Bug #56988
openmds: memory leak suspected
0%
Description
We are runnung a cephfs pacific cluster in production:
MDS version: ceph version 16.2.9 (4c3647a322c0ff5a1dd2344e039859dcbd28c830) pacific (stable)The six servers were installed using Rocky Linux 8.6 and configured using ceph-ansible from the "stable-6.0" branch.
The three MDS servers are running in an active/active/standby configuration:
mds_max_mds: 2The MDS pool is replicated:
cephfs_metadata_pool:
name: 'cephfs_201_metadata'
pg_num: 256
pgp_num: 256
size: 3 # i.e. 3 fold replication
type: 'replicated'
rule_name: 'crush_rule_mdnvme'
erasure_profile: ''
# expected_num_objects:
application: 'cephfs'
# min_size: '{{ osd_pool_default_min_size }}'
pg_autoscale_mode: no
target_size_ratio: 0.200
while the data pool is using erasure coding 4+2
cephfs_data_pool:
name: 'cephfs_201_data'
pg_num: 1024
pgp_num: 1024
type: 'erasure'
rule_name: 'crush_rule_ec42'
erasure_profile: 'ec42_profile'
# expected_num_objects:
application: 'cephfs'
size: "{{ ec42_profile.ec_config.m }}" # size==m: EC 4+2: k=4: m=2
# min_size: '{{ osd_pool_default_min_size }}'
pg_autoscale_mode: warn
target_size_ratio: 0.8500
The pools are also compressed:
bluestore_compression_algorithm: lz4
bluestore_compression_mode: aggressive
Devices in the data crush rule "crush_rule_ec42" are hard disks which are encrypted by LUKS. These are accelerated using NVMe SSDs as a write ahead log WAL. CephFS clients are using the kernel module cephfs from the SLES 11.3 kernel.
Problem:
The two active MDS-servers are increasingly consuming more memory.
Configured memory values.
[mds] mds_cache_memory = 24G mds_cache_memory_limit = 48G
are not adhered to.
Active MDS servers:
root@rrdfc06:~ $ceph fs status
cephfs_201 - 43 clients
==========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active rrdfc04 Reqs: 0 /s 1055k 1053k 73.6k 1174k
1 active rrdfc06 Reqs: 0 /s 24.5k 22.9k 1121 7853
POOL TYPE USED AVAIL
cephfs_201_metadata metadata 70.5G 876G
cephfs_201_data data 545T 124T
STANDBY MDS
rrdfc02
MDS version: ceph version 16.2.9 (4c3647a322c0ff5a1dd2344e039859dcbd28c830) pacific (stable)
Heap stats:
root@rrdfc06:~ $ceph tell mds.$(hostname -s) heap stats 2022-07-19T08:51:26.515+0200 7f19baffd700 0 client.319645 ms_handle_reset on v2:172.17.0.86:6800/3109409290 2022-07-19T08:51:26.529+0200 7f19baffd700 0 client.309893 ms_handle_reset on v2:172.17.0.86:6800/3109409290 mds.rrdfc06 tcmalloc heap stats:------------------------------------------------ MALLOC: 269974258480 (257467.5 MiB) Bytes in use by application MALLOC: + 180224 ( 0.2 MiB) Bytes in page heap freelist MALLOC: + 1919539832 ( 1830.6 MiB) Bytes in central cache freelist MALLOC: + 6489600 ( 6.2 MiB) Bytes in transfer cache freelist MALLOC: + 83483736 ( 79.6 MiB) Bytes in thread cache freelists MALLOC: + 1238499328 ( 1181.1 MiB) Bytes in malloc metadata MALLOC: ------------ MALLOC: = 273222451200 (260565.2 MiB) Actual memory used (physical + swap) MALLOC: + 279666688 ( 266.7 MiB) Bytes released to OS (aka unmapped) MALLOC: ------------ MALLOC: = 273502117888 (260831.9 MiB) Virtual address space used MALLOC: MALLOC: 18760628 Spans in use MALLOC: 22 Thread heaps in use MALLOC: 8192 Tcmalloc page size ------------------------------------------------ Call ReleaseFreeMemory() to release freelist memory to the OS (via madvise()). Bytes released to the OS take up virtual address space but no physical memory.
Restarting the MDS takes a bit:
root@rrdfc06:~ $time systemctl restart ceph-mds@rrdfc06.service real 1m45.460s user 0m0.005s sys 0m0.004s
but frees a lot of memory for the time being:
root@rrdfc06:~ $ceph tell mds.$(hostname -s) heap stats 2022-07-19T08:54:29.247+0200 7f277d7fa700 0 client.329514 ms_handle_reset on v2:172.17.0.86:6800/1793786924 2022-07-19T08:54:29.261+0200 7f277d7fa700 0 client.329520 ms_handle_reset on v2:172.17.0.86:6800/1793786924 mds.rrdfc06 tcmalloc heap stats:------------------------------------------------ MALLOC: 14006472 ( 13.4 MiB) Bytes in use by application MALLOC: + 647168 ( 0.6 MiB) Bytes in page heap freelist MALLOC: + 362264 ( 0.3 MiB) Bytes in central cache freelist MALLOC: + 310272 ( 0.3 MiB) Bytes in transfer cache freelist MALLOC: + 803872 ( 0.8 MiB) Bytes in thread cache freelists MALLOC: + 2752512 ( 2.6 MiB) Bytes in malloc metadata MALLOC: ------------ MALLOC: = 18882560 ( 18.0 MiB) Actual memory used (physical + swap) MALLOC: + 0 ( 0.0 MiB) Bytes released to OS (aka unmapped) MALLOC: ------------ MALLOC: = 18882560 ( 18.0 MiB) Virtual address space used MALLOC: MALLOC: 294 Spans in use MALLOC: 12 Thread heaps in use MALLOC: 8192 Tcmalloc page size ------------------------------------------------ Call ReleaseFreeMemory() to release freelist memory to the OS (via madvise()). Bytes released to the OS take up virtual address space but no physical memory.
Is there any way to analyse the root cause of this issue?
Currently I am restarting the MDS servers manually on a regular basis.
Files
.png){kind=link}
{kind=link}
Updated by Ramin Torabi over 1 year ago
- File graph.php(1).png graph.php(1).png added
Updated by Ramin Torabi over 1 year ago
I have automated restarting a single MDS-Server when MDS memory consumption is 80GB (roughly twice the configured mds_cache_memory_limit) and the cluster is healthy.
It appears to be a working workaround. When restarting an MDS Server the "backup" MDS becomes "active".
The main disadvantage I observed appears to be a temporary (one minute) health issue during restart:
[WARN] FS_DEGRADED: 1 filesystem is degraded
fs cephfs... is degraded
[WARN] MDS_INSUFFICIENT_STANDBY: insufficient standby MDS daemons available
have 0; want 1 more
Updated by Ramin Torabi over 1 year ago
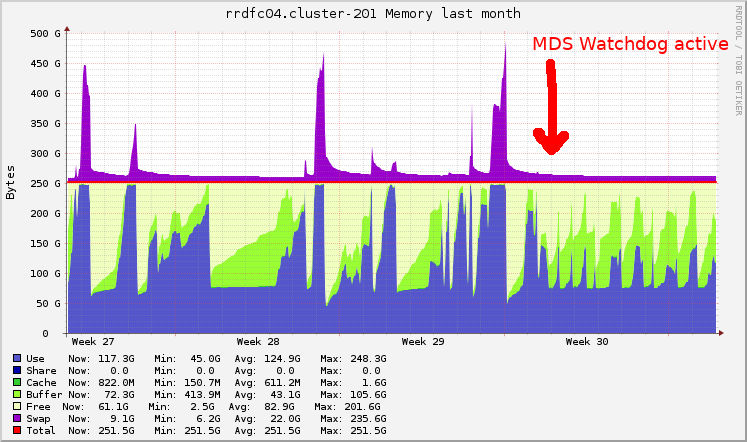
- File MDS_memory_arrow.jpg MDS_memory_arrow.jpg added
Here is a graph of the memory summary without and with the automated restart.
Updated by Venky Shankar over 1 year ago
- Status changed from New to Triaged
- Assignee set to Patrick Donnelly
- Target version set to v18.0.0
- Backport set to pacific,quincy
- Component(FS) MDS added
- Labels (FS) multimds added
Updated by Patrick Donnelly over 1 year ago
- Subject changed from memory leak in MDS suspected to mds: memory leak suspected
- Description updated (diff)
- Tags deleted (
mds memory)
Updated by Patrick Donnelly over 1 year ago
If you could capture
ceph tell mds.<fs_name>:0 perf dump
at regular intervals (1/5 min), especially when the event is in process, that would help.
Updated by Patrick Donnelly over 1 year ago
- Status changed from Triaged to Need More Info
Updated by Ramin Torabi over 1 year ago
I have attached the current "ceph tell mds.<fs_name>:0 perf dump" log files.
Files with the name:
ceph_mds_perf_<date>.txt
have been created by the snapshot taken every five minutes.
Files with the name:
ceph_mds_perf_watchdog_<date>.txt
have been created by the script that is restarting the MDS when memory consumption exceeds 80GB. The dump was created just before the restart.
You can extract the directory using:
tar -xvjpf 56988_2022-08-26_ceph_mds_perf.logs.tar.bz2
I hope that helps.