Bug #53142
openOSD crash in PG::do_delete_work when increasing PGs
0%
9743daf0af885ccf8d408cb19eaf38e2101736261b85f2eb0de9a40a29ce1788
Description
I've attached the file and put the crash signature also.
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Updated by Neha Ojha over 2 years ago
- Project changed from Ceph to RADOS
- Category deleted (
OSD)
Updated by Neha Ojha over 2 years ago
{
"backtrace": [
"(()+0x12b20) [0x7f15054ecb20]",
"(pread64()+0x57) [0x7f15054ec207]",
"(KernelDevice::read(unsigned long, unsigned long, ceph::buffer::v15_2_0::list*, IOContext*, bool)+0x31b) [0x55c4a8d3eeeb]",
"(BlueFS::_read(BlueFS::FileReader*, BlueFS::FileReaderBuffer*, unsigned long, unsigned long, ceph::buffer::v15_2_0::list*, char*)+0x7d3) [0x55c4a8ce51b3]",
"(BlueRocksRandomAccessFile::Prefetch(unsigned long, unsigned long)+0x2e) [0x55c4a8d1648e]",
"(rocksdb::BlockBasedTableIterator<rocksdb::DataBlockIter, rocksdb::Slice>::InitDataBlock()+0x27f) [0x55c4a92a952f]",
"(rocksdb::BlockBasedTableIterator<rocksdb::DataBlockIter, rocksdb::Slice>::FindKeyForward()+0x18c) [0x55c4a92a971c]",
"(()+0x10d83f9) [0x55c4a92353f9]",
"(rocksdb::MergingIterator::Next()+0x33) [0x55c4a92ba903]",
"(rocksdb::DBIter::FindNextUserEntryInternal(bool, bool)+0x3a5) [0x55c4a91cd655]",
"(rocksdb::DBIter::Next()+0x31e) [0x55c4a91ce59e]",
"(RocksDBStore::RocksDBWholeSpaceIteratorImpl::next()+0x31) [0x55c4a9140461]",
"(()+0xa5daea) [0x55c4a8bbaaea]",
"(BlueStore::_collection_list(BlueStore::Collection*, ghobject_t const&, ghobject_t const&, int, bool, std::vector<ghobject_t, std::allocator<ghobject_t> >*, ghobject_t*)+0xdf8) [0x55c4a8bf0c48]",
"(BlueStore::collection_list(boost::intrusive_ptr<ObjectStore::CollectionImpl>&, ghobject_t const&, ghobject_t const&, int, std::vector<ghobject_t, std::allocator<ghobject_t> >*, ghobject_t*)+0x2a6) [0x55c4a8bf2076]",
"(PG::do_delete_work(ceph::os::Transaction&, ghobject_t)+0x1100) [0x55c4a87ff850]",
"(PeeringState::Deleting::react(PeeringState::DeleteSome const&)+0xc0) [0x55c4a89b32a0]",
"(boost::statechart::simple_state<PeeringState::Deleting, PeeringState::ToDelete, boost::mpl::list<mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na, mpl_::na>, (boost::statechart::history_mode)0>::react_impl(boost::statechart::event_base const&, void const*)+0x125) [0x55c4a8a16305]",
"(boost::statechart::state_machine<PeeringState::PeeringMachine, PeeringState::Initial, std::allocator<boost::statechart::none>, boost::statechart::null_exception_translator>::process_event(boost::statechart::event_base const&)+0x5b) [0x55c4a8808aeb]",
"(PG::do_peering_event(std::shared_ptr<PGPeeringEvent>, PeeringCtx&)+0x2d1) [0x55c4a87fb191]",
"(OSD::dequeue_peering_evt(OSDShard*, PG*, std::shared_ptr<PGPeeringEvent>, ThreadPool::TPHandle&)+0x29c) [0x55c4a87724cc]",
"(OSD::dequeue_delete(OSDShard*, PG*, unsigned int, ThreadPool::TPHandle&)+0xc8) [0x55c4a87726a8]",
"(OSD::ShardedOpWQ::_process(unsigned int, ceph::heartbeat_handle_d*)+0x12ef) [0x55c4a876517f]",
"(ShardedThreadPool::shardedthreadpool_worker(unsigned int)+0x5c4) [0x55c4a8da36f4]",
"(ShardedThreadPool::WorkThreadSharded::entry()+0x14) [0x55c4a8da6354]",
"(()+0x814a) [0x7f15054e214a]",
"(clone()+0x43) [0x7f1504212dc3]"
],
"ceph_version": "15.2.14",
"crash_id": "2021-11-03T14:15:17.604400Z_3d379ee1-1517-44a8-b1a4-aaaff43f3cf4",
"entity_name": "osd.3",
"os_id": "centos",
"os_name": "CentOS Linux",
"os_version": "8",
"os_version_id": "8",
"process_name": "ceph-osd",
"stack_sig": "9743daf0af885ccf8d408cb19eaf38e2101736261b85f2eb0de9a40a29ce1788",
"timestamp": "2021-11-03T14:15:17.604400Z",
"utsname_hostname": "server-6s05",
"utsname_machine": "x86_64",
"utsname_release": "4.18.0-305.19.1.el8_4.x86_64",
"utsname_sysname": "Linux",
"utsname_version": "#1 SMP Wed Sep 15 15:39:39 UTC 2021"
}
Updated by Neha Ojha over 2 years ago
- Subject changed from Pg increase before finished osd crashed and dropped this backtrace to OSD crash in PG::do_delete_work when increasing PGs
Updated by Neha Ojha over 2 years ago
- Status changed from New to Need More Info
Do you have any more information about this crash? How often do you see it?
Updated by Igor Fedotov over 2 years ago
Can we have a relevant OSD log, please. I presume suicide timeout/slow DB operations are present there.
Updated by Ist Gab over 2 years ago
- File osd-crashes.PNG osd-crashes.PNG added
- File ssd.png ssd.png added
Neha Ojha wrote:
Do you have any more information about this crash? How often do you see it?
I have quite a lot on my list (attached osd-crashes.png).
- Some background information:
- started to see issues once we crossed the billions of objects in the cluster
- 3 site multisite setup in different GEO locations
- data pool is on a 4:2 erasure coded pool which is host based.
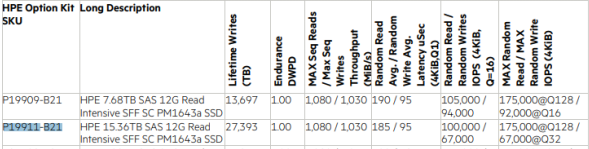
- 7 hosts in the cluster, each of them 4-6 15.3TB SAS SSD osds, the ssd spec I've attached on the ssd.png screenshot.
- 128pg at the moment in the data pool
- 30-40% space used on the osd disk
- due to spillovers, high iowait due to 100% db+wal disks utilization (maxed out constantly) we've migrated out the db back to the block device
What my assumption is, with ec 4:2 1 object we chunk to 4 pieces and store additional 2 pieces for redundancy on different hosts.
Once the user request a file it will collect the chunks from 4 hosts and provide it to the user, but if 1 osd on 1 host has compaction maybe or don't know what the disk is doing which keeps the disk busy, that disks (or because we are using host based crush rule let's say 1 host as a unit which has osds) slower than the other and the faster hosts are waiting for that chunk to serve the user, it generates slow ops and gateway will crash due to waiting for the host to serve the request. Once the gateway crash, that time close the connection and free up that osd and move further.
Next time can serve once the osd not busy.
Might be a totally wrong assumption though.
- osd log
2021-11-04T21:01:47.430+0700 7f69bb41a700 0 log_channel(cluster) log [WRN] : slow request osd_op(client.150445532.0:1066278871 28.68s0 28:169c3971:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHI
TELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f10418:head [getxattrs out=946b,stat out=16b,read 0~69811] snapc 0=[] ondisk+read+known_if_redirected e39035) initiated 2021-11-04T21:01:17.08
4346+0700 currently started
2021-11-04T21:01:47.430+0700 7f69bb41a700 0 log_channel(cluster) log [WRN] : slow request osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de8.54274098.2_prope
rty%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,setxattr user.rgw.man
ifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,setxattr user.rgw.
x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,setxattr user.rgw.x-
amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035
) initiated 2021-11-04T21:01:15.671487+0700 currently started
2021-11-04T21:01:47.430+0700 7f69bb41a700 -1 osd.12 39035 get_health_metrics reporting 2 slow ops, oldest is osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de
8.54274098.2_property%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,set
xattr user.rgw.manifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,
setxattr user.rgw.x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,se
txattr user.rgw.x-amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if
_redirected e39035)
2021-11-04T21:01:48.433+0700 7f69bb41a700 0 log_channel(cluster) log [WRN] : slow request osd_op(client.150445532.0:1066278871 28.68s0 28:169c3971:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f10418:head [getxattrs out=946b,stat out=16b,read 0~69811] snapc 0=[] ondisk+read+known_if_redirected e39035) initiated 2021-11-04T21:01:17.084346+0700 currently started
2021-11-04T21:01:48.433+0700 7f69bb41a700 0 log_channel(cluster) log [WRN] : slow request osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de8.54274098.2_property%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,setxattr user.rgw.manifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,setxattr user.rgw.x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,setxattr user.rgw.x-amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035) initiated 2021-11-04T21:01:15.671487+0700 currently started
2021-11-04T21:01:48.433+0700 7f69bb41a700 -1 osd.12 39035 get_health_metrics reporting 2 slow ops, oldest is osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de8.54274098.2_property%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,setxattr user.rgw.manifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,setxattr user.rgw.x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,setxattr user.rgw.x-amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035)
2021-11-04T21:01:49.447+0700 7f69bb41a700 0 log_channel(cluster) log [WRN] : slow request osd_op(client.150445532.0:1066278871 28.68s0 28:169c3971:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f10418:head [getxattrs out=946b,stat out=16b,read 0~69811] snapc 0=[] ondisk+read+known_if_redirected e39035) initiated 2021-11-04T21:01:17.084346+0700 currently started
2021-11-04T21:01:49.447+0700 7f69bb41a700 0 log_channel(cluster) log [WRN] : slow request osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de8.54274098.2_property%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,setxattr user.rgw.manifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,setxattr user.rgw.x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,setxattr user.rgw.x-amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035) initiated 2021-11-04T21:01:15.671487+0700 currently started
2021-11-04T21:01:49.447+0700 7f69bb41a700 -1 osd.12 39035 get_health_metrics reporting 2 slow ops, oldest is osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de8.54274098.2_property%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,setxattr user.rgw.manifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,setxattr user.rgw.x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,setxattr user.rgw.x-amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035)
2021-11-04T21:01:50.484+0700 7f69bb41a700 0 log_channel(cluster) log [WRN] : slow request osd_op(client.150445532.0:1066278871 28.68s0 28:169c3971:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f10418:head [getxattrs out=946b,stat out=16b,read 0~69811] snapc 0=[] ondisk+read+known_if_redirected e39035) initiated 2021-11-04T21:01:17.084346+0700 currently started
- historical slow ops dump:
"description": "osd_op(client.150445532.0:1066295737 28.68s0 28:1750de0d:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f48361:head [create,setxattr user.rgw.idtag (57) in=14b,setxattr user.rgw.tail_tag (57) in=17b,writefull 0~78504,setxattr user.rgw.manifest (374) in=17b,setxattr user.rgw.acl (123) in=12b,setxattr user.rgw.content_type (10) in=21b,setxattr user.rgw.etag (32) in=13b,setxattr user.rgw.x-amz-meta-storagetimestamp (40) in=36b,call rgw.obj_store_pg_ver in=19b,setxattr user.rgw.source_zone (4) in=20b] snapc 0=[] ondisk+write+known_if_redirected e39035)", "initiated_at": "2021-11-04T21:01:29.308192+0700", "age": 740.51418881899997, "duration": 57.116480441999997, "type_data": { "flag_point": "started", "client_info": { "client": "client.150445532", "client_addr": "10.118.199.3:0/3483696077", "tid": 1066295737 }, "events": [ { "event": "initiated", "time": "2021-11-04T21:01:29.308192+0700", "duration": 0 }, { "event": "throttled", "time": "2021-11-04T21:01:29.308192+0700", "duration": 9.5538999999999994e-05 }, { "event": "header_read", "time": "2021-11-04T21:01:29.308287+0700", "duration": 1.4619999999999999e-06 }, { "event": "all_read", "time": "2021-11-04T21:01:29.308289+0700", "duration": 7.0200000000000001e-07 }, { "event": "dispatched", "time": "2021-11-04T21:01:29.308289+0700", "duration": 1.6729999999999999e-06 }, { "event": "queued_for_pg", "time": "2021-11-04T21:01:29.308291+0700", "duration": 2.4666000000000001e-05 }, { "event": "reached_pg", "time": "2021-11-04T21:01:29.308316+0700", "duration": 0.00020235699999999999 }, { "event": "started", "time": "2021-11-04T21:01:29.308518+0700", "duration": 57.116154043000002 }, { "event": "done", "time": "2021-11-04T21:02:26.424672+0700", "duration": 57.116480441999997 } ] } }, { "description": "osd_op(client.150445532.0:1066295852 28.68s0 28:1750de0d:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f48361:head [getxattrs,stat,read 0~78518] snapc 0=[] ondisk+read+known_if_redirected e39035)", "initiated_at": "2021-11-04T21:01:29.393863+0700", "age": 740.42851778600004, "duration": 57.031000145, "type_data": { "flag_point": "started", "client_info": { "client": "client.150445532", "client_addr": "10.118.199.3:0/3483696077", "tid": 1066295852 }, "events": [ { "event": "initiated", "time": "2021-11-04T21:01:29.393863+0700", "duration": 0 }, { "event": "throttled", "time": "2021-11-04T21:01:29.393863+0700", "duration": 1.863e-06 }, { "event": "header_read", "time": "2021-11-04T21:01:29.393865+0700", "duration": 1.6130000000000001e-06 }, { "event": "all_read", "time": "2021-11-04T21:01:29.393866+0700", "duration": 4.51e-07 }, { "event": "dispatched", "time": "2021-11-04T21:01:29.393867+0700", "duration": 2.0640000000000001e-06 }, { "event": "queued_for_pg", "time": "2021-11-04T21:01:29.393869+0700", "duration": 1.9456000000000001e-05 }, { "event": "reached_pg", "time": "2021-11-04T21:01:29.393888+0700", "duration": 1.2564e-05 }, { "event": "started", "time": "2021-11-04T21:01:29.393901+0700", "duration": 57.030962133999999 }, { "event": "done", "time": "2021-11-04T21:02:26.424863+0700", "duration": 57.031000145 } ] } }, { "description": "osd_op(client.146815323.0:1414659157 28.68s0 28:16f7309d:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f77833:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~56763 in=56763b,setxattr user.rgw.manifest (374) in=391b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (10) in=31b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-meta-storagetimestamp (40) in=76b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035)", "initiated_at": "2021-11-04T21:01:33.521528+0700", "age": 736.30085227799998, "duration": 52.90413564, "type_data": { "flag_point": "started", "client_info": { "client": "client.146815323", "client_addr": "10.118.199.1:0/3205233932", "tid": 1414659157 }, "events": [ { "event": "initiated", "time": "2021-11-04T21:01:33.521528+0700", "duration": 0 }, { "event": "throttled", "time": "2021-11-04T21:01:33.521528+0700", "duration": 7.0710999999999994e-05 }, { "event": "header_read", "time": "2021-11-04T21:01:33.521599+0700", "duration": 1.0920000000000001e-06 }, { "event": "all_read", "time": "2021-11-04T21:01:33.521600+0700", "duration": 4.7100000000000002e-07 }, { "event": "dispatched", "time": "2021-11-04T21:01:33.521601+0700", "duration": 1.824e-06 }, { "event": "queued_for_pg", "time": "2021-11-04T21:01:33.521602+0700", "duration": 2.8442999999999999e-05 }, { "event": "reached_pg", "time": "2021-11-04T21:01:33.521631+0700", "duration": 3.6557999999999998e-05 }, { "event": "waiting for readable", "time": "2021-11-04T21:01:33.521667+0700", "duration": 52.856743354000002 }, { "event": "reached_pg", "time": "2021-11-04T21:02:26.378411+0700", "duration": 0.000170438 }, { "event": "started", "time": "2021-11-04T21:02:26.378581+0700", "duration": 0.047082749 }, { "event": "done", "time": "2021-11-04T21:02:26.425664+0700", "duration": 52.90413564 } ] } }, { "description": "osd_op(client.150445532.0:1066300881 28.68s0 28:17c06cd2:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f47924:head [create,setxattr user.rgw.idtag (57) in=14b,setxattr user.rgw.tail_tag (57) in=17b,writefull 0~73747,setxattr user.rgw.manifest (374) in=17b,setxattr user.rgw.acl (123) in=12b,setxattr user.rgw.content_type (10) in=21b,setxattr user.rgw.etag (32) in=13b,setxattr user.rgw.x-amz-meta-storagetimestamp (40) in=36b,call rgw.obj_store_pg_ver in=19b,setxattr user.rgw.source_zone (4) in=20b] snapc 0=[] ondisk+write+known_if_redirected e39035)", "initiated_at": "2021-11-04T21:01:34.425412+0700", "age": 735.39696850600001, "duration": 52.001978928, "type_data": { "flag_point": "started", "client_info": { "client": "client.150445532", "client_addr": "10.118.199.3:0/3483696077", "tid": 1066300881 }, "events": [ { "event": "initiated", "time": "2021-11-04T21:01:34.425412+0700", "duration": 0 }, { "event": "throttled", "time": "2021-11-04T21:01:34.425412+0700", "duration": 0.000114343 }, { "event": "header_read", "time": "2021-11-04T21:01:34.425526+0700", "duration": 3.7170000000000002e-06 }, { "event": "all_read", "time": "2021-11-04T21:01:34.425530+0700", "duration": 1.542e-06 }, { "event": "dispatched", "time": "2021-11-04T21:01:34.425532+0700", "duration": 3.1559999999999999e-06 }, { "event": "queued_for_pg", "time": "2021-11-04T21:01:34.425535+0700", "duration": 2.1290000000000001e-05 }, { "event": "reached_pg", "time": "2021-11-04T21:01:34.425556+0700", "duration": 1.9545999999999999e-05 }, { "event": "waiting for readable", "time": "2021-11-04T21:01:34.425576+0700", "duration": 51.953375704999999 }, { "event": "reached_pg", "time": "2021-11-04T21:02:26.378951+0700", "duration": 0.00012220800000000001 }, { "event": "started", "time": "2021-11-04T21:02:26.379074+0700", "duration": 0.048317420999999999 }, { "event": "done", "time": "2021-11-04T21:02:26.427391+0700", "duration": 52.001978928 } ] } },
- ceph.log
2021-11-04T21:01:28.804204+0700 mgr.-2s03 (mgr.114601456) 1372852 : cluster [DBG] pgmap v1381366: 425 pgs: 1 active+clean+laggy, 3 active+clean+scrubbing, 4 active+clean+scrubbing+deep, 417 act ive+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 12 MiB/s rd, 12 MiB/s wr, 3.76k op/s 2021-11-04T21:01:30.806198+0700 mgr.-2s03 (mgr.114601456) 1372853 : cluster [DBG] pgmap v1381367: 425 pgs: 2 active+clean+laggy, 3 active+clean+scrubbing, 4 active+clean+scrubbing+deep, 416 act ive+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 13 MiB/s rd, 12 MiB/s wr, 3.51k op/s 2021-11-04T21:01:32.807872+0700 mgr.-2s03 (mgr.114601456) 1372854 : cluster [DBG] pgmap v1381368: 425 pgs: 3 active+clean+laggy, 3 active+clean+scrubbing, 4 active+clean+scrubbing+deep, 415 act ive+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 11 MiB/s rd, 8.1 MiB/s wr, 3.68k op/s 2021-11-04T21:01:34.809722+0700 mgr.-2s03 (mgr.114601456) 1372855 : cluster [DBG] pgmap v1381369: 425 pgs: 1 active+clean+scrubbing+laggy, 4 active+clean+laggy, 2 active+clean+scrubbing, 4 acti ve+clean+scrubbing+deep, 414 active+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 11 MiB/s rd, 8.3 MiB/s wr, 4.70k op/s 2021-11-04T21:01:36.811319+0700 mgr.-2s03 (mgr.114601456) 1372856 : cluster [DBG] pgmap v1381370: 425 pgs: 1 active+clean+scrubbing+laggy, 4 active+clean+laggy, 2 active+clean+scrubbing, 4 acti ve+clean+scrubbing+deep, 414 active+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 11 MiB/s rd, 8.1 MiB/s wr, 5.95k op/s 2021-11-04T21:01:38.812897+0700 mgr.-2s03 (mgr.114601456) 1372857 : cluster [DBG] pgmap v1381371: 425 pgs: 1 active+clean+scrubbing+laggy, 4 active+clean+laggy, 2 active+clean+scrubbing, 4 acti ve+clean+scrubbing+deep, 414 active+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 9.6 MiB/s rd, 7.0 MiB/s wr, 5.86k op/s 2021-11-04T21:01:40.814860+0700 mgr.-2s03 (mgr.114601456) 1372858 : cluster [DBG] pgmap v1381372: 425 pgs: 1 active+clean+scrubbing+laggy, 4 active+clean+laggy, 2 active+clean+scrubbing, 4 acti ve+clean+scrubbing+deep, 414 active+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 8.4 MiB/s rd, 5.5 MiB/s wr, 5.83k op/s 2021-11-04T21:01:42.816493+0700 mgr.-2s03 (mgr.114601456) 1372859 : cluster [DBG] pgmap v1381373: 425 pgs: 1 active+clean+scrubbing+laggy, 5 active+clean+laggy, 2 active+clean+scrubbing, 4 acti ve+clean+scrubbing+deep, 413 active+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 5.9 MiB/s rd, 3.3 MiB/s wr, 5.54k op/s 2021-11-04T21:01:44.818349+0700 mgr.-2s03 (mgr.114601456) 1372860 : cluster [DBG] pgmap v1381374: 425 pgs: 1 active+clean+scrubbing+laggy, 5 active+clean+laggy, 2 active+clean+scrubbing, 4 acti ve+clean+scrubbing+deep, 413 active+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 4.4 MiB/s rd, 3.5 MiB/s wr, 4.54k op/s 2021-11-04T21:01:46.819911+0700 mgr.-2s03 (mgr.114601456) 1372861 : cluster [DBG] pgmap v1381375: 425 pgs: 1 active+clean+scrubbing+laggy, 5 active+clean+laggy, 2 active+clean+scrubbing, 4 acti ve+clean+scrubbing+deep, 413 active+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 2.8 MiB/s rd, 2.7 MiB/s wr, 3.02k op/s 2021-11-04T21:01:47.431172+0700 osd.12 (osd.12) 4903 : cluster [WRN] slow request osd_op(client.150445532.0:1066278871 28.68s0 28:169c3971:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f10418:head [getxattrs out=946b,stat out=16b,read 0~69811] snapc 0=[] ondisk+read+known_if_redirected e39035) initiated 2021-11-04T21:01:17.084346+0700 currently started 2021-11-04T21:01:47.431199+0700 osd.12 (osd.12) 4904 : cluster [WRN] slow request osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de8.54274098.2_property%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,setxattr user.rgw.manifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,setxattr user.rgw.x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,setxattr user.rgw.x-amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035) initiated 2021-11-04T21:01:15.671487+0700 currently started 2021-11-04T21:01:47.800702+0700 mon.-2s01 (mon.0) 4158262 : cluster [WRN] Health check failed: 0 slow ops, oldest one blocked for 30 sec, osd.20 has slow ops (SLOW_OPS) 2021-11-04T21:01:48.434699+0700 osd.12 (osd.12) 4905 : cluster [WRN] slow request osd_op(client.150445532.0:1066278871 28.68s0 28:169c3971:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f10418:head [getxattrs out=946b,stat out=16b,read 0~69811] snapc 0=[] ondisk+read+known_if_redirected e39035) initiated 2021-11-04T21:01:17.084346+0700 currently started 2021-11-04T21:01:48.434710+0700 osd.12 (osd.12) 4906 : cluster [WRN] slow request osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de8.54274098.2_property%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,setxattr user.rgw.manifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,setxattr user.rgw.x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,setxattr user.rgw.x-amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035) initiated 2021-11-04T21:01:15.671487+0700 currently started 2021-11-04T21:01:48.821466+0700 mgr.-2s03 (mgr.114601456) 1372862 : cluster [DBG] pgmap v1381376: 425 pgs: 1 active+clean+scrubbing+laggy, 5 active+clean+laggy, 2 active+clean+scrubbing, 4 active+clean+scrubbing+deep, 413 active+clean; 85 TiB data, 143 TiB used, 441 TiB / 599 TiB avail; 964 KiB/s rd, 2.5 MiB/s wr, 1.22k op/s 2021-11-04T21:01:49.447809+0700 osd.12 (osd.12) 4907 : cluster [WRN] slow request osd_op(client.150445532.0:1066278871 28.68s0 28:169c3971:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f10418:head [getxattrs out=946b,stat out=16b,read 0~69811] snapc 0=[] ondisk+read+known_if_redirected e39035) initiated 2021-11-04T21:01:17.084346+0700 currently started 2021-11-04T21:01:49.447822+0700 osd.12 (osd.12) 4908 : cluster [WRN] slow request osd_op(client.142546321.0:2090547370 28.68s0 28:166020e4:::9213182a-14ba-48ad-bde9-289a1c0c0de8.54274098.2_property%2f15257256%2f184530384%2f7df8f5ce0726900b9d43c8c021b15669.jpg:head [create,setxattr user.rgw.idtag (57) in=71b,setxattr user.rgw.tail_tag (57) in=74b,writefull 0~45797 in=45797b,setxattr user.rgw.manifest (389) in=406b,setxattr user.rgw.acl (123) in=135b,setxattr user.rgw.content_type (11) in=32b,setxattr user.rgw.etag (32) in=45b,setxattr user.rgw.x-amz-content-sha256 (35) in=64b,setxattr user.rgw.x-amz-date (17) in=36b,setxattr user.rgw.x-amz-decoded-content-length (6) in=43b,setxattr user.rgw.x-amz-meta-content-length (6) in=40b,setxattr user.rgw.x-amz-meta-height (4) in=30b,setxattr user.rgw.x-amz-meta-image-type (23) in=53b,setxattr user.rgw.x-amz-meta-width (4) in=29b,call rgw.obj_store_pg_ver in=44b,setxattr user.rgw.source_zone (4) in=24b] snapc 0=[] ondisk+write+known_if_redirected e39035) initiated 2021-11-04T21:01:15.671487+0700 currently started 2021-11-04T21:01:50.485420+0700 osd.12 (osd.12) 4909 : cluster [WRN] slow request osd_op(client.150445532.0:1066278871 28.68s0 28:169c3971:::9213182a-14ba-48ad-bde9-289a1c0c0de8.6034919.1_%2fWHITELABEL-1%2fPAGETPYE-7%2fDEVICE-4%2fLANGUAGE-34%2fSUBTYPE-0%2f10418:head [getxattrs out=946b,stat out=16b,read 0~69811] snapc 0=[] ondisk+read+known_if_redirected e39035) initiated 2021-11-04T21:01:17.084346+0700 currently started
Also can see many logs like:
2021-11-08T17:41:12.129059+0700 mon.sg-cephmon-6s01 (mon.0) 6310376 : cluster [DBG] osd.28 reported failed by osd.4
- Situation can be better a bit if I compact offline, but it is temporary.
- Also super weird, after increasing the pgs, more osd down issue is coming
Updated by Ist Gab over 2 years ago
Igor Fedotov wrote:
Can we have a relevant OSD log, please. I presume suicide timeout/slow DB operations are present there.
To keep the osds alive at the moment it's permanently set in the ceph.conf the following:
osd_op_thread_suicide_timeout=2000 osd_op_thread_timeout=90
DB is now colocated with block.
Updated by Ist Gab over 2 years ago
- File latency.PNG latency.PNG added
Have a look the latency.png, please, all the spikes are almost outage.
Updated by Neha Ojha over 2 years ago
Can you try to set a higher value of "osd delete sleep" and see if that helps?
Updated by Ist Gab over 2 years ago
Neha Ojha wrote:
Can you try to set a higher value of "osd delete sleep" and see if that helps?
Which one specificly and what would be the multiplier? Like x10 or just double?
These are the defaults:
"osd_delete_sleep": "0.000000",
"osd_delete_sleep_hdd": "5.000000",
"osd_delete_sleep_hybrid": "1.000000",
"osd_delete_sleep_ssd": "1.000000",
Updated by Neha Ojha over 2 years ago
Ist Gab wrote:
Neha Ojha wrote:
Can you try to set a higher value of "osd delete sleep" and see if that helps?
Which one specificly and what would be the multiplier? Like x10 or just double?
These are the defaults:
"osd_delete_sleep": "0.000000",
"osd_delete_sleep_hdd": "5.000000",
"osd_delete_sleep_hybrid": "1.000000",
"osd_delete_sleep_ssd": "1.000000",
Set osd_delete_sleep to 2 secs and go higher if this does not help. Setting osd_delete_sleep takes precedence of backend specific variants. Note that increasing this value will make PGs take longer to be deleted but should reduce the overall impact of PG deletion on the other operations.
Updated by Ist Gab over 2 years ago
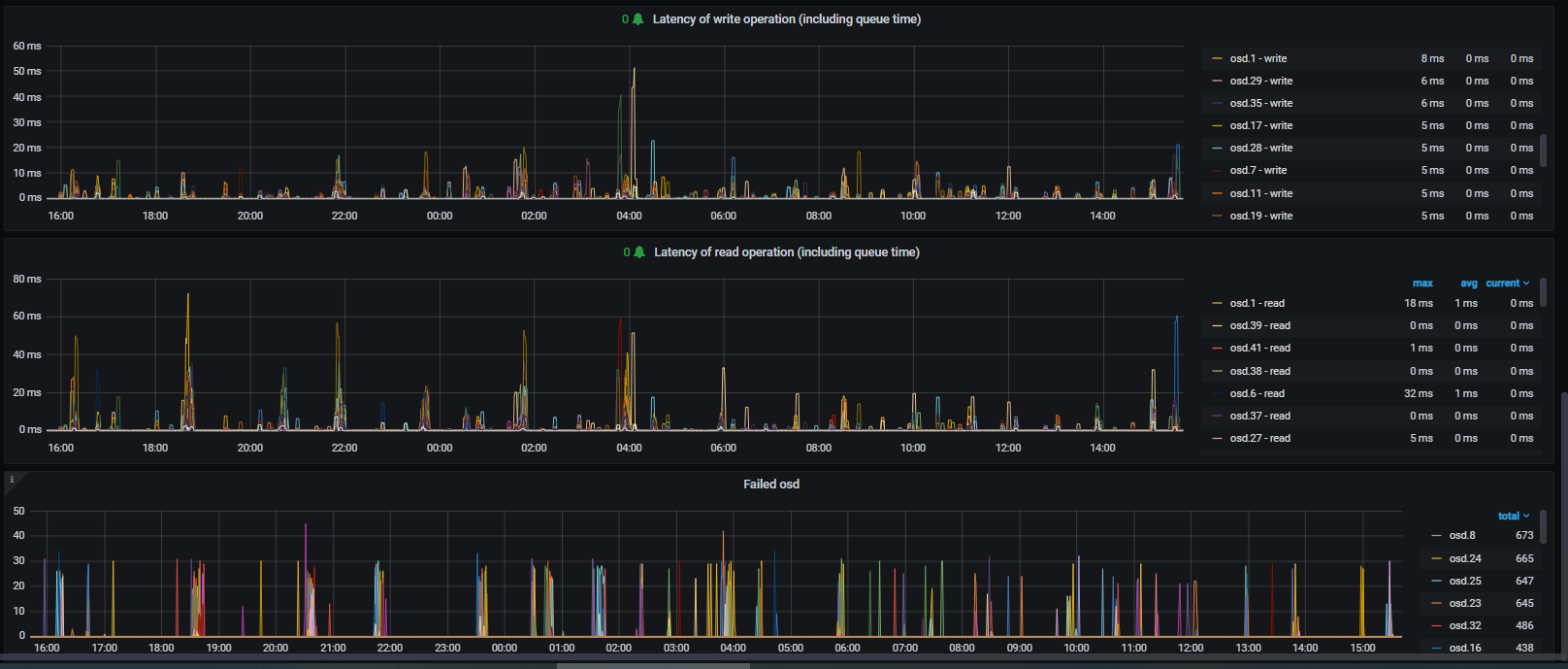
- File lat+failed.PNG lat+failed.PNG added
- File throughput.PNG throughput.PNG added
Neha Ojha wrote:
Set osd_delete_sleep to 2 secs and go higher if this does not help. Setting osd_delete_sleep takes precedence of backend specific variants. Note that increasing this value will make PGs take longer to be deleted but should reduce the overall impact of PG deletion on the other operations.
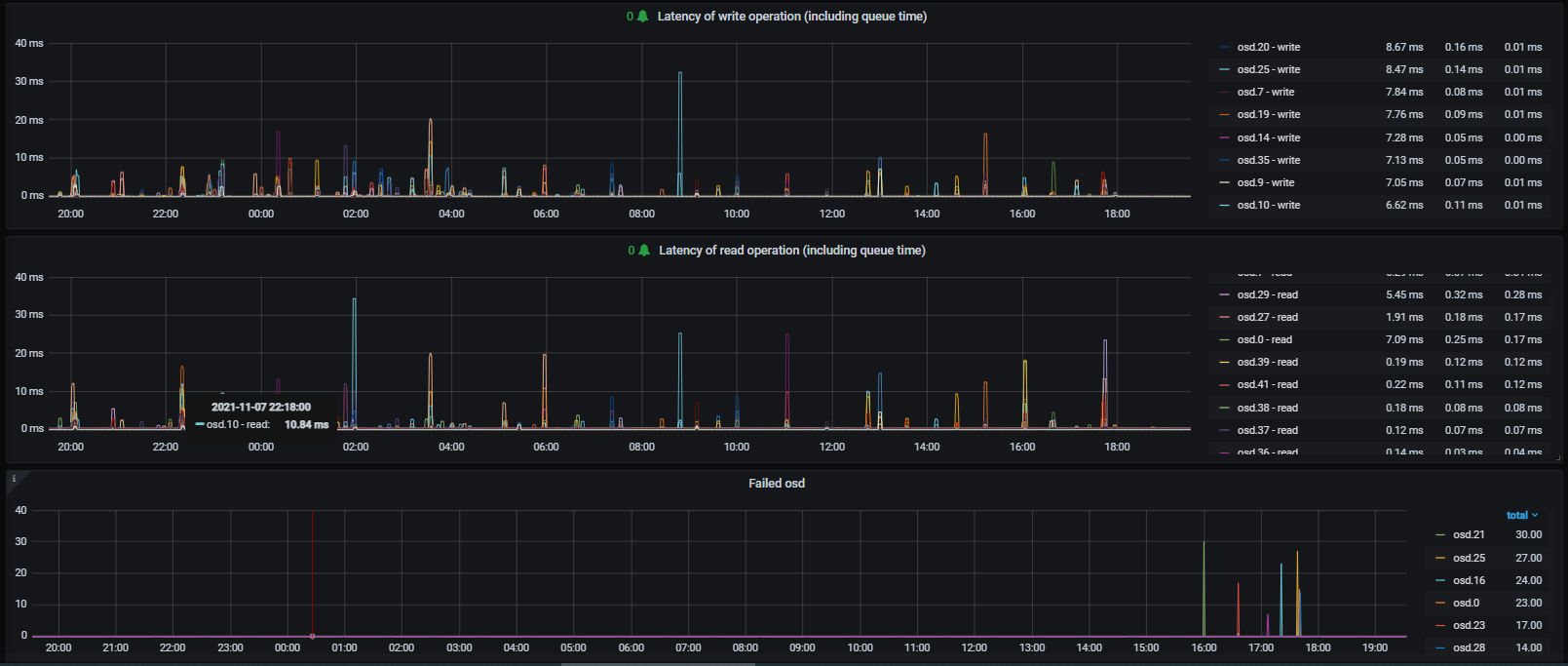
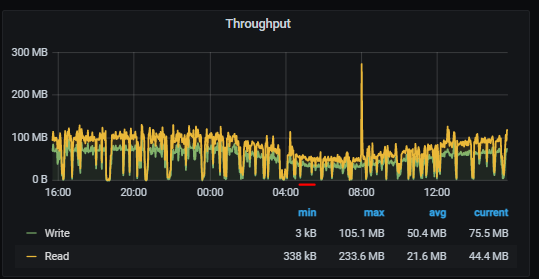
Not sure did it help a lot, I've set these values (runtime) at 4:28am, please have a look my graphs that I've attached.
In the throughput.png you can see the drops, that time slow ops and laggy pgs came.
In the lat+failed.png you can see the latency of read and write and the failed osd is my custom graph of how many time 'reported failed' in the ceph.log which osd.
Also I'm running with this values, does it might be an effect on the 2 sec of the osd_delete_sleep? I'm thinking of the suicide timeout and the op-thread timeout.
I'm running with these values also:
osd_op_thread_suicide_timeout=2000
osd_op_thread_timeout=90
osd_recovery_max_active=3
osd_recovery_op_priority=3 osd_max_backfills=1
osd_max_scrubs=1
osd_scrub_during_recovery true
+
osd_delete_sleep=2
│2'
Updated by Neha Ojha over 2 years ago
Ist Gab wrote:
Neha Ojha wrote:
Set osd_delete_sleep to 2 secs and go higher if this does not help. Setting osd_delete_sleep takes precedence of backend specific variants. Note that increasing this value will make PGs take longer to be deleted but should reduce the overall impact of PG deletion on the other operations.
Not sure did it help a lot, I've set these values (runtime) at 4:28am, please have a look my graphs that I've attached.
In the throughput.png you can see the drops, that time slow ops and laggy pgs came.
In the lat+failed.png you can see the latency of read and write and the failed osd is my custom graph of how many time 'reported failed' in the ceph.log which osd.Also I'm running with this values, does it might be an effect on the 2 sec of the osd_delete_sleep? I'm thinking of the suicide timeout and the op-thread timeout.
There is no harm in keeping osd_delete_sleep=2secs, the laggy piece of this issue looks related to the discussion "[ceph-users] OSD spend too much time on "waiting for readable" -> slow ops -> laggy pg -> rgw stop -> worst case osd restart", there are patches in pipeline based on that discussion.
I'm running with these values also:
osd_op_thread_suicide_timeout=2000
osd_op_thread_timeout=90
osd_recovery_max_active=3
osd_recovery_op_priority=3 osd_max_backfills=1
osd_max_scrubs=1
osd_scrub_during_recovery true
+
osd_delete_sleep=2
│2'
Updated by Igor Fedotov over 2 years ago
In my opinion this issue is caused by a well-known problem with RocksDB performance degradation after bulk data removals. DB becomes irresponsive and suicide timeout fires. One might try DB compaction (preferably offline one) and if issue disappears for a while (it might come back if bulk removals keep going) - that's it.
Updated by Ist Gab over 2 years ago
Igor Fedotov wrote:
In my opinion this issue is caused by a well-known problem with RocksDB performance degradation after bulk data removals. DB becomes irresponsive and suicide timeout fires. One might try DB compaction (preferably offline one) and if issue disappears for a while (it might come back if bulk removals keep going) - that's it.
I have a user who is doing streaming kind of operation for some machine learning stuffs.
They do put/list/head/delete operations continously, but small amount of data. There wasn't a huge amount of remove like a millions of objects.
Most likely this is related to this pg delete/movement things because after the pg increase the cluster became totally unstable.
Updated by Igor Fedotov over 2 years ago
Ist Gab wrote:
Most likely this is related to this pg delete/movement things because after the pg increase the cluster became totally unstable.
Right - PG removal/moving are the primary cause of bulk data removals. We're working on improvements for that, hopefully it would land in Quincy, see https://github.com/ceph/ceph/pull/37496
So if compaction provides some relief (at least temporarily) - I would suggest running periodic compaction using cron job at off-peak hours as a workaround for now. You might try online compaction available through "ceph daemon" first and see how helpful/intrusive it is.
Updated by Ist Gab over 2 years ago
Igor Fedotov wrote:
So if compaction provides some relief (at least temporarily) - I would suggest running periodic compaction using cron job at off-peak hours as a workaround for now. You might try online compaction available through "ceph daemon" first and see how helpful/intrusive it is.
Tried, it finished with OSD crash.
Updated by Ist Gab over 2 years ago
Igor Fedotov wrote:
Right - PG removal/moving are the primary cause of bulk data removals. We're working on improvements for that, hopefully it would land in Quincy, see https://github.com/ceph/ceph/pull/37496
Is there any way to tune this at least temporarily?
I found this value during scanning through the osd options:
osd_pg_delete_priority
Set back to 1, but hasn't really helped :/
Updated by Igor Fedotov over 2 years ago
Ist Gab wrote:
Igor Fedotov wrote:
Right - PG removal/moving are the primary cause of bulk data removals. We're working on improvements for that, hopefully it would land in Quincy, see https://github.com/ceph/ceph/pull/37496
Is there any way to tune this at least temporarily?
I found this value during scanning through the osd options:osd_pg_delete_priority
Set back to 1, but hasn't really helped :/
IIUC this impacts running removal procedure priority but now you have got excessively fragmented DB which causes stalled/slow operations on any (not exactly removal) DB access. So there is no much sense in tuning removal. You need to heal that degraded DB state first. And then proceed with periodic supporting treatment (i.e. compaction).
So if online compaction doesn't work for now - please do offline compaction for every OSD and then try periodic online compactions. Hopefully DB wouldn't degrade that severely if you compact often enough (or due to the lack of frequent bulk removals).
Updated by Ist Gab over 2 years ago
Igor Fedotov wrote:
…
Igor, do you think if we put a super fast 2-4TB write optimized nvme in front of each 15.3TB ssd, would that solve the issue?
Currently if the 15.3TB ssd is around 20-25% full, it holds already almost 1TB metadata.
I’m also testing to put 4osd/ssd and see how it can handle, but I’m curious which one is better?
Updated by Igor Fedotov over 2 years ago
Ist Gab wrote:
Igor Fedotov wrote:
…
Igor, do you think if we put a super fast 2-4TB write optimized nvme in front of each 15.3TB ssd, would that solve the issue?
Currently if the 15.3TB ssd is around 20-25% full, it holds already almost 1TB metadata.
I’m also testing to put 4osd/ssd and see how it can handle, but I’m curious which one is better?
I doubt anyone can say what setup would be good for you without experiments in the field. Me neither. Definitely having faster drives would be better but your metadata/data ratio is very high (roughly 1:4 if my math is correct). This is quite different from the regular Ceph use cases I'm aware of. So I believe only experiments in the field can say the truth.
Updated by Ist Gab about 2 years ago
Igor Fedotov wrote:
I doubt anyone can say what setup would be good for you without experiments in the field. Me neither. Definitely having faster drives would be better but your metadata/data ratio is very high (roughly 1:4 if my math is correct). This is quite different from the regular Ceph use cases I'm aware of. So I believe only experiments in the field can say the truth.
Hello,
The only way how I made it work so far:
- 4 osd/15.3 TB SSD
- don't use separate nvme for wal+rocksdb
- don't use pg_autoscaler suggestion, preallocate all the placement group that can be in y cluster