Bug #58022
openFragmentation score rising by seemingly stuck thread
0%
Description
Due to issue https://tracker.ceph.com/issues/57672 we've been monitoring our clusters closely ensure it doesn't run into the same issue on our other clusters. We have a cluster running 16.2.9 that is showing a weird/bad behavior.
We've noticed some osd's suddenly start increasing their fragmentation at a constant rate until they are restarted. They then settle down and reduce their fragmentation very slowly.
Talking with @Vikhyat Umrao a bit, the theory was maybe compaction was kicking in repeatedly. We used the ceph_rocksdb_log_parser.py on one of the runaway osds and didn't see a significant number of compaction events during the time of its runaway fragmentation. So that is unlikely to be the cause.
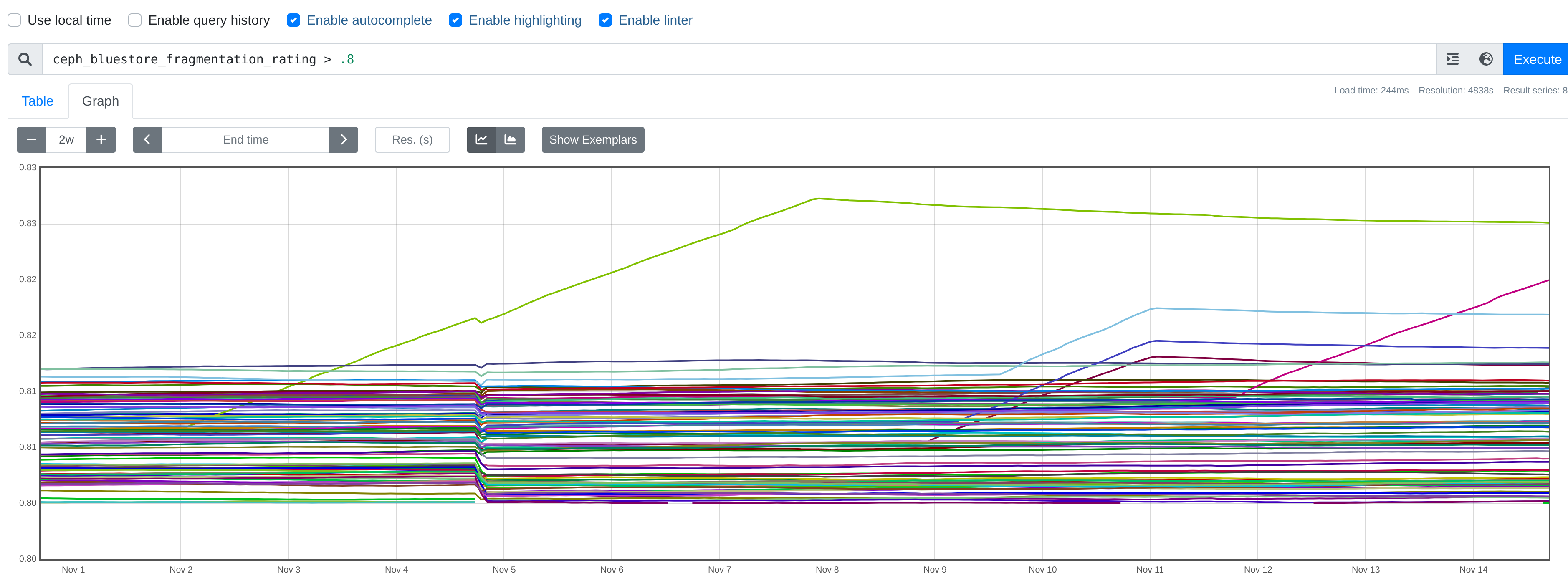
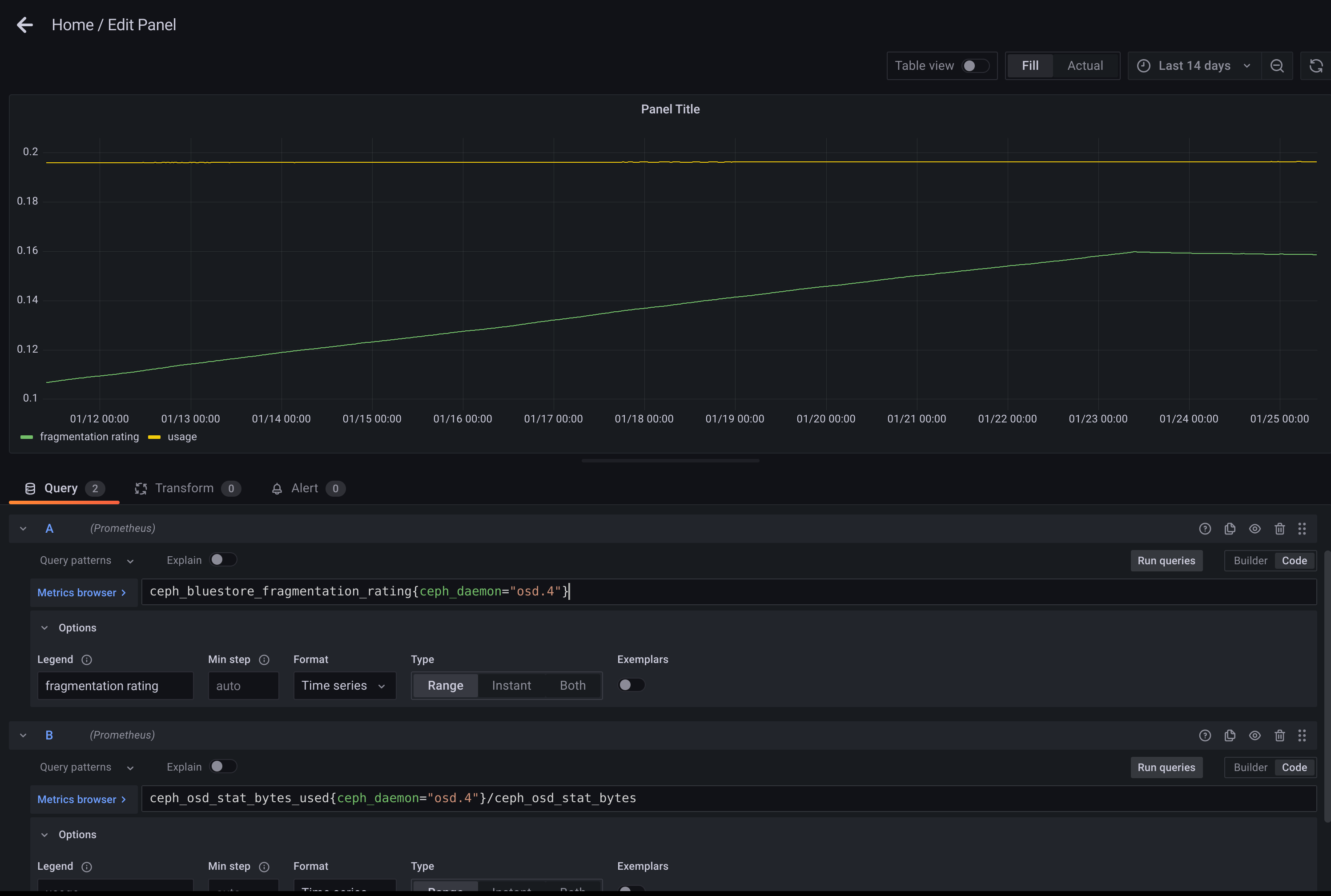
Please see attached screenshot. You can see the run away osds do so over multiple days and then when we restart them, they level off and slowly decrease.
If it was workload related, we would expect it to continue to fragment after the restart as the workload continues on. But the behavior stops immediately on restart. So feels like some thread in the osd is doing something unusual until restarted.
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Updated by Neha Ojha over 1 year ago
- Project changed from Ceph to bluestore
- Category deleted (
OSD)
Updated by Kevin Fox over 1 year ago
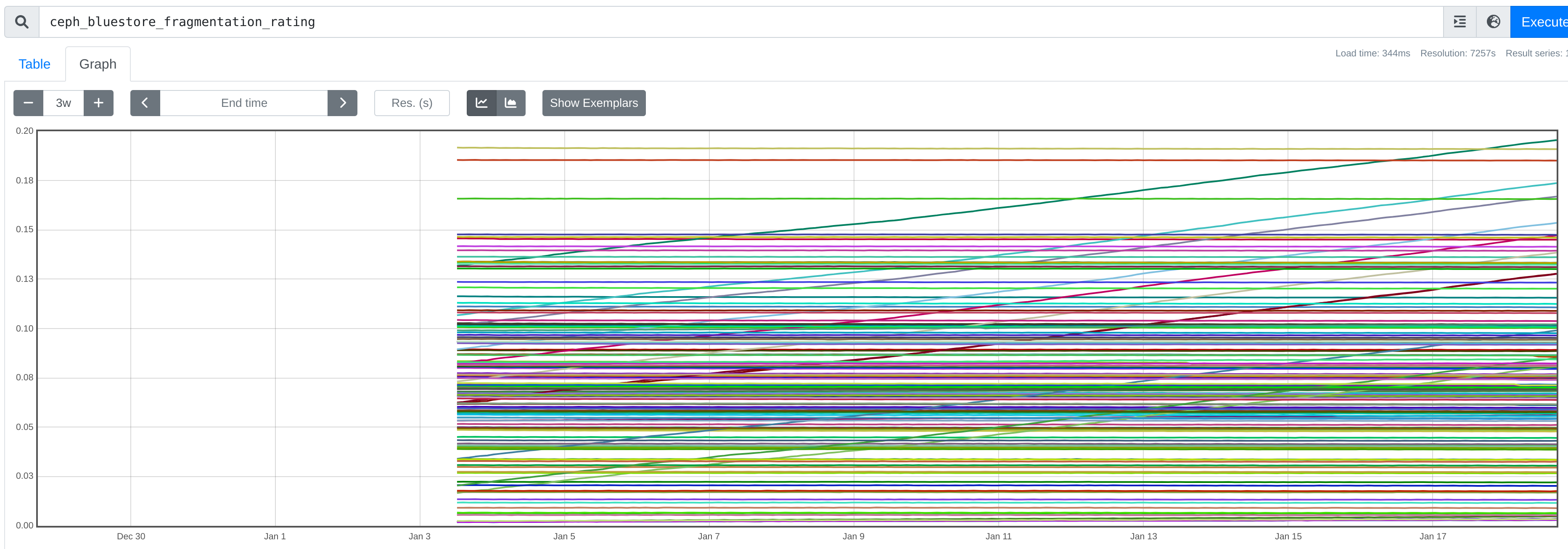
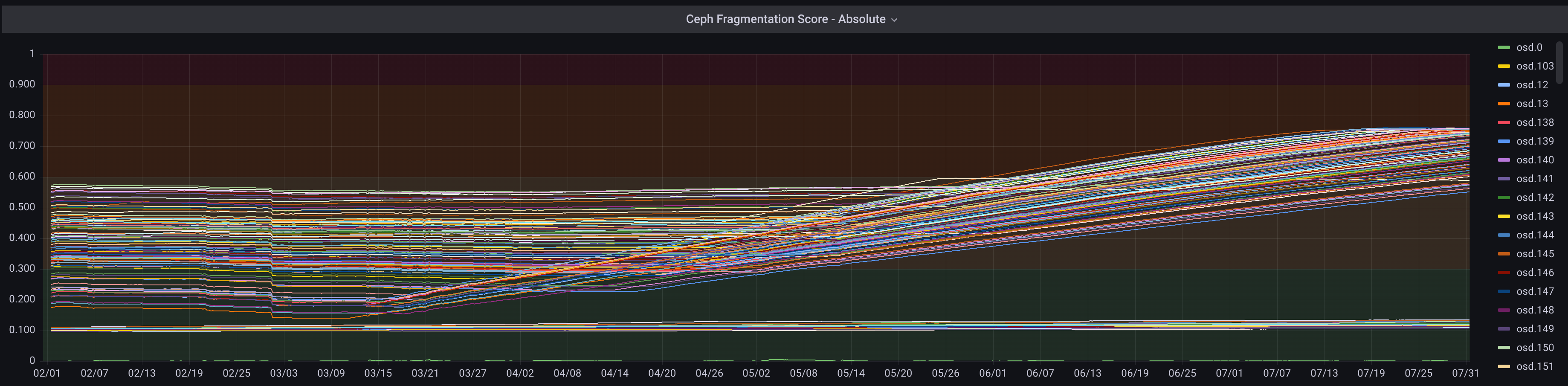
11 more osds started doing this over the holiday weekend.
Updated by Kevin Fox over 1 year ago
Newer picture, after I had just restarted the current batch of runaways.
Updated by Vikhyat Umrao over 1 year ago
Igor/Adam - "But the behavior stops immediately on restart. So feels like some thread in the osd is doing something unusual until restarted." this is pretty important information. How come a restart is helping? Maybe in restart we compact?
Kevin - are these osds have a heavy delete workload?
Updated by Kevin Fox over 1 year ago
These run away osds are not on the heavy delete workload cluster. Its a relatively lightly loaded cluster. though I can't say it doesn't experience slight moments of busyness. I haven't kept that close an eye on it. Not sure I could tell.
Is there a way to get a thread dump or something the next time we get a runaway one that might help shed light on the issue?
Updated by Kevin Fox about 1 year ago
We ended up slowly reformatting all of our osts and re-adding them. Things settled out to a fragmentation score of < .20.
I checked today and several ost's have been slowly but steadily been rising over the last 3 weeks of data I have. So, looks like it may still be a problem, even with freshly formatted osds.
Updated by Kevin Fox about 1 year ago
Here's a picture.
Updated by Kevin Fox about 1 year ago
If I strace a run away osd, it shows up with 59 threads. If I do it to one that is not run away, it shows up with 59 threads. So, no extra thread....
Updated by Igor Fedotov about 1 year ago
Vikhyat Umrao wrote:
Igor/Adam - "But the behavior stops immediately on restart. So feels like some thread in the osd is doing something unusual until restarted." this is pretty important information. How come a restart is helping? Maybe in restart we compact?
One potential explanation can be pretty trivial: allocator keeps tracking a sort of history(hints) where to start the next allocation from based on the previous allocation result(s). On restart this history is reset and allocations start over. Just a hypothesis...
Updated by Igor Fedotov about 1 year ago
At the first step I'd like to see allocation stats probes from OSD logs. Here is an example:
2023-01-20T16:28:41.464+0300 7fab001a66c0 0 bluestore(/home/if/ceph.2/build/dev/osd0) allocation stats probe 0: cnt: 1411 frags: 1411 size: 463032320
2023-01-20T16:28:41.464+0300 7fab001a66c0 0 bluestore(/home/if/ceph.2/build/dev/osd0) probe -1: 0, 0, 0
2023-01-20T16:28:41.464+0300 7fab001a66c0 0 bluestore(/home/if/ceph.2/build/dev/osd0) probe -2: 0, 0, 0
2023-01-20T16:28:41.464+0300 7fab001a66c0 0 bluestore(/home/if/ceph.2/build/dev/osd0) probe -4: 0, 0, 0
2023-01-20T16:28:41.464+0300 7fab001a66c0 0 bluestore(/home/if/ceph.2/build/dev/osd0) probe -8: 0, 0, 0
2023-01-20T16:28:41.464+0300 7fab001a66c0 0 bluestore(/home/if/ceph.2/build/dev/osd0) probe -16: 0, 0, 0
This shows amount of allocation requests (=cnt), amount of returned fragments(frags) and total allocated size for the last day, day before and 2/4/8/16 days before.
It's reset on OSD restart. Having a bunch of such probes we'll hopefully see how large is the difference (in terms of fragmentation) between allocations between and after restart. As well as how things are becoming worse over time without restart...
So please run through existing OSD logs and collect these allocation probes along with information about OSD restarts, relevant OSD log line looks like (actual version might vary):
2023-01-19T16:28:36.273+0300 7fab0fa05500 0 ceph version Development (no_version) reef (dev), process ceph-osd, pid 22499
Updated by Kevin Fox about 1 year ago
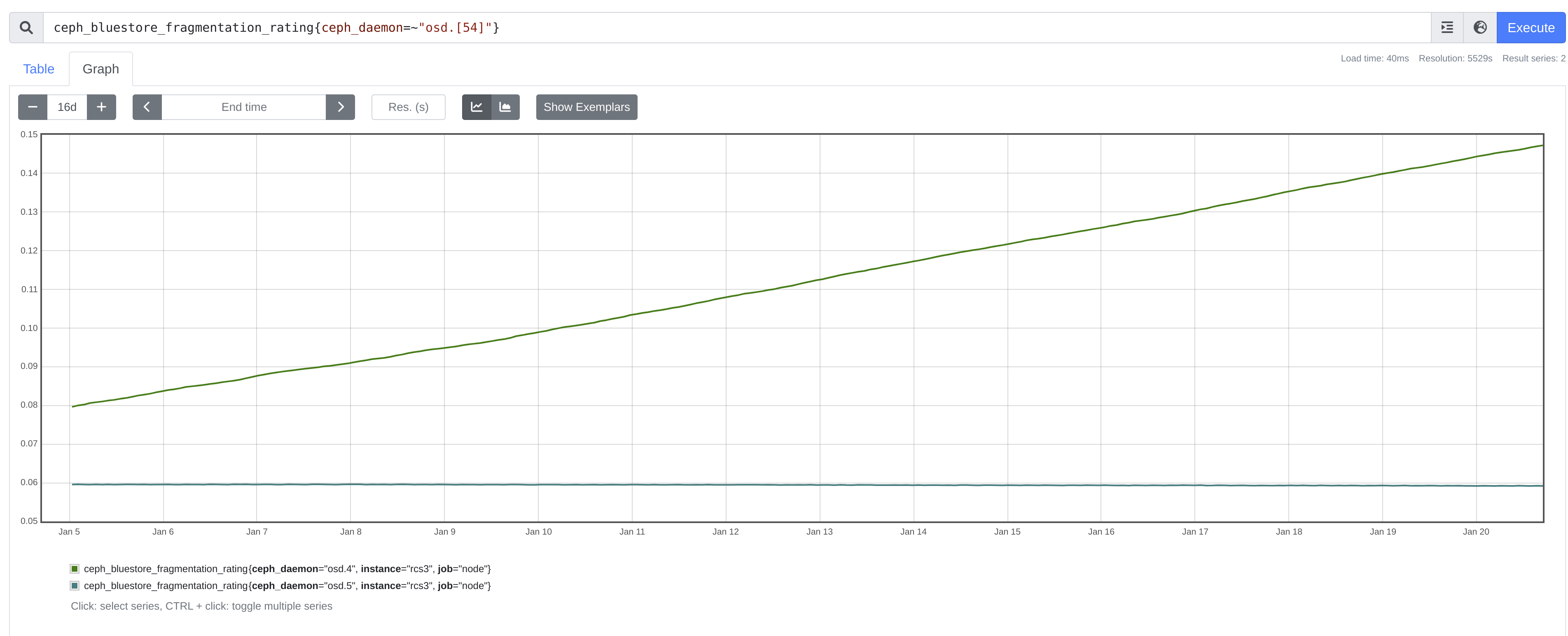
I can get some more, but here's an initial bit.
osd.4 has been running away for a long time (at least 2 weeks. based on slope, guessing maybe 3). osd.5 has not. both were started at the same time:
ELAPSED CMD
23-15:15:09 /usr/bin/ceph-osd -n osd.4 -f --setuser ceph --setgroup ceph --default-log-to-file=false --default-log-to-stderr=true --default-log-stderr-prefix=debug
23-15:14:13 /usr/bin/ceph-osd -n osd.5 -f --setuser ceph --setgroup ceph --default-log-to-file=false --default-log-to-stderr=true --default-log-stderr-prefix=debug
- journalctl -u ceph-b15015c8-af07-4973-b35d-28c3bfd2af22@osd.4.service | grep probe
Jan 19 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-20T01:40:46.719+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) allocation stats probe 22: cnt: 47025 frags: 47025 size: 51463442432
Jan 19 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-20T01:40:46.719+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -1: 47765, 47765, 51807432704
Jan 19 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-20T01:40:46.719+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -2: 51034, 51034, 54404734976
Jan 19 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-20T01:40:46.719+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -6: 48928, 48928, 51115958272
Jan 19 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-20T01:40:46.719+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -14: 36777, 36777, 45640888320
Jan 19 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-20T01:40:46.719+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -22: 543961, 543961, 1790549340160
- journalctl -u ceph-b15015c8-af07-4973-b35d-28c3bfd2af22@osd.5.service | grep probe
Jan 19 17:41:38 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-52103576: debug 2023-01-20T01:41:38.199+0000 7faacea1e700 0 bluestore(/var/lib/ceph/osd/ceph-5) allocation stats probe 22: cnt: 48968 frags: 48968 size: 50902216704
Jan 19 17:41:38 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-52103576: debug 2023-01-20T01:41:38.199+0000 7faacea1e700 0 bluestore(/var/lib/ceph/osd/ceph-5) probe -1: 44796, 44796, 51117088768
Jan 19 17:41:38 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-52103576: debug 2023-01-20T01:41:38.199+0000 7faacea1e700 0 bluestore(/var/lib/ceph/osd/ceph-5) probe -2: 47106, 47106, 52133576704
Jan 19 17:41:38 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-52103576: debug 2023-01-20T01:41:38.199+0000 7faacea1e700 0 bluestore(/var/lib/ceph/osd/ceph-5) probe -6: 47240, 47240, 48791560192
Jan 19 17:41:38 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-52103576: debug 2023-01-20T01:41:38.199+0000 7faacea1e700 0 bluestore(/var/lib/ceph/osd/ceph-5) probe -14: 39224, 39224, 47587168256
Jan 19 17:41:38 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-52103576: debug 2023-01-20T01:41:38.199+0000 7faacea1e700 0 bluestore(/var/lib/ceph/osd/ceph-5) probe -22: 529677, 529677, 1732095647744
Updated by Kevin Fox about 1 year ago
Here is a runaway one I restarted 2 days ago.
ELAPSED CMD
2-00:09:13 /usr/bin/ceph-osd -n osd.3 -f --setuser ceph --setgroup ceph --default-log-to-file=false --default-log-to-stderr=true --default-log-stderr-prefix=debugJan 19 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-19T17:25:36.555+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) allocation stats probe 0: cnt: 54513 frags: 54513 size: 51361972224
Jan 19 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-19T17:25:36.555+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -1: 0, 0, 0
Jan 19 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-19T17:25:36.555+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -2: 0, 0, 0
Jan 19 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-19T17:25:36.555+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -4: 0, 0, 0
Jan 19 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-19T17:25:36.555+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -8: 0, 0, 0
Jan 19 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-19T17:25:36.555+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -16: 0, 0, 0
Jan 20 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-20T17:25:36.583+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) allocation stats probe 1: cnt: 48357 frags: 48357 size: 48756817920
Jan 20 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-20T17:25:36.583+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -1: 54513, 54513, 51361972224
Jan 20 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-20T17:25:36.583+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -3: 0, 0, 0
Jan 20 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-20T17:25:36.583+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -5: 0, 0, 0
Jan 20 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-20T17:25:36.583+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -9: 0, 0, 0
Jan 20 09:25:36 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-33620262: debug 2023-01-20T17:25:36.583+0000 7f638b0e3700 0 bluestore(/var/lib/ceph/osd/ceph-3) probe -17: 0, 0, 0
Updated by Kevin Fox about 1 year ago
Here's osd4 that was still running away this morning. I just restarted it. Here's the right before metrics. Will get more soon.
[root@rcs3 ~]# journalctl -u ceph-b15015c8-af07-4973-b35d-28c3bfd2af22@osd.4.service | grep probe
Jan 22 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-23T01:40:46.765+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) allocation stats probe 25: cnt: 42495 frags: 42495 size: 45438136320
Jan 22 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-23T01:40:46.765+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -1: 42484, 42484, 44923281408
Jan 22 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-23T01:40:46.765+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -3: 47025, 47025, 51463442432
Jan 22 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-23T01:40:46.765+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -5: 51034, 51034, 54404734976
Jan 22 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-23T01:40:46.765+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -9: 48928, 48928, 51115958272
Jan 22 17:40:46 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-42099039: debug 2023-01-23T01:40:46.765+0000 7fe1350e5700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -25: 543961, 543961, 1790549340160
Updated by Kevin Fox about 1 year ago
After restart:
[root@rcs3 ~]# journalctl -u ceph-b15015c8-af07-4973-b35d-28c3bfd2af22@osd.4.service | grep probe
Jan 24 08:57:33 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-41524224: debug 2023-01-24T16:57:33.217+0000 7f1c9fb26700 0 bluestore(/var/lib/ceph/osd/ceph-4) allocation stats probe 0: cnt: 44417 frags: 44417 size: 52236275712
Jan 24 08:57:33 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-41524224: debug 2023-01-24T16:57:33.217+0000 7f1c9fb26700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -1: 0, 0, 0
Jan 24 08:57:33 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-41524224: debug 2023-01-24T16:57:33.217+0000 7f1c9fb26700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -2: 0, 0, 0
Jan 24 08:57:33 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-41524224: debug 2023-01-24T16:57:33.217+0000 7f1c9fb26700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -4: 0, 0, 0
Jan 24 08:57:33 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-41524224: debug 2023-01-24T16:57:33.217+0000 7f1c9fb26700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -8: 0, 0, 0
Jan 24 08:57:33 rcs3.cloud.pnnl.gov ceph-b15015c8-af07-4973-b35d-28c3bfd2af22-osd-41524224: debug 2023-01-24T16:57:33.217+0000 7f1c9fb26700 0 bluestore(/var/lib/ceph/osd/ceph-4) probe -16: 0, 0, 0
Updated by Adam Kupczyk about 1 year ago
Hi Kevin,
I have two questions:
1) Is rising fragmentation score related to change of free space?
If no other method is available, free space can be read by admin socket command "bluestore bluefs device info".
2) Might it be possible to collect few snapshots of "bluestore allocator dump block" from osd.3 or osd.4
(the hosts that showed increasing fragmentation that reversed trend after restart).
The overall inquiry I am targeting is to find out whether fragmentation calculation algorithm is too sensitive in some contexts.
It is possible that the algorithm behaves in following way:
a) 10MB free / 1KB data / 490MB free = fragmentation 0.08
b) 250MB free / 1KB data / 250MB free = fragmentation 0.14
Regards,
Adam
Updated by Kevin Fox about 1 year ago
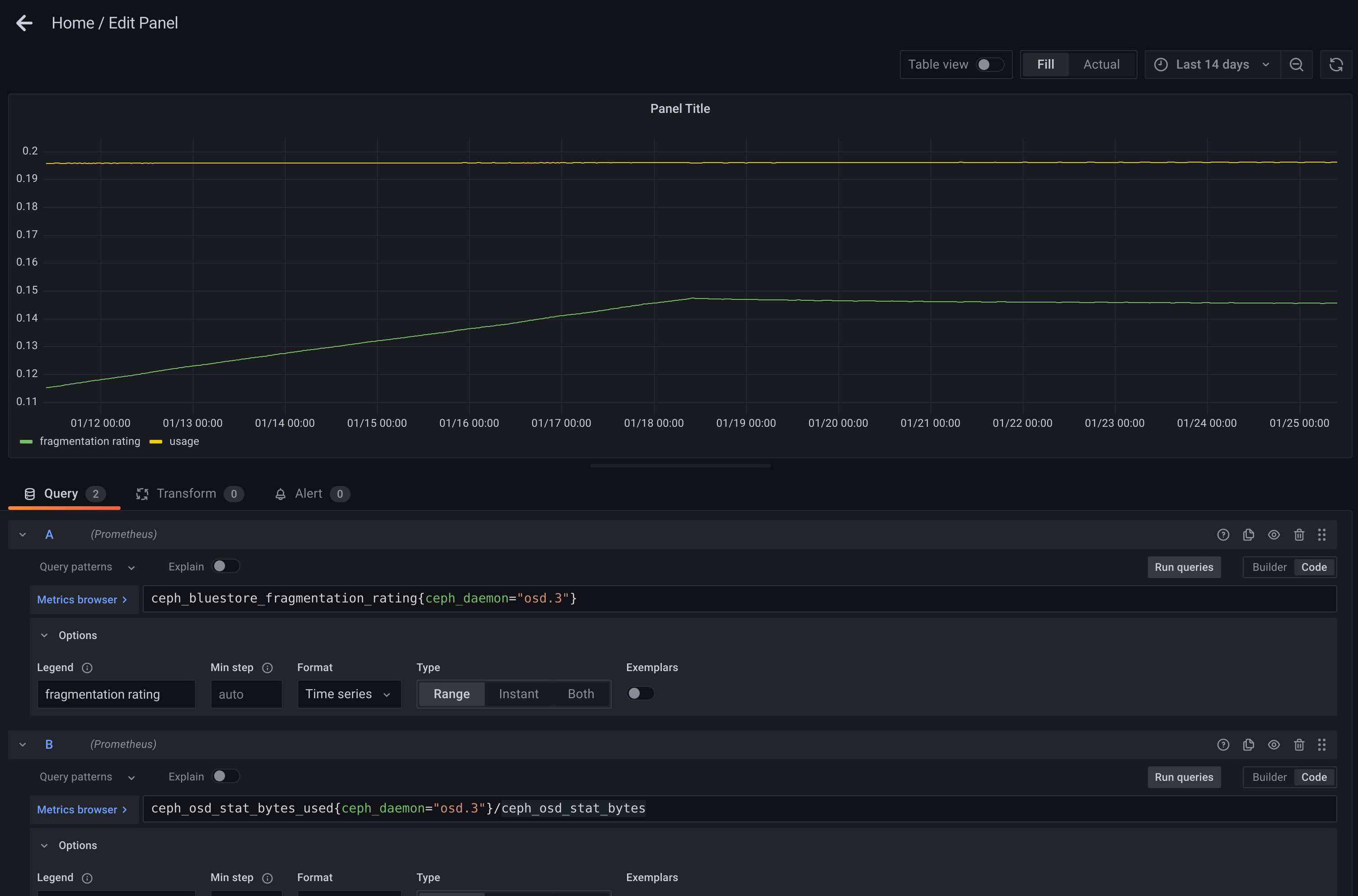
- File Screenshot from 2023-01-25 09-50-11.png Screenshot from 2023-01-25 09-50-11.png added
- File Screenshot from 2023-01-25 09-50-41.png Screenshot from 2023-01-25 09-50-41.png added
For question 1, here's a couple of screenshots with consumed space and fragmentation added to both. utilization is pretty constant in both cases.
I'll work on answering question 2.
Updated by Kevin Fox about 1 year ago
The patch implies that the calculation may be wrong? But why would behavior change on restart?
Thanks,
Kevin
Updated by Adam Kupczyk about 1 year ago
Igor Fedotov wrote:
One potential explanation can be pretty trivial: allocator keeps tracking a sort of history(hints) where to start the next allocation from based on the previous allocation result(s). On restart this history is reset and allocations start over. Just a hypothesis...
Kevin Fox wrote:
The patch implies that the calculation may be wrong? But why would behavior change on restart?
Thanks,
Kevin
The calculation was wrong in the sense that 100% fragmentation was unachievable (part 1 of PR)
I believed Igor's hypothesis so much that I decided to numb a bit fragmentation calculation algorithm (part 2 or PR).
To prove it I need "bluestore allocator dump"s.
Updated by Kevin Fox about 1 year ago
Just looking at lengths, there are lots of pretty small ones?:
[kfox@zathras tmp]$ jq '.extents[].length' osd.3 | sort | uniq -c | sort -k 1 -n | tail -n 4
3458 "0x20000"
4410 "0x70000"
9544 "0x1000"
55281 "0x10000"
[kfox@zathras tmp]$ jq '.extents[].length' osd.4 | sort | uniq -c | sort -k 1 -n | tail -n 4
2619 "0x20000"
4237 "0x70000"
11238 "0x1000"
44461 "0x10000"
Updated by Kevin Fox about 1 year ago
We got some monitoring on a 3rd cluster. we're seeing it there too, though slower then the other cluster.
I was seeing a fairly constant increase of ~0.000172 per hour to the fragmentation scores of a bunch of osds on it. It was upgraded from nautilus->octopus->pacific somewhere around end of October or early November I think. The scores were less then .20 then. Now there are some scores up just shy of .60. I restarted one a few days ago and its score has started decreasing a little bit rather then the constant increase.
Updated by Kevin Fox about 1 year ago
Anything else I can provide to help debug this?
Updated by Konstantin Shalygin 11 months ago
- Status changed from New to Pending Backport
- Source set to Community (user)
- Backport set to reef quincy pacific
- Pull request ID set to 49885
Updated by Backport Bot 11 months ago
- Copied to Backport #61463: quincy: Fragmentation score rising by seemingly stuck thread added
Updated by Backport Bot 11 months ago
- Copied to Backport #61464: pacific: Fragmentation score rising by seemingly stuck thread added
Updated by Backport Bot 11 months ago
- Copied to Backport #61465: reef: Fragmentation score rising by seemingly stuck thread added
Updated by Stefan Kooman 11 months ago
What BlueStore allocator did you use in Nautilus / Octopus? Did you use the defaults there (which should have been bitmap)? If nothing explicitly configured otherwise I guess you did. Did you set the minimum allocation size to 4K when you created the OSDs (in Nautilus)? So these parameters:
bluestore_min_alloc_size_ssd = 4096
bluestore_min_alloc_size_hdd = 4096
Or did you use the default settings by Nautilus (16K / 64K for SSD / HDD resp.)
Updated by Stefan Kooman 11 months ago
Kevin Fox wrote:
Used all defaults for nautilus. Haven't ever specified any of those flags.
OK. Then you might have different allocation sizes for different OSDs: OSDs created in Nautilus 16/64K and OSDs created in Pacific 4K. Do you also have this issue on the newly created OSDs?
Updated by Kevin Fox 9 months ago
Stefan Kooman wrote:
OK. Then you might have different allocation sizes for different OSDs: OSDs created in Nautilus 16/64K and OSDs created in Pacific 4K. Do you also have this issue on the newly created OSDs?
Was that this? https://github.com/ceph/ceph/pull/49884 I don't see it backported to a released Pacific though. Would we have to get to Quincy before reformatting to fix it?
Updated by Igor Fedotov 9 months ago
Kevin Fox wrote:
Stefan Kooman wrote:
OK. Then you might have different allocation sizes for different OSDs: OSDs created in Nautilus 16/64K and OSDs created in Pacific 4K. Do you also have this issue on the newly created OSDs?
Was that this? https://github.com/ceph/ceph/pull/49884 I don't see it backported to a released Pacific though.
No, this one enables 4K unit support for BlueFS and it hasn't been backported to Pacific yet.
But I was talking about 4K unit support for user/main data. Here it is:https://github.com/ceph/ceph/pull/34588
Would we have to get to Quincy before reformatting to fix it?
No, Pacific is enough to be able to reformat to get 4K main data allocation units.
Updated by Igor Fedotov 9 months ago
Kevin Fox wrote:
Ok, cool. Thanks for the info.
Would we want to reformat at Quincy to get the BlueFS 4k support too, or does that automatically kick in as needed?
No need to reformat to 4K BlueFS in Quincy. It will kick in automatically. Just one thing to mention - this is irreversible step - no downgrade is allowed when it's enabled.