Actions
Bug #53128
closedFeature #47072: mgr/dashboard: Usability Improvements
Tasks #50335: mgr/dashboard: Workflows
Feature #50336: mgr/dashboard: "Create Cluster" workflow
mgr/dashboard: Cluster Expansion - Review Section: fixes and improvements
Status:
Resolved
Priority:
Normal
Assignee:
-
Category:
Component - Orchestrator
Target version:
% Done:
0%
Source:
Tags:
Backport:
pacific
Regression:
No
Severity:
3 - minor
Reviewed:
Description
Paul Cuzner has reported the following issues:
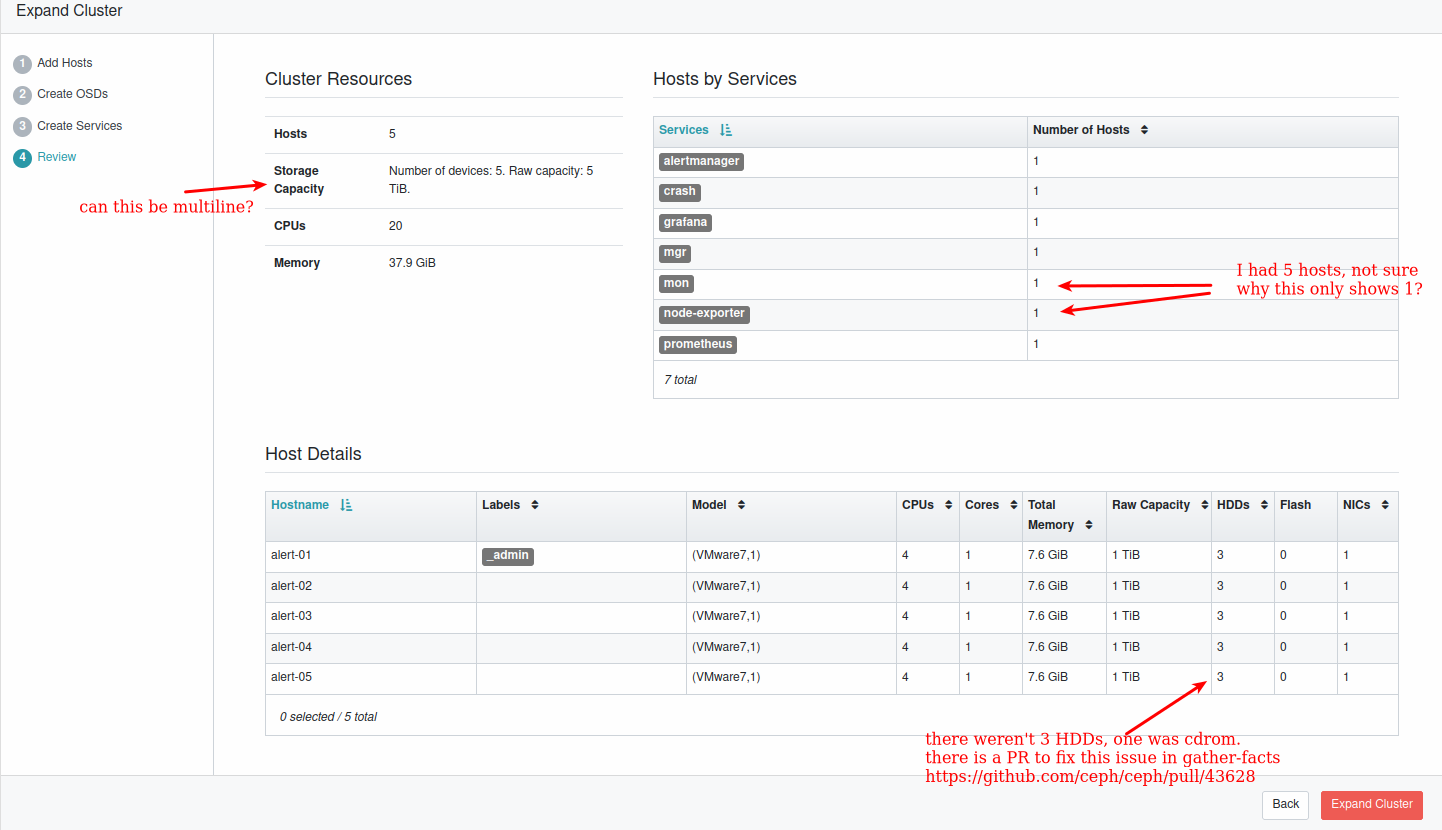
- Ensure "Storage capacity" keeps the "Description : Value" approach ("Number of devices: X" and "Raw Capacity: Y" in different lines).
- Check issue with "host by services" host count
- Exclude non-HDDs (cdrom) from the HDD count. This should be automatically fixed by: https://github.com/ceph/ceph/pull/43628.
Files
Updated by Avan Thakkar over 2 years ago
I think for the `Host by Services` issue the reason maybe that the daemons are not yet fetched for hosts other than default one. We need more info here to check if hosts services are fetched or not, so maybe attaching a screenshot for host list page will do to verify that.
Updated by Avan Thakkar over 2 years ago
- Status changed from New to Need More Info
Updated by Ernesto Puerta over 2 years ago
Discussed in today's stand-up:
- Planning to refactor this from "host count by service" to "instances by service": as, for example, you may want to deploy multiple instances on the a service in the same host (e.g.: OSDs or RGWs).
- Additionally, we should support deployment by pattern-matching (or at least support the `*`/ALL placement)
- We should display this information as provided by Cephadm (single source of truth, rather than calculating this ourselves). However, as long as the `_no_schedule` label is used to defer deployment, not even the `--dry-run` will return a valid count, so we could add a new --force (or --ignore-no-schedule) flag to deal with this. TBD with Cephadm folks.
Updated by Ernesto Puerta over 2 years ago
- Status changed from Need More Info to Pending Backport
Updated by Backport Bot over 2 years ago
- Copied to Backport #53689: pacific: mgr/dashboard: Cluster Expansion - Review Section: fixes and improvements added
Updated by Loïc Dachary over 2 years ago
- Status changed from Pending Backport to Resolved
While running with --resolve-parent, the script "backport-create-issue" noticed that all backports of this issue are in status "Resolved" or "Rejected".
Actions