Bug #56733
openSince Pacific upgrade, sporadic latencies plateau on random OSD/disks
0%
Description
Hello,
Since our upgrade to Pacific, we suffer from sporadic latencies on disks, not always the same.
The cluster is backing an OpenStack Cloud, and VM workloads are very impacted during these latency episodes.
As we have SSD for rocksdb+wal, I found #56488, and increasing bluestore_prefer_deferred_size_hdd like mentioned have helped a bit, but we continue to see some high latency periods (30min to 1h), around 900ms (HDD). At 1ms, everything halts, and we have slow ops.
It seems, but I don't have enought occurence to be sure, that setting noscrub+nodeep-scrub during the event, stop it.
What's also unexpeted, is that the latency is on reads, impacting writes, not the reverse. During the latency plateau, there is not so much IOPS (~10) or Throughput (20MB/s) on the impacted drive.
The drive is OK in its SMART infos.
I've tried to remove the first drive/OSD I found having that problem, several times. But the problem happened on other OSD/drives.
Files
{kind=link}
Updated by Gilles Mocellin over 1 year ago
This morning, I have :
PG_NOT_DEEP_SCRUBBED: 11 pgs not deep-scrubbed in time
Never had before Pacific.
Could it be those scrubs/deep scrubs who create latency ? And being slower than before ?
Updated by Igor Fedotov over 1 year ago
Gilles Mocellin wrote:
This morning, I have :
PG_NOT_DEEP_SCRUBBED: 11 pgs not deep-scrubbed in time
Never had before Pacific.Could it be those scrubs/deep scrubs who create latency ? And being slower than before ?
Definitely it could be but that's just speculating so far.
Could you please grep osd logs for "timed out" and "slow operation observed" patterns and share relevant log if found.
Updated by Gilles Mocellin over 1 year ago
Zero occurrence of "timed out" in all my ceph-osds logs for 2 days. But, as I have increased bluestore_prefer_deferred_size_hdd like I say in #56488,
I have no more halts, just some non-visible impacts with increase in latency.
Ah, something I have not said : during the high latencies, when they are impacting, I also lose many metrics throught the MGR prometheus exporter.
Which can also be tied to the MGR freezes I had while tweaking bluestore_prefer_deferred_size_hdd :
The service (systemd) and process (ceph-mgr) were still UP, but no more logs and no more dashboard an prometheus metrics.
And ceph -s showed "no mgrs".
Updated by Gilles Mocellin over 1 year ago
I've just had a latency plateau. No scrub/deep-scrub on the impacted OSD during that time...
At least, no message in ceph-osd logs "scrub ok".
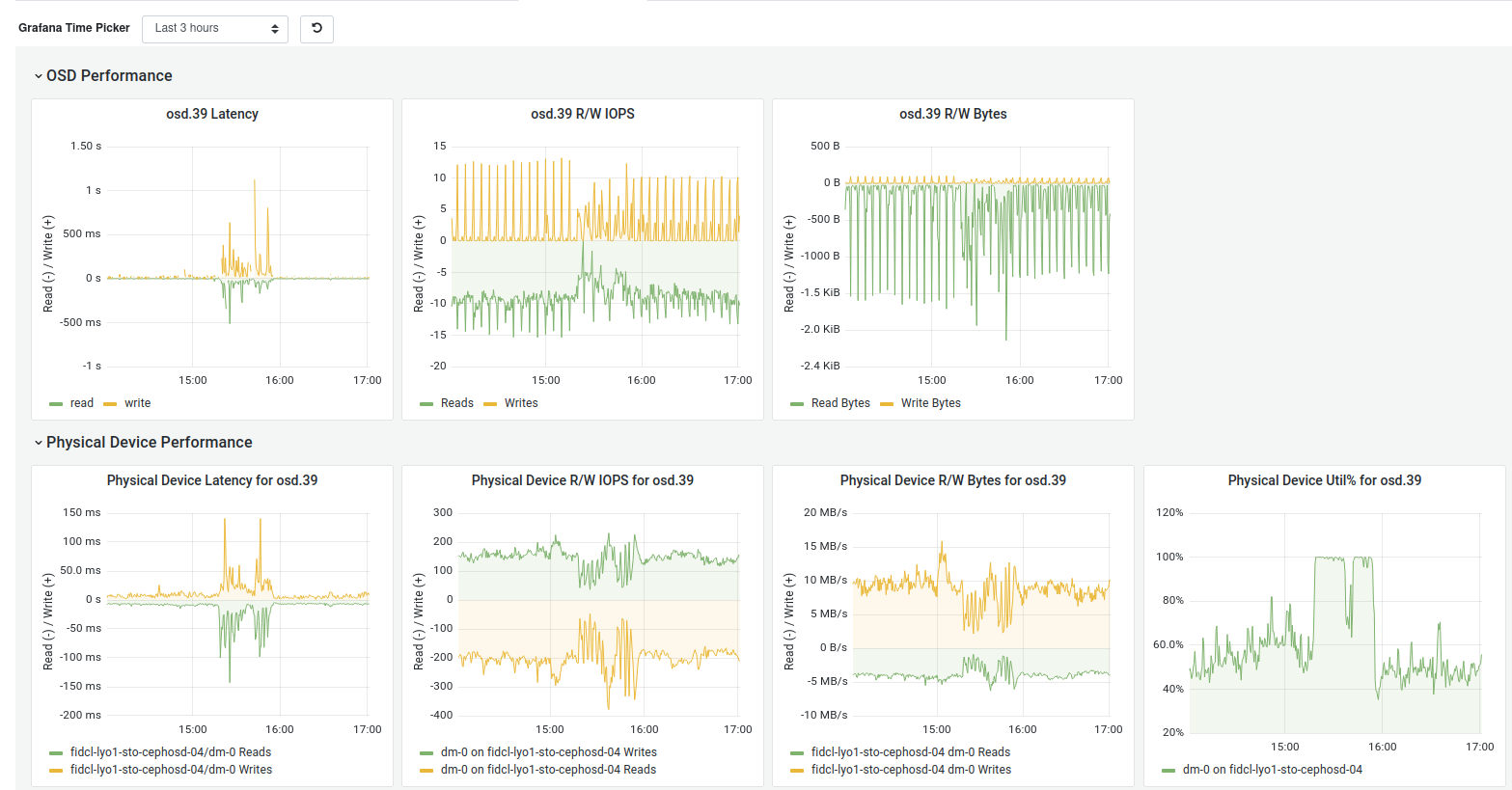
I join the dashboard graph of the impacted OSD, where we can see the latency and the 100% Util% for the drive.
Updated by Igor Fedotov over 1 year ago
To get some more insight on the issue I would suggest to do the following once the issue is faced again:
1) For OSD-in-question dump and store current performance counters via: ceph tell osd.N perf dump > original.perf
2) Reset that OSD perf counters: ceph tell osd.N perf reset all
3) Start collecting iostats output for relevant OSD drives, both main and DB ones.
4) Leave cluster running for e.g. 1 min
5) Dump and save counters again.
6) Share both dumps, iostat report and preferably monitor and osd logs.
Updated by Gilles Mocellin over 1 year ago
- File logs.tar.gz logs.tar.gz added
Hello,
We don't have as much stalled moments these last days, only ~ 5 min.
I've taken some logs but really at the end of the 100%usage for that OSD...
Still, I upload it here in case there's something.
Updated by Gilles Mocellin over 1 year ago
- File logs.tar.gz logs.tar.gz added
Hi,
Another longer one.
OSD.25, data on sdh, db on sdb
Updated by Gilles Mocellin over 1 year ago
Just a follow-up.
Finally, what's helping us the best is increasing osd_scrub_sleep to 0.4.
Updated by Adam Kupczyk over 1 year ago
- Project changed from bluestore to RADOS
It seems more like generic RADOS issue.
Updated by Radoslaw Zarzynski over 1 year ago
I've just let Mark and Ronen know about this issue.