Feature #56543
openAbout the performance improvement of ceph's erasure code storage pool
0%
Description
Hello everyone:
Although I know that the erause code storage pool is not suitable for use in scenarios with many random reads and writes. But I still try to improve the performance of ceph's erasure code storage pool.
The current erasuce code storage pool has the following problems.
1. Before reading data, the stripe alignment of the read operation is required. This will not only cause read amplification, but also because the data of each stripe is stored in k osds on average, so each read operation requires k osd coordination. that is, Read data from k osd, which will definitely affect the response time of the read request.
2. Before writing data, it may be necessary to read the unchanged data in the corresponding strip and recalculate the erasure code chunks. This will reduce the performance of writing.
For the above problem, I think that:
1.For read requests, use chunk alignment instead of strip alignment. In this way, for some small read requests, only read data from one osd can be returned. For example, the data to be read falls on exactly one chunk.
2.For write requests, I noticed that isa's encoding library provides the function of updating erasure code chunks based on modified data chunks. That is, when only n chunks out of k data chunks are needed, only the modified data chunks needs to be read again, and erasure code chunks, you can calculate the modified erasure code chunks. I think modifying the writing process based on this idea can have a positive effect on performance when the value of k is much larger than the value of m.
3. In order to let a read request fall on one osd as much as possible, I will set the stripe very large, so that each chunk can be correspondingly large, such as chunk_size=1M.And because the erasure code is calculated in the original process It is done according to the stripe size, and when the stripe is too large, it takes longer to calculate. Therefore, I introduced the concept of subchunk. At this time, the calculation of erasure code will be performed according to the size of k*subchunk.
As shown below: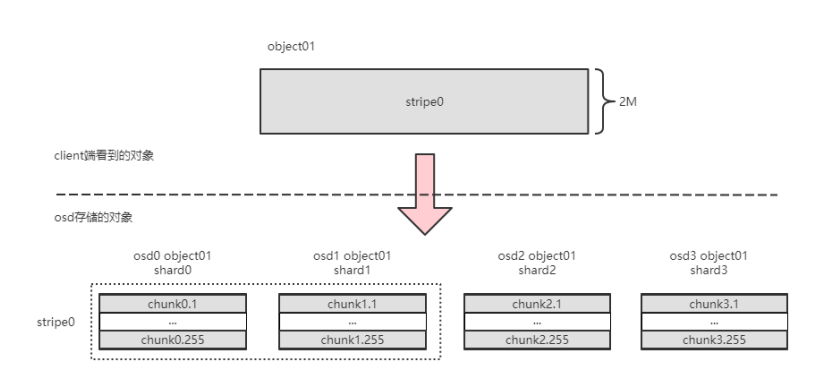
Chunk0.1, chunk1.1, chunk2.1, chunk3.1 calculate erasure code together. and so on
Before I start to modify the source code, I want to know if this idea is feasible and whether it is worth changing in this way?
thanks!
Files