Bug #58120
openwatcher remains after "rados watch" is interrupted
0%
Description
when client is down, rbd image still has watchers. I take the down client into osd blacklist ,but still has watchers. its doesn't work。I tried to restart the cluster, the watcher is disappear。
At present, this problem can only be deleted manually?
I found that the client was not implemented the HandleWatchTimeout. cause still has watcher. Is there a solution to this problem at present?
void Watch::register_cb()
{
cb = new HandleWatchTimeout(self.lock());
if (!osd->watch_timer.add_event_after(timeout, cb)) {
cb = nullptr;
}
}
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Updated by Ilya Dryomov over 1 year ago
- Status changed from New to Need More Info
Hi Wang,
When the client is taken down gracefully, it closes its watch(es). When the client is shut down ungracefully (killed or if it crashes), its watch(es) are timed out on the OSD site after 30 seconds.
If you see a watch that persists, one possibility is that there is a client running somewhere that you are not aware of (stray container/VM, etc). The other possibility is an OSD bug, but if you are indeed running v15.2.3 then we are unlikely to able to help since v15 (Octopus) is EOL. If upgrading to v16 (Pacific) or v17 (Quincy) is challenging, I'd recommend upgrading to at least v15.2.17 to get all fixes and improvements backported to Octopus before it went EOL.
Updated by 王子敬 wang over 1 year ago
- File image-2022-11-19-19-18-24-093.png image-2022-11-19-19-18-24-093.png added
- File image-2022-11-19-12-50-18-397.png image-2022-11-19-12-50-18-397.png added
- File image-2022-11-19-15-29-32-590.png image-2022-11-19-15-29-32-590.png added
- File image-2022-11-19-19-22-27-148.png image-2022-11-19-19-22-27-148.png added
Ilya Dryomov wrote:
Hi Wang,
When the client is taken down gracefully, it closes its watch(es). When the client is shut down ungracefully (killed or if it crashes), its watch(es) are timed out on the OSD site after 30 seconds.
If you see a watch that persists, one possibility is that there is a client running somewhere that you are not aware of (stray container/VM, etc). The other possibility is an OSD bug, but if you are indeed running v15.2.3 then we are unlikely to able to help since v15 (Octopus) is EOL. If upgrading to v16 (Pacific) or v17 (Quincy) is challenging, I'd recommend upgrading to at least v15.2.17 to get all fixes and improvements backported to Octopus before it went EOL.
Okay Thank you.
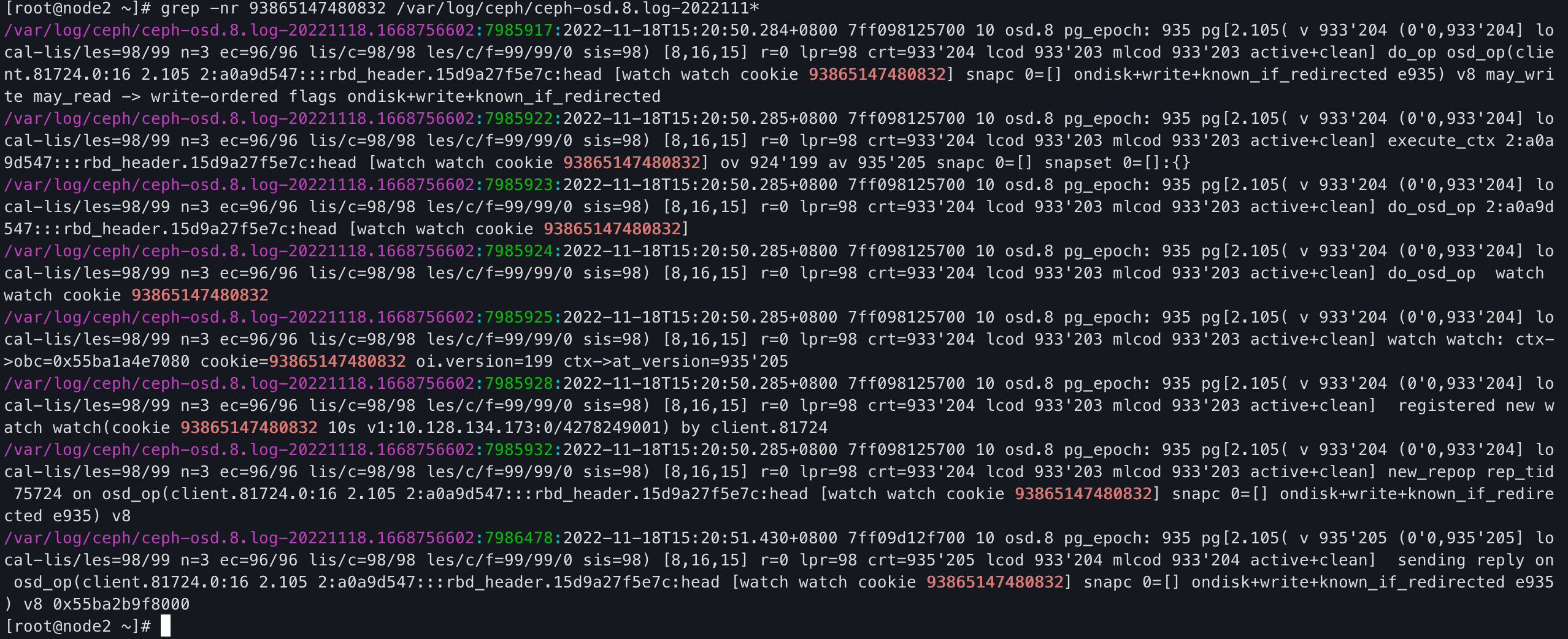
What I see from the analysis log is as follows, in the picture 32-590, not has watch->connect function log output.prove that the process has not yet reached the timeout function registration, and it is killed.
The process of rbd opening is interrupted, and the client end is killed. The registration of timeout processing callback function cannot be completed, resulting in the residue of the watcher.
Updated by Ilya Dryomov over 1 year ago
What I see from the analysis log is as follows, in the picture 32-590, not has watch->connect function log output.prove that the process has not yet reached the timeout function registration, and it is killed.
What is killed, the OSD or the client?
The process of rbd opening is interrupted, and the client end is killed. The registration of timeout processing callback function cannot be completed, resulting in the residue of the watcher.
If the client gets killed it's irrelevant because the watch is registered and later potentially timed out on the OSD side, not on the client side. The code that is highlighted in the pictures is executed on the OSD side.
Updated by 王子敬 wang over 1 year ago
Ilya Dryomov wrote:
What I see from the analysis log is as follows, in the picture 32-590, not has watch->connect function log output.prove that the process has not yet reached the timeout function registration, and it is killed.
What is killed, the OSD or the client?
The process of rbd opening is interrupted, and the client end is killed. The registration of timeout processing callback function cannot be completed, resulting in the residue of the watcher.
If the client gets killed it's irrelevant because the watch is registered and later potentially timed out on the OSD side, not on the client side. The code that is highlighted in the pictures is executed on the OSD side.
The client was killed. The current situation is that the timeout mechanism does not clean up the remaining watchers. The watcher remains and can only be removed manually.
Updated by Ilya Dryomov over 1 year ago
The client was killed.
What was the client that got killed -- a QEMU VM, "rbd map" mapping, etc? How was it killed?
The current situation is that the timeout mechanism does not clean up the remaining watchers. The watcher remains and can only be removed manually.
Is this reproducible? If so, can you provide detailed steps?
Updated by 王子敬 wang over 1 year ago
- File kill_9_rep.py kill_9_rep.py added
Ilya Dryomov wrote:
The client was killed.
What was the client that got killed -- a QEMU VM, "rbd map" mapping, etc? How was it killed?
The current situation is that the timeout mechanism does not clean up the remaining watchers. The watcher remains and can only be removed manually.
Is this reproducible? If so, can you provide detailed steps?
This is a script for making client exceptions. The script will repeatedly kill, the tfs-rep is the client.
Updated by 王子敬 wang over 1 year ago
王子敬 wang wrote:
Ilya Dryomov wrote:
The client was killed.
What was the client that got killed -- a QEMU VM, "rbd map" mapping, etc? How was it killed?
The current situation is that the timeout mechanism does not clean up the remaining watchers. The watcher remains and can only be removed manually.
Is this reproducible? If so, can you provide detailed steps?
This is a script for making client exceptions. The script will repeatedly kill, the tfs-rep is the client.
in my submission that no sleeping for a few seconds between two kills. Problems caused.Is that so?
Updated by Ilya Dryomov over 1 year ago
I'm confused. What is tfs-rep? Can you describe what this process does and how that relates to RBD?
Because the rest of the script is talking about MDS daemons: it's ssh'ing to MDS nodes, the variable is named "cmd_kill_9_mds", it's examining MDS ranks, etc. MDS daemons have nothing to do with RBD.
Updated by 王子敬 wang over 1 year ago
Ilya Dryomov wrote:
I'm confused. What is tfs-rep? Can you describe what this process does and how that relates to RBD?
Because the rest of the script is talking about MDS daemons: it's ssh'ing to MDS nodes, the variable is named "cmd_kill_9_mds", it's examining MDS ranks, etc. MDS daemons have nothing to do with RBD.
It is a service written by me. As a client, it will write data to the RBD, and obtain data from the file and write it to the RBD
Updated by Ilya Dryomov over 1 year ago
How does it write data to RBD? Does it use librbd API?
Updated by 王子敬 wang over 1 year ago
Ilya Dryomov wrote:
How does it write data to RBD? Does it use librbd API?
yes
"pkill -9 tfs-rep; systemctl reset-failed tfs-rep@{}; systemctl start tfs-rep.target"'
tfs-rep is a client,Write these commands into the loop and repeatedly kill the client. I think it is possible that the client does not have a timeout mechanism registered.
Updated by Ilya Dryomov over 1 year ago
Does tfs-rep use librbd C API, librbd C++ API or librbd python bindings to interact with an RBD image?
Updated by Brad Hubbard about 1 year ago
- Status changed from Need More Info to Fix Under Review
- Pull request ID set to 50461
Updated by Ilya Dryomov about 1 year ago
- Project changed from rbd to Ceph
- Subject changed from rbd image still has watchers to watcher remains after "rados watch" is interrupted
- Category set to OSD
- Backport set to pacific,quincy
Updated by Ilya Dryomov about 1 year ago
- Backport changed from pacific,quincy to pacific,quincy,reef
- Pull request ID changed from 50461 to 50861