Bug #59580
openmemory leak (RESTful module, maybe others?)
0%
Description
There are two separate reports on the mailing list of memory leaks in the mgr module:
[ceph-users] Memory leak in MGR after upgrading to pacific
After upgrading from Octopus (15.2.17) to Pacific (16.2.12) two days ago, I'm noticing that the MGR daemons keep failing over to standby and then back every 24hrs. Watching the output of 'ceph orch ps' I can see that the memory consumption of the mgr is steadily growing until it becomes unresponsive. When the mgr becomes unresponsive, tasks such as RESTful calls start to fail, and the standby eventually takes over after ~20 minutes. I've included a log of memory consumption (in 10 minute intervals) at the end of this message. While the cluster recovers during this issue, the loss of usage data during the outage, and the fact its occurring is problematic. Any assistance would be appreciated. Note, this is a cluster that has been upgraded from an original jewel based ceph using filestore, through bluestore conversion, container conversion, and now to Pacific. The data below shows memory use with three mgr modules enabled: cephadm, restful, iostat. By disabling iostat, I can reduce the rate of memory consumption increasing to about 200MB/hr.
[ceph-users] MGR Memory Leak in Restful
We've hit a memory leak in the Manager Restful interface, in versions
17.2.5 & 17.2.6. On our main production cluster the active MGR grew to
about 60G until the oom_reaper killed it, causing a successful failover
and restart of the failed one. We can then see that the problem is
recurring, actually on all 3 of our clusters.
We've traced this to when we enabled full Ceph monitoring by Zabbix last
week. The leak is about 20GB per day, and seems to be proportional to
the number of PGs. For some time we just had the default settings, and
no memory leak, but had not got around to finding why many of the Zabbix
items were showing as Access Denied. We traced this to the MGR's MON
CAPS which were "mon 'profile mgr'".
The MON logs showed recurring:
log_channel(audit) log [DBG] : from='mgr.284576436 192.168.xxx.xxx:0/2356365' entity='mgr.host1' cmd=[{"format": "json", "prefix": "pg dump"}]: access denied
Changing the MGR CAPS to "mon 'allow *'" and restarting the MGR
immediately allowed that to work, and all the follow-on REST calls worked.
log_channel(audit) log [DBG] : from='mgr.283590200 192.168.xxx.xxx:0/1779' entity='mgr.host1' cmd=[{"format": "json", "prefix": "pg dump"}]: dispatch
However it has also caused the memory leak to start.
We've reverted the CAPS and are back to how we were.
Files
{kind=link}
Updated by Simon Fowler 11 months ago
I can confirm both aspects of this on our 17.2.5 cluster, with the RESTful module enabled: with the '[mon] allow profile mgr' caps Zabbix was unable to access many items, with '[mon] allow *' Zabbix access issues were resolved; we're also seeing a memory leak with this configuration, of a similar scale - something on the order of 20GB per day.
We were seeing growth up to ~70-80GB after five to seven days, at which point the RESTful api calls started failing or timing out. The mgr processes weren't being killed or failing over on their own, though (these nodes have 512GB RAM, so they weren't anywhere near an OOM situation), and as far as I can tell nothing else was impacted. Manually failing the active mgr seems to free up the memory without restarting the actual mgr process - we're working around the leak at the moment by failing the active mgr every 24 hours, which is clunky but hasn't been causing any issues for us.
Current versions are:
{
"mon": {
"ceph version 17.2.5 (98318ae89f1a893a6ded3a640405cdbb33e08757) quincy (stable)": 5
},
"mgr": {
"ceph version 17.2.5 (98318ae89f1a893a6ded3a640405cdbb33e08757) quincy (stable)": 4
},
"osd": {
"ceph version 17.2.5 (98318ae89f1a893a6ded3a640405cdbb33e08757) quincy (stable)": 96
},
"mds": {
"ceph version 17.2.5 (98318ae89f1a893a6ded3a640405cdbb33e08757) quincy (stable)": 3
},
"rgw": {
"ceph version 17.2.5 (98318ae89f1a893a6ded3a640405cdbb33e08757) quincy (stable)": 4
},
"overall": {
"ceph version 17.2.5 (98318ae89f1a893a6ded3a640405cdbb33e08757) quincy (stable)": 112
}
}
Manager module list:
balancer on (always on) crash on (always on) devicehealth on (always on) orchestrator on (always on) pg_autoscaler on (always on) progress on (always on) rbd_support on (always on) status on (always on) telemetry on (always on) volumes on (always on) cephadm on dashboard on iostat on restful on alerts - diskprediction_local - influx - insights - k8sevents - localpool - mds_autoscaler - mirroring - nfs - osd_perf_query - osd_support - prometheus - rook - selftest - snap_schedule - stats - telegraf - test_orchestrator - zabbix -
Updated by Radoslaw Zarzynski 9 months ago
Updated by Radoslaw Zarzynski 9 months ago
- Assignee set to Nitzan Mordechai
Hello Nitzan, would you mind taking a look?
Updated by Nitzan Mordechai 9 months ago
The mgr RESTful module is keeping all the finished requests, in some cases (like pg dump with hundreds of pgs) the output of the request that we are keeping can grow and grow without any limits.
i'm still trying to find a reason why we are keeping the finished results, if anyone has any good reason to keep them after some time please let me know.
Updated by Nizamudeen A 9 months ago
I don't know if the RESTful module is still used. Dashboard has its own REST API inside the dashboard module which would probably eliminate the need for another RESTful module. I remember some discussion about deprecating or removing the RESTful module. Not sure if its still in plan to deprecate it.
Updated by Nitzan Mordechai 9 months ago
Nizamudeen A thanks for the input, what about zabbix using that restful api?
Updated by Nitzan Mordechai 9 months ago
The problem is that we are keeping the results of each request, when the result is small, that's fine, but when it comes to pg dumps and other commands that potentially can return a lot of data, the result array can grow and finally cause OOM
def finish(self, tag):
with self.lock:
for index in range(len(self.running)):
if self.running[index].tag == tag:
if self.running[index].r == 0:
self.finished.append(self.running.pop(index))
else:
self.failed.append(self.running.pop(index))
return True
# No such tag found
return False
There is no limit on self.failed or self.finished.
Updated by Nitzan Mordechai 9 months ago
- Assignee changed from Nitzan Mordechai to Juan Miguel Olmo Martínez
Updated by Michal Cila 8 months ago
Hi all,
we are experiencing memory leak in MGR as well. However we have restful module turned off and CAPS are set to allow profile mgr. Strange thing is that at one point memory starts growing on multiple Ceph clusters within one datacenter rapidly.
Version 17.2.6
Updated by Chris Palmer 7 months ago
Any chance of progressing this?
Regardless of whether there is actually any reason for keeping the results (??), continually adding to a memory structure without bounds is not a great idea!
Thanks, Chris
Updated by David Orman 7 months ago
We're seeing this anywhere from 1-3 times a day to once a week on all clusters running .13 and .14. We externally poll the metrics endpoint frequently, in case it's related. We see this on clusters we do not utilize the RESTFul module with.
Updated by Rok Jaklic 7 months ago
Greg Farnum wrote:
There are two separate reports on the mailing list of memory leaks in the mgr module:
[ceph-users] Memory leak in MGR after upgrading to pacific
[...][ceph-users] MGR Memory Leak in Restful
[...]
It happend us three times in last month.
Likely it changed something in between 16.2.10-16.2.13 ... that causes this to happen. We have two reports that after update from .10 to .13 ceph mgr got oom killed several times.
[root@ctplmon1 bin]# ceph mgr services
{
"prometheus": "http://xxx:9119/"
}
{
"always_on_modules": [
"balancer",
"crash",
"devicehealth",
"orchestrator",
"pg_autoscaler",
"progress",
"rbd_support",
"status",
"telemetry",
"volumes"
],
"enabled_modules": [
"iostat",
"prometheus",
"restful"
] ...
}
Updated by Nitzan Mordechai 7 months ago
David Orman wrote:
We're seeing this anywhere from 1-3 times a day to once a week on all clusters running .13 and .14. We externally poll the metrics endpoint frequently, in case it's related. We see this on clusters we do not utilize the RESTFul module with.
That sounds like a different issue if the restful module was not utilized on those mgrs, can you run the mgr with massif profiling and send us the output?
Updated by Nitzan Mordechai 7 months ago
- File 0001-mgr-restful-trim-reslts-finished-and-failed-lists-to.patch 0001-mgr-restful-trim-reslts-finished-and-failed-lists-to.patch added
@Simon - Fowler\ @Rok Jaklic \ @Chris Palmer I'm attaching patch, can you please verify it?
Updated by Chris Palmer 7 months ago
I tried applying this patch to 17.2.6. After applying the CAPS change and restarting the active MGR these type of entries were logged in the MGR log:
2023-09-21T14:21:21.272+0100 7f22f3fba700 0 [restful ERROR root] Traceback (most recent call last):
File "/lib/python3/dist-packages/pecan/core.py", line 683, in __call__
self.invoke_controller(controller, args, kwargs, state)
File "/lib/python3/dist-packages/pecan/core.py", line 574, in invoke_controller
result = controller(*args, **kwargs)
File "/usr/share/ceph/mgr/restful/decorators.py", line 37, in decorated
return f(*args, **kwargs)
File "/usr/share/ceph/mgr/restful/api/request.py", line 88, in post
return context.instance.submit_request([[request.json]], **kwargs)
File "/usr/share/ceph/mgr/restful/module.py", line 605, in submit_request
request = CommandsRequest(_request)
File "/usr/share/ceph/mgr/restful/module.py", line 62, in __init__
max_finished = cast(int, self.get_localized_module_option('max_finished', 100))
AttributeError: 'CommandsRequest' object has no attribute 'get_localized_module_option'
2023-09-21T14:21:21.280+0100 7f22f3fba700 0 [restful ERROR werkzeug] Error on request:
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/werkzeug/serving.py", line 323, in run_wsgi
execute(self.server.app)
File "/usr/lib/python3/dist-packages/werkzeug/serving.py", line 312, in execute
application_iter = app(environ, start_response)
File "/usr/lib/python3/dist-packages/pecan/middleware/recursive.py", line 56, in __call__
return self.application(environ, start_response)
File "/usr/lib/python3/dist-packages/pecan/core.py", line 840, in __call__
return super(Pecan, self).__call__(environ, start_response)
File "/usr/lib/python3/dist-packages/pecan/core.py", line 683, in __call__
self.invoke_controller(controller, args, kwargs, state)
File "/usr/lib/python3/dist-packages/pecan/core.py", line 574, in invoke_controller
result = controller(*args, **kwargs)
File "/usr/share/ceph/mgr/restful/decorators.py", line 37, in decorated
return f(*args, **kwargs)
File "/usr/share/ceph/mgr/restful/api/request.py", line 88, in post
return context.instance.submit_request([[request.json]], **kwargs)
File "/usr/share/ceph/mgr/restful/module.py", line 605, in submit_request
request = CommandsRequest(_request)
File "/usr/share/ceph/mgr/restful/module.py", line 62, in __init__
max_finished = cast(int, self.get_localized_module_option('max_finished', 100))
AttributeError: 'CommandsRequest' object has no attribute 'get_localized_module_option'
2023-09-21T14:25:24.095+0100 7f22f3fba700 0 [restful ERROR root] Traceback (most recent call last):
File "/lib/python3/dist-packages/pecan/core.py", line 683, in __call__
self.invoke_controller(controller, args, kwargs, state)
File "/lib/python3/dist-packages/pecan/core.py", line 574, in invoke_controller
result = controller(*args, **kwargs)
File "/usr/share/ceph/mgr/restful/decorators.py", line 37, in decorated
return f(*args, **kwargs)
File "/usr/share/ceph/mgr/restful/api/request.py", line 88, in post
return context.instance.submit_request([[request.json]], **kwargs)
File "/usr/share/ceph/mgr/restful/module.py", line 605, in submit_request
return request
File "/usr/share/ceph/mgr/restful/module.py", line 62, in __init__
self.lock = threading.RLock()
AttributeError: 'CommandsRequest' object has no attribute 'get_localized_module_option'
Updated by Nitzan Mordechai 7 months ago
- File 0001-mgr-restful-trim-reslts-finished-and-failed-lists-to.patch 0001-mgr-restful-trim-reslts-finished-and-failed-lists-to.patch added
@Chris Palmer, i needed to redo the fix, now it should trim the requests and not let them exceed 5,000 requests. please give it a try.
Updated by Chris Palmer 7 months ago
Thanks for continuing to look at this. Has this patch been tested against Quincy (17.2.6)? It still has a reference to get_localized_module_option which will probably cause the same errors as above...
Updated by Nitzan Mordechai 7 months ago
Chris Palmer wrote:
Thanks for continuing to look at this. Has this patch been tested against Quincy (17.2.6)? It still has a reference to get_localized_module_option which will probably cause the same errors as above...
yes, it still has get_localized_module_option, but now it's not under the server, it's under the init of the module itself.
Updated by Chris Palmer 7 months ago
Doesn't look very promising I'm afraid. I just tried the patch on a small 17.2.6 cluster with 745 pgs and zabbix monitoring enabled and "mon 'allow *'" in the active manager caps. As before the monitoring worked. However the mgr rss started at 393M and 12 hours later was at 2.2G and growing, so around 4GB per 24 hours. This is consistent with the original report where a cluster with about 5 times the number of pgs leaked around 20GB per 24 hours.
Updated by Chris Palmer 7 months ago
I just had a 17.2.6 MGR on another cluster go OOM. It was on a bigger cluster, with Zabbix integration, but without the 'allow *' CAPS so most of the calls were getting denied. This MGR had been the active one for some months. It all suggests a leak in the REST interface but it is probably not restricted to the pgs dump function.
Updated by Nitzan Mordechai 7 months ago
Chris Palmer wrote:
I just had a 17.2.6 MGR on another cluster go OOM. It was on a bigger cluster, with Zabbix integration, but without the 'allow *' CAPS so most of the calls were getting denied. This MGR had been the active one for some months. It all suggests a leak in the REST interface but it is probably not restricted to the pgs dump function.
Chris, i'm running tests on my environment and I can see the leaks from the restful module without the patch, with the patch the memory doesn't increass.
i'm starting to wonder if we have also Zabbix module memory leak, can you try the patch after you disabled Zabbix module?
Updated by Chris Palmer 7 months ago
Ah, slight confusion. We are not using the Ceph Zabbix module. That module runs inside the manager and pushes data to Zabbix, but is not very comprehensive. Instead we use a more recent Zabbix template that runs inside a Zabbix agent on another host, and simply polls the active Ceph MGR using the Rest API. So it is entirely consistent that the leak is in the Rest API itself. Zabbix is simply calling it more often that it might normally be. When I enable that additional CAP it performs a lot more calls which turns a small problem into a larger one.
I suspect that your patch fixes a secondary memory buildup, but that the primary leak hasn't been found yet.
Updated by Nitzan Mordechai 6 months ago
Chris Palmer wrote:
Ah, slight confusion. We are not using the Ceph Zabbix module. That module runs inside the manager and pushes data to Zabbix, but is not very comprehensive. Instead we use a more recent Zabbix template that runs inside a Zabbix agent on another host, and simply polls the active Ceph MGR using the Rest API. So it is entirely consistent that the leak is in the Rest API itself. Zabbix is simply calling it more often that it might normally be. When I enable that additional CAP it performs a lot more calls which turns a small problem into a larger one.
I suspect that your patch fixes a secondary memory buildup, but that the primary leak hasn't been found yet.
Chris, i had some attempts to recreate the issue, with the patch, but i still couldn't get it to increase quickly as you are seeing.
can you run the mgr with valgrind massif and provide us the output?
Updated by Chris Palmer 6 months ago
I'll give it a go. I have never used massif before though. Do you have any instructions for how to run the mgr up under it, including any command line options I should use? (It is running non-containerized under debian11).
Updated by Nitzan Mordechai 6 months ago
I'm using:
valgrind --tool=massif bin/ceph-mgr -f --cluster ceph -i x &
valgrind massif is pretty basic, non argument is needed.
Updated by Chris Palmer 6 months ago
- File massif.out.3376365.gz massif.out.3376365.gz added
I ran an active manager under massif for a few minutes, forcing repeated zabbix polling. The memory usage of the mgr could be seen increasing as I was doing this. The massif output is attached. There was little else happening on the cluster at the time, in particular no other mgr activity. Let me know if that is sufficient...
Updated by Nitzan Mordechai 6 months ago
I'm examining your massif file and trying to come with a fix. i still was not able to cause the memory to leak quick enough. any chance you are using mgr_ttl_cache_expire_seconds ?
Updated by Chris Palmer 6 months ago
Thanks. There are no mgr-related tuning parameters set, and specifically mgr_ttl_cache_expire_seconds has not been set. Let me know if I can do anything else.
Updated by Adrien Georget 5 months ago
Any news about this issue?
We have 2 clusters (16.2.14) heavily affected by this memory leak.
Is there a way to limit memory usage for MGR?
Same thing happened with the restful module disabled
"enabled_modules": [
"cephadm",
"dashboard",
"iostat",
"nfs",
"prometheus"
]
Updated by Nitzan Mordechai 5 months ago
Adrien Georget wrote:
Any news about this issue?
We have 2 clusters (16.2.14) heavily affected by this memory leak.
Is there a way to limit memory usage for MGR?Same thing happened with the restful module disabled
[...]
I'm still working on that issue, i couldn't make the mgr to leak memory with the above rates.
can you also send massif output with disabled restful module in mgr?
Updated by Andrea Bolzonella 5 months ago
Adrien Georget wrote:
Is there a way to limit memory usage for MGR?
As a temporary solution, I have limited the memory usage in the systemd unit. The MGR will be killed before it wastes all the memory and compromises the entire node.
Updated by Nitzan Mordechai 5 months ago
Adrien, can you please add a massif output file from the mgr (one without restful enable) that leaking memory?
Updated by Zakhar Kirpichenko 5 months ago
Our 16.2.14 cluster is affected as well. Modules enabled:
"always_on_modules": [
"balancer",
"crash",
"devicehealth",
"orchestrator",
"pg_autoscaler",
"progress",
"rbd_support",
"status",
"telemetry",
"volumes"
],
"enabled_modules": [
"cephadm",
"dashboard",
"iostat",
"prometheus",
"restful"
],No special mgr settings, all defaults.
Updated by Nitzan Mordechai 5 months ago
- Status changed from In Progress to Fix Under Review
- Assignee changed from Juan Miguel Olmo Martínez to Nitzan Mordechai
- Pull request ID set to 54634
Updated by Konstantin Shalygin 5 months ago
- Target version set to v19.0.0
- Source set to Community (user)
- Backport set to pacific Quincy reef
- Affected Versions v16.2.14, v17.2.7, v18.2.1 added
Updated by Andrea Bolzonella 5 months ago
Hello folks
After upgrading to version 16.2.13, we encountered MGR OOM issues. It's worth noting that the restful module was not enabled at the time.
The MGR would experience OOM issues about once a week. The memory usage would start increasing without any apparent reason and in less than an hour, it would take up all 300GiB.
However, when we upgraded to Quincy, the issue disappeared.
Updated by A. Saber Shenouda 5 months ago
Hi Team,
We are affected as well. Since we upgraded to 16.2.14 on two diff cluster 'ceph-mgr' oom and gets killed. It's random. Happens 3 to 5 times per month. Did not have this issue on 16.2.11.
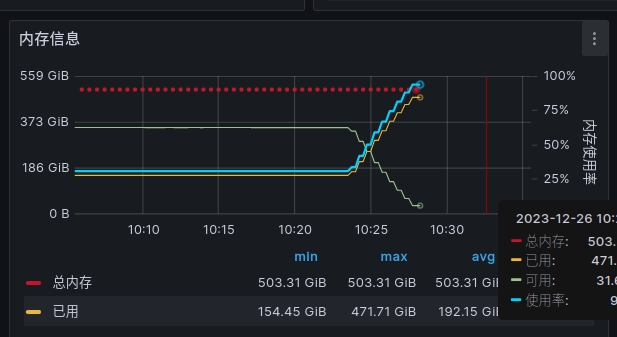
Updated by xiaobao wen 4 months ago
- File 20231227-150450.jpg 20231227-150450.jpg added
- File mgr_rgw_log.tar.gz mgr_rgw_log.tar.gz added
Hello.
We suspect we have encountered similar problems.
About 370GB of memory was consumed in five minutes. Oom is not triggered and the server is finally restarted to solve the problem.
After checking the logs, mgr stopped printing logs when the memory decrease started(2023-12-26T02:23). rgw stopped printing logs when memory is exhausted(2023-12-26T02:28).The osd is limited to 16GB of memory.So it is more suspected that mgr has a memory leak.
[root@bd-hdd03-node01 deeproute]# ceph version
ceph version 16.2.13 (5378749ba6be3a0868b51803968ee9cde4833a3e) pacific (stable)
[root@bd-hdd03-node01 deeproute]# ceph mgr module ls
{
"always_on_modules": [
"balancer",
"crash",
"devicehealth",
"orchestrator",
"pg_autoscaler",
"progress",
"rbd_support",
"status",
"telemetry",
"volumes"
],
"enabled_modules": [
"iostat",
"nfs",
"prometheus",
"restful"
],
Updated by Konstantin Shalygin 3 months ago
- Status changed from Fix Under Review to Pending Backport
- Backport changed from pacific Quincy reef to pacific quincy reef
Updated by Backport Bot 3 months ago
- Copied to Backport #63977: reef: memory leak (RESTful module, maybe others?) added
Updated by Backport Bot 3 months ago
- Copied to Backport #63978: pacific: memory leak (RESTful module, maybe others?) added
Updated by Backport Bot 3 months ago
- Copied to Backport #63979: quincy: memory leak (RESTful module, maybe others?) added
Updated by A. Saber Shenouda 4 days ago
Hi,
It seems that the ceph-mgr oom issue happened again on 16.2.15. We had ceph-mgr "oom" this morning.
I have attached the logs.
Updated by Nitzan Mordechai 4 days ago
waitting for https://github.com/ceph/ceph/pull/54984 merge and backport