Bug #52915
closedrbd du versus rbd diff values wildly different when snapshots are present
0%
Description
root@ virtual335:~# ceph -v
ceph version 15.2.14 (e3964f3ac2e00e5baacdec60b36e45d1c2e8571b) octopus (stable)
I am trying to understand the values given by the du command for RBD images. They seem to have no basis in reality when snapshots are present. These are also the values shown on the "total provisioned" column of the RBD dashboard, so the stats given on that page are greatly overstated. Any GUI tools that are relying on rbd du I also believe to be wrong when snapshots are present.
Consider a 70 GiB disk attached to a VM that is always powered off. All of our VMs are snapped twice per day for 3 days and there is a rolling snapshot used for diff exports. This VM is always off, so there are always exactly zero writes occurring here.
root@virtual335:~# rbd du CephRBD_NVMe/vm-9994-disk-0
NAME PROVISIONED USED
vm-9994-disk-0@AutoSnap_10_09_2021_05_10_05 70 GiB 24 GiB
vm-9994-disk-0@AutoSnap_10_09_2021_19_07_45 70 GiB 24 GiB
vm-9994-disk-0@AutoSnap_10_10_2021_05_06_27 70 GiB 0 B
vm-9994-disk-0@AutoSnap_10_10_2021_19_08_09 70 GiB 0 B
vm-9994-disk-0@AutoSnap_10_11_2021_05_06_39 70 GiB 0 B
vm-9994-disk-0@AutoSnap_10_11_2021_19_05_01 70 GiB 0 B
vm-9994-disk-0@barcdaily20211012020457 70 GiB 0 B
vm-9994-disk-0@AutoSnap_10_12_2021_05_04_51 70 GiB 0 B
vm-9994-disk-0 70 GiB 0 B
<TOTAL> 70 GiB 47 GiB
Here, I would expect the parent disk, "vm-9994-disk-0," to show 24 GiB used, and all of the snapshots should show 0 bytes because that is the amount of writes that occurred on them. For the 2 oldest snaps to report the same value is nonsensical to me given that the VM is known to be off. There is no way 24 GiB of writes occurred in either of those snapshots. Of course the total on the bottom row should also display 24 GiB, not 47.
The total usage as calculated by rbd diff gives the precise and expected answer, 21.89 GiB:
root@ virtual335 :/# rbd diff CephRBD_NVMe/vm-9994-disk-0 | awk '{ SUM += $2 } END { print SUM/1024/1024/1024 }'
21.8914
After an rbd snap purge, the rbd du output returns to what is reasonable and expected:
root@ virtual335 :~# rbd du CephRBD_NVMe/vm-9994-disk-0
NAME PROVISIONED USED
vm-9994-disk-0 70 GiB 24 GiB
Because all of the snapshots were truly 0 bytes, running rbd diff after the snap purge gives the same exact value as before:
root@ virtual335 :/# rbd diff CephRBD_NVMe/vm-9994-disk-0 | awk '{ SUM += $2 } END { print SUM/1024/1024/1024 }'
21.8914
Now let me show you a disk attached to a VM that is always powered on. It is provisioned at 100 GiB. The total storage usage as reported by the guest file system is 41 GiB. The average write load is known to be around 6 GiB per day.
root@virtual335:/# rbd du CephRBD_NVMe/vm-101-disk-0
NAME PROVISIONED USED
vm-101-disk-0@AutoSnap_10_09_2021_05_02_06 100 GiB 70 GiB
vm-101-disk-0@AutoSnap_10_09_2021_19_03_05 100 GiB 70 GiB
vm-101-disk-0@AutoSnap_10_10_2021_05_02_24 100 GiB 10 GiB
vm-101-disk-0@AutoSnap_10_10_2021_19_03_25 100 GiB 11 GiB
vm-101-disk-0@AutoSnap_10_11_2021_05_02_26 100 GiB 12 GiB
vm-101-disk-0@AutoSnap_10_11_2021_19_02_27 100 GiB 19 GiB
vm-101-disk-0@barcdaily20211012020151 100 GiB 19 GiB
vm-101-disk-0@AutoSnap_10_12_2021_05_02_04 100 GiB 9.9 GiB
vm-101-disk-0 100 GiB 13 GiB
<TOTAL> 100 GiB 233 GiB
Same as in the first example, the 2 oldest snapshots have duplicate values while the parent disk shows an impossibly small value. I would expect the parent disk, "vm-9994-disk-0," to show something between 45 and 50 GiB. The sizes that du reports for the snapshots suggest a write load of 20-40 GiB per day. I have no idea where these values could be coming from, I cannot associate them with anything known to be occurring in the guest VM.
The total usage as calculated by rbd diff gives a much more reasonable answer, 68.39 GiB:
root@ virtual335 :/# rbd diff CephRBD_NVMe/vm-101-disk-0 | awk '{ SUM += $2 } END { print SUM/1024/1024/1024 }'
68.3906
Why does the du total show 233 GiB when rbd diff says 68.39 GiB?
After an rbd snap purge, the rbd du output returns something reasonable and expected for this VM:
root@ virtual335 :~# rbd du CephRBD_NVMe/vm-101-disk-0
NAME PROVISIONED USED
vm-101-disk-0 100 GiB 50 GiB
After the snap purge, calculating the usage on this disk again with rbd diff gives the correct answer, 48 GiB:
root@ virtual335 :~# rbd diff CephRBD_NVMe/vm-101-disk-0 | awk '{ SUM += $2 } END { print SUM/1024/1024/1024 }'
48.0205
(68.3906 - 48.0205) / 3 = 6.79 GiB per day in writes on this VM, which we know to be correct.
Not to belabor it but I will just quickly show one more VM to illustrate how the wild values get out of control:
root@virtual335:~# rbd du CephRBD_NVMe/vm-112-disk-0
NAME PROVISIONED USED
vm-112-disk-0@AutoSnap_10_09_2021_05_01_56 701 GiB 577 GiB
vm-112-disk-0@AutoSnap_10_09_2021_19_01_52 701 GiB 577 GiB
vm-112-disk-0@AutoSnap_10_10_2021_05_02_15 701 GiB 73 GiB
vm-112-disk-0@AutoSnap_10_10_2021_19_02_57 701 GiB 118 GiB
vm-112-disk-0@AutoSnap_10_11_2021_05_01_18 701 GiB 116 GiB
vm-112-disk-0@AutoSnap_10_11_2021_19_02_15 701 GiB 73 GiB
vm-112-disk-0@barcdaily20211012020059 701 GiB 76 GiB
vm-112-disk-0@AutoSnap_10_12_2021_05_01_18 701 GiB 62 GiB
vm-112-disk-0 701 GiB 81 GiB
<TOTAL> 701 GiB 1.7 TiB
This disk is 701 GiB with 469 GiB in use by the guest file system. Like the 2 examples before, the 2 oldest snaps have suspiciously duplicated size values. Like before, the parent disk (essentially the 0th snap) shows an impossibly small value of 81 GiB.
root@virtual335:~# rbd diff CephRBD_NVMe/vm-112-disk-0 | awk '{ SUM += $2 } END { print SUM/1024/1024/1024 }'
569.157
And rbd diff calculates 569 GiB in total usage, not 1.7 TiB. I think these wild values also throw off the displayed total usage on RBD pools.
So I either completely misunderstand the purpose of rbd du, or there is a bug to do with calculating usage on snaps. I need a quick, reliable, and precise way to get the size of a specific disk, specific snapshot, or the entire chain. I could create something myself but I wanted to report this so others can verify. While rbd diff is always very precise, we have hundreds of other disks, a lot larger than the examples given here, and rbd diff is an expensive calculation to run in bulk.
Files
{kind=link}
Updated by Sebastian Wagner over 2 years ago
- Project changed from Ceph to rbd
- Category deleted (
ceph cli)
Updated by Christopher Hoffman about 2 years ago
This issue has been addressed in v15.2.16 of Octupus.
From the change log notes there's this patch: "librbd/object_map: rbd diff between two snapshots lists entire image content (pr#43806, Sunny Kumar)". This patch adds checking for "m_object_diff_state_valid" which will exclude invalid values that were previously counted.
Full change log:
https://docs.ceph.com/en/latest/releases/octopus/#v15-2-16-octopus
Updated by Christopher Hoffman about 2 years ago
- Related to Bug #54440: Create test case to verify values of snaps in rbd du added
Updated by Christopher Hoffman about 2 years ago
- Status changed from New to In Progress
- Assignee set to Christopher Hoffman
Updated by Ilya Dryomov about 2 years ago
- Is duplicate of Bug #50787: rbd diff between two snapshots lists entire image content with 'whole-object' switch added
Updated by Ilya Dryomov about 2 years ago
- Status changed from In Progress to Duplicate
Updated by Alex Yarbrough over 1 year ago
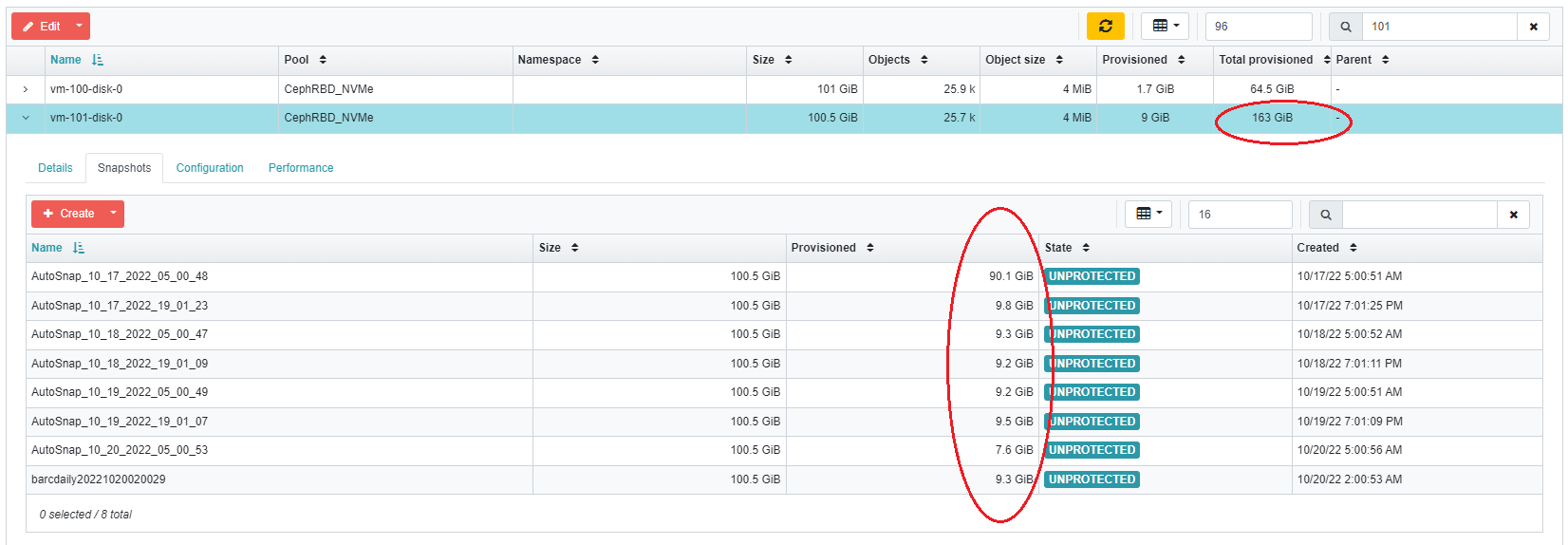
- File screenshot.png screenshot.png added
Greetings all. I have read through the related issues that are resolved. I do not believe this issue is duplicated or related to any of them, and the problem is still present in Quincy. rbd du is not accurate.
root@virtual331:~# ceph -v ceph version 17.2.1 (2508b9f16ef63944cb33be33a271b10931071205) quincy (stable)
Sample VM with 57 GiB in use by the guest file system, 8 GiB in writes per day:
root@virtual331:~# rbd du CephRBD_NVMe/vm-101-disk-0 NAME PROVISIONED USED vm-101-disk-0@AutoSnap_10_17_2022_05_00_48 100 GiB 90 GiB vm-101-disk-0@AutoSnap_10_17_2022_19_01_23 100 GiB 9.8 GiB vm-101-disk-0@AutoSnap_10_18_2022_05_00_47 100 GiB 9.3 GiB vm-101-disk-0@AutoSnap_10_18_2022_19_01_09 100 GiB 9.2 GiB vm-101-disk-0@AutoSnap_10_19_2022_05_00_49 100 GiB 9.2 GiB vm-101-disk-0@AutoSnap_10_19_2022_19_01_07 100 GiB 9.5 GiB vm-101-disk-0@barcdaily20221020020029 100 GiB 9.3 GiB vm-101-disk-0@AutoSnap_10_20_2022_05_00_53 100 GiB 7.6 GiB vm-101-disk-0 100 GiB 9.0 GiB <TOTAL> 100 GiB 163 GiB
Total of 163 GiB given by rbd du is not possible. These are also the numbers shown on the snapshot table in the ceph mgr dashboard, and not correct.
root@virtual331:~# rbd diff CephRBD_NVMe/vm-101-disk-0 | awk '{ SUM += $2 } END { print SUM/1024/1024/1024 }'
87.0058
Total of 87 GiB given by rbd diff is 100% accurate, but took nearly 20 seconds to calculate for 1 disk!
It would be wonderful for rbd du and the dashboard to have the correct values. Thank you so much.
Updated by Ilya Dryomov over 1 year ago
Hi Alex,
"rbd diff CephRBD_NVMe/vm-101-disk-0" reports the allocated areas of the image without taking snapshots into account, whereas "rbd du CephRBD_NVMe/vm-101-disk-0" attempts to report the amount of space used by the image including all its snapshots. Neither "rbd diff" nor "rbd du" are exact -- extent boundaries are rounded to the RBD object boundaries in most cases.
For example, here is a 1G image with 100M written at the beginning of the image:
$ rbd du testimage
NAME PROVISIONED USED
testimage 1 GiB 100 MiB
$ rbd diff testimage | awk '{ SUM += $2 } END { print SUM/1024/1024 }'
100
Now, I take a snapshot:
$ rbd du testimage
NAME PROVISIONED USED
testimage@snap1 1 GiB 100 MiB
testimage 1 GiB 0 B
<TOTAL> 1 GiB 100 MiB
$ rbd diff testimage | awk '{ SUM += $2 } END { print SUM/1024/1024 }'
100
... and write 50M at the beginning of the image (thus overwriting 50M of those 100M in the snapshot):
$ rbd du testimage
NAME PROVISIONED USED
testimage@snap1 1 GiB 100 MiB
testimage 1 GiB 52 MiB
<TOTAL> 1 GiB 152 MiB
$ rbd diff testimage | awk '{ SUM += $2 } END { print SUM/1024/1024 }'
100
The total amount of space used by the image is now 150M, "rbd du" estimates it to be 152M. Note that "rbd diff"-based summation still reports 100M because 0..100M is the only allocated area. To change that, let's write 10M at the end of the image:
$ rbd du testimage
NAME PROVISIONED USED
testimage@snap1 1 GiB 100 MiB
testimage 1 GiB 64 MiB
<TOTAL> 1 GiB 164 MiB
$ rbd diff testimage | awk '{ SUM += $2 } END { print SUM/1024/1024
}'
112
The total amount of space used by the image is now 160M (110M + 50M for the snapshot delta), "rbd du" estimates it to be 164M. "rbd diff"-based summation went from 100M to 112M -- it can't "see" into the RBD object in this case so it can't report the exact 110M.
Hopefully this helps to understand that "rbd du" total for the image can be orders of magnitude bigger than "rbd diff"-based total. These are two different values, there is almost no connection between them.
Updated by Ilya Dryomov over 1 year ago
Going back to CephRBD_NVMe/vm-101-disk-0 image, your "rbd du" output makes perfect sense to me based on what you said:
- 8 GiB in writes per day
- total of 87 GiB given by rbd diff is 100% accurate
root@virtual331:~# rbd du CephRBD_NVMe/vm-101-disk-0
NAME PROVISIONED USED
vm-101-disk-0@AutoSnap_10_17_2022_05_00_48 100 GiB 90 GiB
This is the initial snapshot with the entire filesystem (~87G) in it.
vm-101-disk-0@AutoSnap_10_17_2022_19_01_23 100 GiB 9.8 GiB
vm-101-disk-0@AutoSnap_10_18_2022_05_00_47 100 GiB 9.3 GiB
vm-101-disk-0@AutoSnap_10_18_2022_19_01_09 100 GiB 9.2 GiB
vm-101-disk-0@AutoSnap_10_19_2022_05_00_49 100 GiB 9.2 GiB
vm-101-disk-0@AutoSnap_10_19_2022_19_01_07 100 GiB 9.5 GiB
vm-101-disk-0@barcdaily20221020020029 100 GiB 9.3 GiB
vm-101-disk-0@AutoSnap_10_20_2022_05_00_53 100 GiB 7.6 GiB
These are the snapshot deltas, given that snapshots are taken on a schedule and the change rate is constant they are roughly equal in size.
vm-101-disk-0 100 GiB 9.0 GiB
This is the most recent delta which is about to be snapshotted. The size matches.
<TOTAL> 100 GiB 163 GiB
And this is the total amount of space used by the image. Again, keep in mind that all USED values are estimates -- in the worst case a 512-byte write can be accounted as a 4M write (default RBD object size).
Updated by Alex Yarbrough over 1 year ago
Ilya, first thank you for the time you put into your messages. I am aware of the issue regarding RBD object size versus guest file system object size and its effects on usage reporting.
FYI the AutoSnap runs twice per day, and the actual 8 GiB per day in writes is known empirically via the guest OS. Going by the values given by du, it suggests nearly 20 GiB per day in writes which I find to be too high, and is what originally caught my attention, but you say the snaps likely contain mostly small writes, inflating the du value. That is easy to understand.
If I rbd du all of the ~200 images that I have, and sum the result, my total is about 24 TiB (or 72 raw TiB after 3x replication).
If I rbd diff all of my images, and sum that result, the total is only 14 TiB (or 42 raw TiB after 3x replication).
The usage on the pool reported by ceph df is 44 TiB, which is reasonably close to the replication-adjusted rbd diff total of 42 TiB.
PS /root> ceph df --- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED ssd 95 TiB 50 TiB 44 TiB 44 TiB 46.70 TOTAL 95 TiB 50 TiB 44 TiB 44 TiB 46.70 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL CephRBD_NVMe 3 128 24 TiB 6.80M 44 TiB 59.31 10 TiB
If I could ask my question in a different way, since rbd diff seems to be the more accurate and more valuable number and has a stronger correlation to ceph df, and real-world usage, why is rbd du the preferred value on the dashboard?
Thank you again
Updated by Ilya Dryomov over 1 year ago
Alex Yarbrough wrote:
If I rbd du all of the ~200 images that I have, and sum the result, my total is about 24 TiB (or 72 raw TiB after 3x replication).
There should be no need to do that manually, just run "rbd du" with no arguments and grab <TOTAL> values at the bottom.
If I rbd diff all of my images, and sum that result, the total is only 14 TiB (or 42 raw TiB after 3x replication).
The usage on the pool reported by ceph df is 44 TiB, which is reasonably close to the replication-adjusted rbd diff total of 42 TiB.
I think this is just a coincidence.
> --- POOLS --- > POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL > CephRBD_NVMe 3 128 24 TiB 6.80M 44 TiB 59.31 10 TiB
... 24T in STORED seems to align with your "rbd du" total?
If I could ask my question in a different way, since rbd diff seems to be the more accurate and more valuable number and has a stronger correlation to ceph df, and real-world usage, why is rbd du the preferred value on the dashboard?
Again, "rbd diff"-based summation isn't more accurate -- it's a completely different metric. Consider a workload that overwrites the entire RBD image in the course of a day and a daily snapshot schedule. Assuming all snapshots are retained, after 30 days, the total amount of space used by the RBD image would be 30 * image_size (without taking replication into account). However, "rbd diff"-based summation would still report 1 * `image_size' -- 30 times far from accurate...