Bug #53809
closedcephfs: fsync on small directory takes multiple seconds
0%
Description
Our application needs to ensure durability of written files before acknowledging that writes were done, ensuring that the file cannot be lost.
Thus, it performs `fsync()` on the written file (to make file contents durable), and `fsync()` on the directory containing the file (to make the dirent durable). (The need for that on local file systems is explained e.g. in this Ceph talk, and I believe it is necessary for Ceph as well.)
Writing a small benchmark, I noticed that on CephFS, `fsync` on a directory is extremely, unreasonably slow for this pattern:
# mkdir /mycephfs/niklas-test
# cd /mycephfs/niklas-test
# strace -fy -e fsync -T sh -c 'for i in {1..10}; do touch new-"$i"; sync .; done'
fsync(3</mycephfs/niklas-test>) = 0 <0.635923>
fsync(3</mycephfs/niklas-test>) = 0 <3.557392>
fsync(3</mycephfs/niklas-test>) = 0 <0.001497>
fsync(3</mycephfs/niklas-test>) = 0 <3.085821>
fsync(3</mycephfs/niklas-test>) = 0 <1.879268>
fsync(3</mycephfs/niklas-test>) = 0 <4.998007>
fsync(3</mycephfs/niklas-test>) = 0 <0.004683>
fsync(3</mycephfs/niklas-test>) = 0 <4.975168>
fsync(3</mycephfs/niklas-test>) = 0 <5.029351>
fsync(3</mycephfs/niklas-test>) = 0 <0.001417>
The directory fsyncs take up to 5 seconds!
This is unreasonable to me because I cannot come up with any operation on this < 10 file directory that could possibly take 5 seconds.
This CephFS is backed by 3 idle nodes with 10G networking, 0.3ms ping, metadata pool backed by enterprise NVMe SSDs, and data pool backed by spinning disks.
Version is 16.2.7, Linux 5.10.81 kernel mount.
I've tried with/without `client cache size = 0` (same results), and the same issue happens on a single-node CephFS deployment, which should excludes the possibility that the network has anything to do with it.
While the above loop is running, Ceph reports that almost no IO is going on:
# ceph osd pool stats pool device_health_metrics id 1 nothing is going on pool mycephfs_data id 2 nothing is going on pool mycephfs_metadata id 3 client io 2.3 KiB/s wr, 0 op/s rd, 1 op/s wr
Files
{kind=link}
Updated by Niklas Hambuechen over 2 years ago
What I find highly suspicious is that in ceph daemon mds.mymds dump_historic_ops the duration is always exactly 5 seconds:
{
"description": "client_request(client.234413:5882727 create #0x1000051bbe0/new-2 2022-01-09T06:39:49.522049+0000 caller_uid=0, caller_gid=0{})",
"initiated_at": "2022-01-09T06:39:49.523941+0000",
"age": 18.562613953,
"duration": 4.9968328140000002,
"type_data": {
"flag_point": "done",
"reqid": "client.234413:5882727",
"op_type": "client_request",
"client_info": {
"client": "client.234413",
"tid": 5882727
},
"events": [
{
"time": "2022-01-09T06:39:49.523941+0000",
"event": "initiated"
},
{
"time": "2022-01-09T06:39:49.523943+0000",
"event": "throttled"
},
{
"time": "2022-01-09T06:39:49.523941+0000",
"event": "header_read"
},
{
"time": "2022-01-09T06:39:49.523951+0000",
"event": "all_read"
},
{
"time": "2022-01-09T06:39:49.523966+0000",
"event": "dispatched"
},
{
"time": "2022-01-09T06:39:49.524009+0000",
"event": "acquired locks"
},
{
"time": "2022-01-09T06:39:49.524115+0000",
"event": "early_replied"
},
{
"time": "2022-01-09T06:39:49.524116+0000",
"event": "submit entry: journal_and_reply"
},
{
"time": "2022-01-09T06:39:54.520615+0000",
"event": "journal_committed: "
},
{
"time": "2022-01-09T06:39:54.520673+0000",
"event": "replying"
},
{
"time": "2022-01-09T06:39:54.520766+0000",
"event": "finishing request"
},
{
"time": "2022-01-09T06:39:54.520773+0000",
"event": "cleaned up request"
},
{
"time": "2022-01-09T06:39:54.520774+0000",
"event": "done"
}
]
}
},
{
"description": "client_request(client.234413:5882729 create #0x1000051bbe0/new-4 2022-01-09T06:39:59.522055+0000 caller_uid=0, caller_gid=0{})",
"initiated_at": "2022-01-09T06:39:59.523948+0000",
"age": 8.5626067050000003,
"duration": 4.9966590000000002,
"type_data": {
"flag_point": "done",
"reqid": "client.234413:5882729",
"op_type": "client_request",
"client_info": {
"client": "client.234413",
"tid": 5882729
},
"events": [
{
"time": "2022-01-09T06:39:59.523948+0000",
"event": "initiated"
},
{
"time": "2022-01-09T06:39:59.523950+0000",
"event": "throttled"
},
{
"time": "2022-01-09T06:39:59.523948+0000",
"event": "header_read"
},
{
"time": "2022-01-09T06:39:59.523957+0000",
"event": "all_read"
},
{
"time": "2022-01-09T06:39:59.523975+0000",
"event": "dispatched"
},
{
"time": "2022-01-09T06:39:59.524025+0000",
"event": "acquired locks"
},
{
"time": "2022-01-09T06:39:59.524139+0000",
"event": "early_replied"
},
{
"time": "2022-01-09T06:39:59.524140+0000",
"event": "submit entry: journal_and_reply"
},
{
"time": "2022-01-09T06:40:04.520541+0000",
"event": "journal_committed: "
},
{
"time": "2022-01-09T06:40:04.520579+0000",
"event": "replying"
},
{
"time": "2022-01-09T06:40:04.520601+0000",
"event": "finishing request"
},
{
"time": "2022-01-09T06:40:04.520607+0000",
"event": "cleaned up request"
},
{
"time": "2022-01-09T06:40:04.520607+0000",
"event": "done"
}
]
}
}
Note the:
"duration": 4.9968328140000002, "duration": 4.9966590000000002,
Updated by Niklas Hambuechen over 2 years ago
Even weirder:
If, while that loop is running, I run
while sleep 0.01; do find /mycephfs/niklas-test; done
on the directory, the the fsync loop magically get sped up incredibly, which each fsync() taking ~ 9 ms:
fsync(3</mycephfs/niklas-test>) = 0 <0.004106>
fsync(3</mycephfs/niklas-test>) = 0 <0.009055>
fsync(3</mycephfs/niklas-test>) = 0 <0.008634>
fsync(3</mycephfs/niklas-test>) = 0 <0.006691>
fsync(3</mycephfs/niklas-test>) = 0 <0.008084>
fsync(3</mycephfs/niklas-test>) = 0 <0.010671>
fsync(3</mycephfs/niklas-test>) = 0 <0.009246>
fsync(3</mycephfs/niklas-test>) = 0 <0.009263>
So doing a read on the directory somehow gets the fsync() out of its 5 second sleep on CephFS.
Updated by Xiubo Li over 2 years ago
The following commit have fixed it in kernel:
commit e1a4541ec0b951685a49d1f72d183681e6433a45
Author: Xiubo Li <xiubli@redhat.com>
Date: Mon Jul 5 09:22:57 2021 +0800
ceph: flush the mdlog before waiting on unsafe reqs
For the client requests who will have unsafe and safe replies from
MDS daemons, in the MDS side the MDS daemons won't flush the mdlog
(journal log) immediatelly, because they think it's unnecessary.
That's true for most cases but not all, likes the fsync request.
The fsync will wait until all the unsafe replied requests to be
safely replied.
Normally if there have multiple threads or clients are running, the
whole mdlog in MDS daemons could be flushed in time if any request
will trigger the mdlog submit thread. So usually we won't experience
the normal operations will stuck for a long time. But in case there
has only one client with only thread is running, the stuck phenomenon
maybe obvious and the worst case it must wait at most 5 seconds to
wait the mdlog to be flushed by the MDS's tick thread periodically.
This patch will trigger to flush the mdlog in the relevant and auth
MDSes to which the in-flight requests are sent just before waiting
the unsafe requests to finish.
Signed-off-by: Xiubo Li <xiubli@redhat.com>
Reviewed-by: Jeff Layton <jlayton@kernel.org>
Signed-off-by: Ilya Dryomov <idryomov@gmail.com>
Updated by Xiubo Li over 2 years ago
- Project changed from Ceph to Linux kernel client
Updated by Niklas Hambuechen over 2 years ago
Thanks for the link.
According to https://github.com/torvalds/linux/commit/e1a4541ec0b951685a49d1f72d183681e6433a45, the patch is included in Linux >= 5.15; I will try that.
Updated by Niklas Hambuechen over 2 years ago
I confirm the problem is resolved on Linux 5.15.
This issue can be closed.
Thank you!
Updated by Xiubo Li over 2 years ago
- Status changed from New to Resolved
- Assignee set to Xiubo Li
- ceph-qa-suite kcephfs added
Niklas Hambuechen wrote:
I confirm the problem is resolved on Linux 5.15.
This issue can be closed.
Thank you!
Cool, will close it.
Updated by Niklas Hambuechen over 2 years ago
- File node-6-kernel-5.15-crash-dump-screenshot.png node-6-kernel-5.15-crash-dump-screenshot.png added
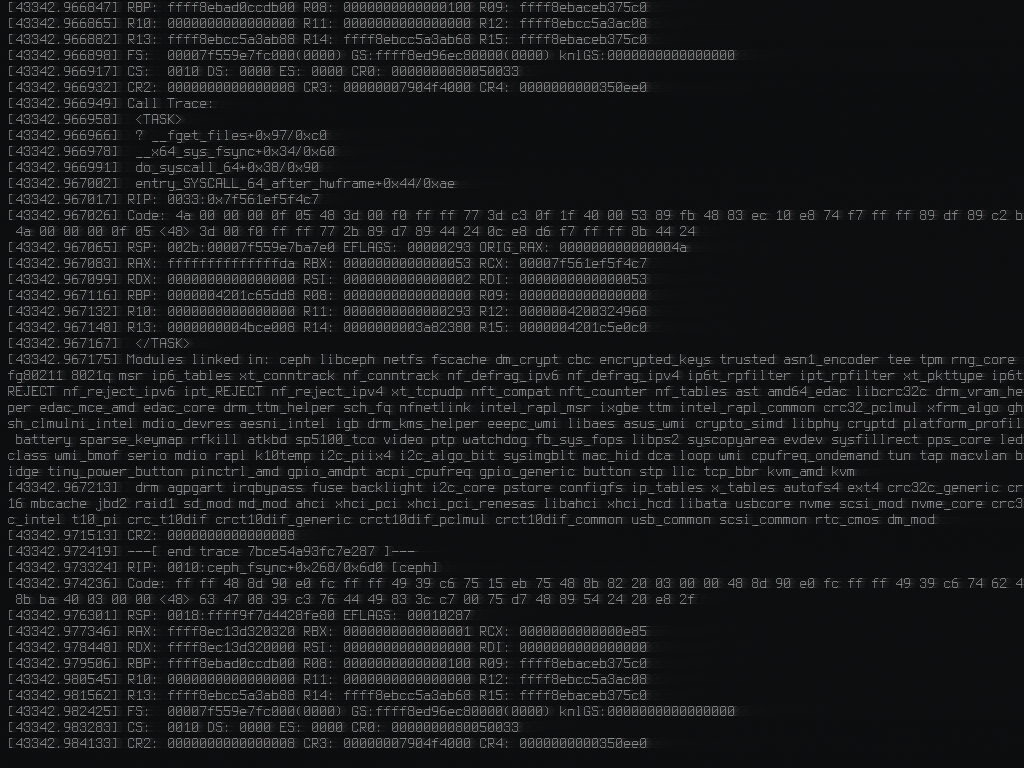
Unfortunately, the 5.15 kernel today crashed all 3 server/OSD nodes of my Ceph cluster simulatneously with a kernel null pointer dereference:
Jan 10 15:23:46 node-4 kernel: BUG: kernel NULL pointer dereference, address: 0000000000000008 Jan 10 15:23:46 node-4 kernel: #PF: supervisor read access in kernel mode Jan 10 15:23:46 node-4 kernel: #PF: error_code(0x0000) - not-present page
Thus I had to roll back to the 5.10 kernel.
I suspect that the Crash is in the Ceph kernel module, because these machines mainly run Ceph, and there wouldn't be much else that would be able to synchronise those machines to crash at exactly the same time.
2 more nodes that are Ceph clients (not servers) were also upgraded to the 5.15 kernel. Those did not crash.
More evidence that it's related to Ceph, since there's fsync in the crash trace:
Call Trace: <TASK> ? __fget_files+0x97/0xc0 __x64_sys_fsync+0x34/0x60 do_syscall_64...
Updated by Niklas Hambuechen over 2 years ago
I have extracted the crash bug into: https://tracker.ceph.com/issues/53819
Updated by Xiubo Li over 2 years ago
Please try the following commit:
commit 708c87168b6121abc74b2a57d0c498baaf70cbea (tag: ceph-for-5.15-rc3)
Author: Dan Carpenter <dan.carpenter@oracle.com>
Date: Mon Sep 6 12:43:01 2021 +0300
ceph: fix off by one bugs in unsafe_request_wait()
The "> max" tests should be ">= max" to prevent an out of bounds access
on the next lines.
Fixes: e1a4541ec0b9 ("ceph: flush the mdlog before waiting on unsafe reqs")
Signed-off-by: Dan Carpenter <dan.carpenter@oracle.com>
Reviewed-by: Ilya Dryomov <idryomov@gmail.com>
Signed-off-by: Ilya Dryomov <idryomov@gmail.com>
Updated by Xiubo Li about 2 years ago
- Related to Bug #55327: kclient: BUG: kernel NULL pointer dereference, address: 0000000000000008 added