Support #58499
openRBD-MIrror not getting performance mirring speed issue
0%
Description
Hello Team,
Please help me i deploy two ceph cluster with 6 node configuration almost 800tb of capacity. and configurae in the DC-DR configuration for the data high availability. i eanbel the rwg and rbd block device mirroring for the replocatio of the data. we have the 10 GBPS fiber replication network .
when we first start rbd mirror from our dc to dr starting time when we are replication our exsisting data that time we are getting almomst 8 GBPS replication speed and it's work fine. once all the exesting images data replicated now we are facing the replication speed issue . now only we are getting the 5 to 10 mbps relication speed. we also try to find the option like rbd_journal_max_payload_bytes and rbd_mirror_journal_max_fetch_bytes but max payload size we try to increase but we don't get any result regarding the speed. it still same . and rbd_mirror_journal_max_fetch_bytes option we are not able to find on the our ceph version. i also try to modify some other values and increase like
rbd_mirror_memory_target
rbd_mirror_memory_cache_min
you also can find some refrence regarding this values for increase performace.
Eugen
[1]
https://tracker.ceph.com/projects/ceph/repository/revisions/1ef12ea0d29f955…
[2]
https://github.com/ceph/ceph/pull/27670
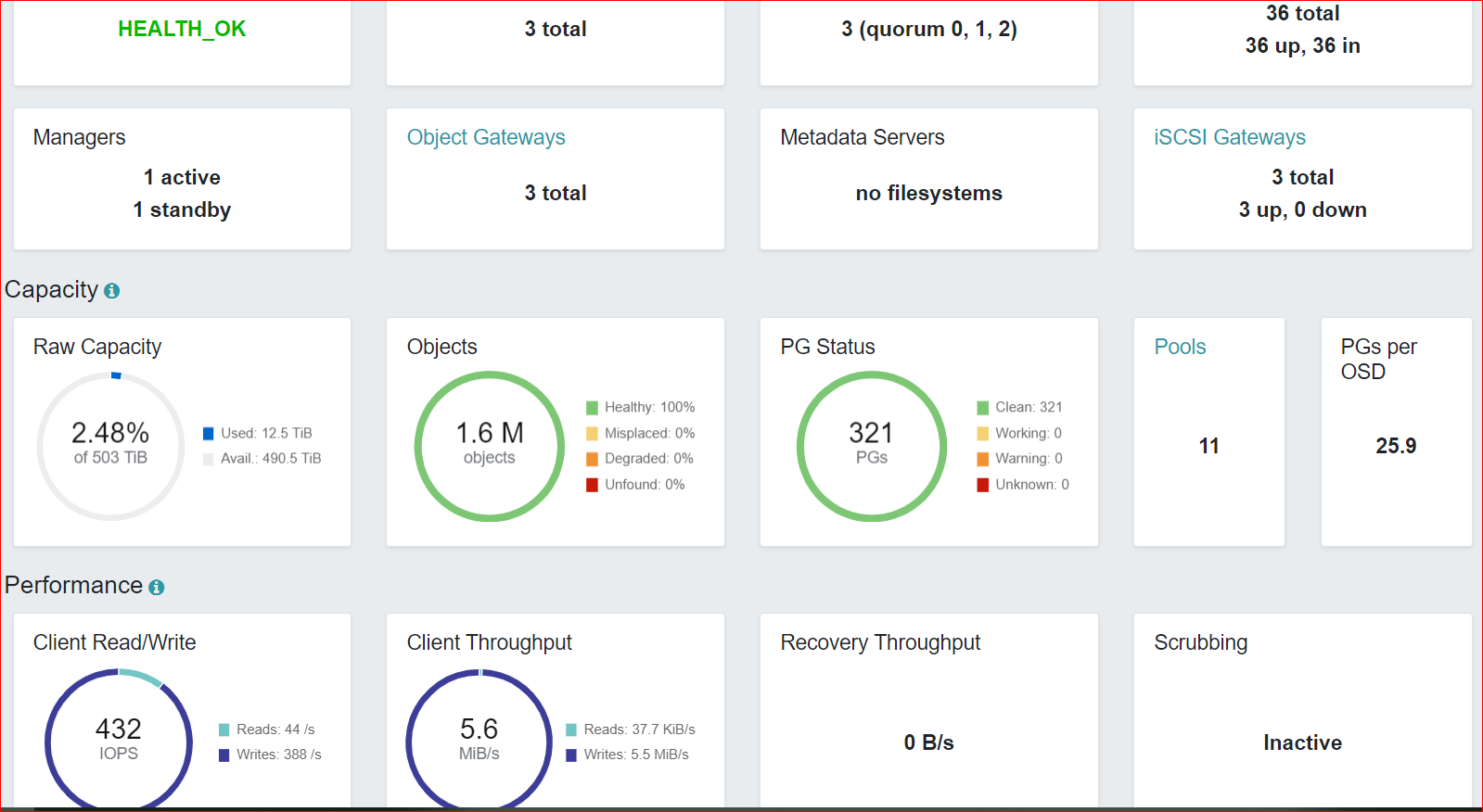
Information of my ceph Cluster.
Version: ceph version 17.2.5 (98318ae89f1a893a6ded3a640405cdbb33e08757) quincy (stable)
rbd-mirror daemon version: 17.2.5
Mirror mode; pool
max image mirro at time: 5
replication network: 10 gbps (dedicated)
Client: DC cluster we are continue writing the 50 to 400 mbps data but
replication only 5 to 10 mbps.
issue: speed only we get the 4 to 5 mbps. also we have the 10 Gbps replication network
bandwidth.
Note::- I also try to find the option rbd_mirror_journal_max_fetch_bytes but i'm not
able to find the this option in the configuration. also when i try to set from the
command
line it's showing error like
command:
ceph config set client.rbd rbd_mirror_journal_max_fetch_bytes 33554432
error:
Error EINVAL: unrecognized config option 'rbd_mirror_journal_max_fetch_bytes'
Files
{kind=link}
{kind=link}
Updated by ankit raiwkar 11 months ago
Hello Team,
Please provide any solution for that issue we are stuck with 200TIB data at the dc and 136TIB data only at dr site. now we are in the middle of the situation , kindly suggest any solution .
Updated by Ilya Dryomov 11 months ago
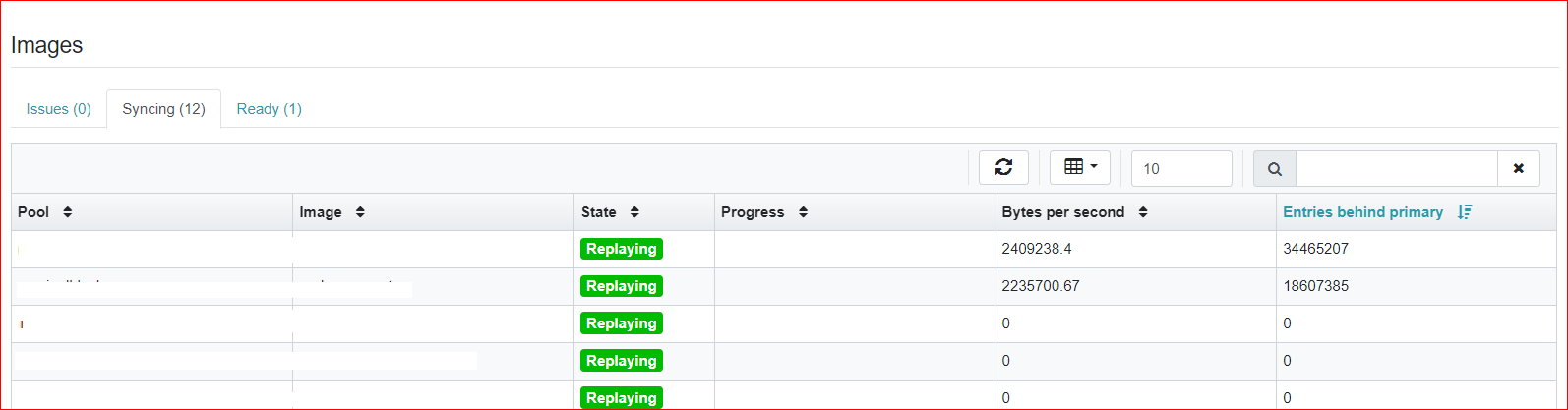
rbd_mirror_journal_max_fetch_bytes option was removed in the changeset that you linked above -- https://github.com/ceph/ceph/pull/27670. I see the two images that are millions of journal entries behind though. Perhaps Mykola has a suggestion?
Updated by Ilya Dryomov 11 months ago
- Has duplicate Bug #58500: RBD-MIrror not getting performance mirring speed issue added
Updated by Ilya Dryomov 11 months ago
Ilya Dryomov wrote:
rbd_mirror_journal_max_fetch_bytes option was removed in the changeset that you linked above -- https://github.com/ceph/ceph/pull/27670.
It's still mentioned in one place in the documentation, by accident. I'm cleaning that up in https://github.com/ceph/ceph/pull/51964.
Updated by Mykola Golub 10 months ago
Ilya Dryomov wrote:
Perhaps Mykola has a suggestion?
Not much. I assume here that replaying is just slow and can't catch with primary image updates? I.e. it is not a situation when it gets stuck for some images (in this case I suppose you should observe images with large "entries behind primary" and 0 "bytes per second" on dashboard mirror page. Still it might be useful to attach `rbd mirror pool $pool --verbose` output collected on both sites, as it contains more detailed information.
If it is just slow, then max_fetch_bytes is indeed the first suspect. Previously it was configurable but with small default, and increasing it speeded up replaying. Now it is calculated based on available cache (controlled by rbd_mirror_memory_target) and the number of images to replay. It would be good to check what value you have. The only way I know is to set `debug_journaler=10` for a couple of minutes and then look for entries like this in the rbd-mirror logs:
2023-06-12T13:30:17.724+0100 7fb0cb341840 10 JournalPlayer: 0x5592c934bb80 handle_cache_rebalanced: new_cache_bytes=134217728, max_fetch_bytes=33554432If you see the number more than 16Mb (preferable 32M) then you are ok. If not, then try to increase rbd_mirror_memory_target.
If the max_fetch value is large and it is still slow, then I would look in the log how much time it spends on fetching an object and processing it, i.e. looking at lines like these:
2023-06-12T13:29:23.729+0100 7fb0c42db6c0 10 ObjectPlayer: 0x5592ceee61c0 fetch: journal_data.4.114c69f46ce5.2
2023-06-12T13:29:23.729+0100 7fb0ba2c76c0 10 ObjectPlayer: 0x5592ceee61c0 handle_fetch_complete: journal_data.4.114c69f46ce5.2, r=0, len=0
and calculating time difference between "fetch" and "handle_fetch_complete" for a particular object. (In this example the object was journal_data.4.114c69f46ce5.2 and the time difference is 0, but in your case I expect it will not be 0). If you have problems to interpret the log just attach it here. Then I suggest increase the debug_journaler to 30 to have all debug messages.
The trickiest part thought will be to enable debug and set log_to_file config variables in a conterized environment. It is easy for osd daemons, as the mgr updates them on on the fly when sees changes in `ceph config set osd ...`. But for rbd mirror I think it will not work. The only way I can think of is to use the rbd mirror admin socket. I.e. on the secondary site (where replaying rbd-mirrors are running), enter the rbd-mirror container:
cephadm enter --name rbd-mirror.XYZlist all admin sockets:
ls /var/run/ceph/client.mirror.*.asokand for every socket run:
ceph daemon /var/run/ceph/client.mirror.XYZ.asok config set log_to_file true
ceph daemon /var/run/ceph/client.mirror.XYZ.asok config set debug_journaler 30To disable (after running for several minutes):
ceph daemon /var/run/ceph/client.mirror.XYZ.asok config set debug_journaler 1/5
ceph daemon /var/run/ceph/client.mirror.XYZ.asok config set log_to_file falseYou should find the logs on the host in /var/log/ceph/{fsid} directory with client.mirror.*log names. Look for logs with large size and that have JournalPlayer and ObjectPlayer entries.
Note currently I don't have a cephadm based environment with rbd-mirror deployed where I could check my instructions, so there might be a mistake above, still hope it will work for you or you will be able to figure out how to adjust it for your environment.
May be Ilya will suggest an easier way to turn on/off debug.
Updated by ankit raiwkar 10 months ago
Hello Mykola Golub,
Thanks for your responce , we have also try to change the value of the rbd_mirror_memory_target , but we don't see any impact on our mirroring b/w clusters . But one thing we notice when we are using the snapshot based mirroing we are geeting proper speed in the mirroring . we are faceing only issue in the journal based rbd-mirroring. if you or community have ayn other input that may help full to us.