated by jianwei zhang 8 months ago
before the pr:
6000 rados bench
osd cpu = 300%
osd sing msgr worker = 95%~99%
after the pr:
6000 rados bench
osd cpu = 110~120%
osd sing msgr worker = 30%~40%
Benefit:
reduce 50% cpu
Updated by jianwei zhang 8 months ago
Have an idea,
Bind time_event to throttle,
When waking up the EventCenter::process_events msgr-worker thread,
Determine in advance whether there is an available throttle. If not, the time_event under the throttle will no longer be traversed.
CtPtr ProtocolV2::throttle_message() {
ldout(cct, 20) << __func__ << dendl;
if (connection->policy.throttler_messages) {
ldout(cct, 10) << __func__ << " wants " << 1
<< " message from policy throttler "
<< connection->policy.throttler_messages->get_current()
<< "/" << connection->policy.throttler_messages->get_max()
<< dendl;
if (!connection->policy.throttler_messages->get_or_fail()) {
ldout(cct, 10) << __func__ << " wants 1 message from policy throttle "
<< connection->policy.throttler_messages->get_current()
<< "/" << connection->policy.throttler_messages->get_max()
<< " failed, just wait." << dendl;
// following thread pool deal with th full message queue isn't a
// short time, so we can wait a ms.
if (connection->register_time_events.empty()) {
auto local_ms_throttle_retry_time_interval = connection->get_connection_throttle_retry_interval(cct);
connection->register_time_events.insert(
connection->center->create_time_event(local_ms_throttle_retry_time_interval,
connection->wakeup_handler));
}
return nullptr;
}
}
Updated by Radoslaw Zarzynski 7 months ago
Perfect thing to discuss during Perf Weekly meetings.
Updated by Lee Sanders 13 days ago
Please see my latest update to the PR: https://github.com/ceph/ceph/pull/53477
I can confirm the fix is good and a huge improvement in CPU utilisation on the threads (down to 25% per thread) and ceph-osd is reporting around 88% utilisation.