Bug #51083
openRaw space filling up faster than used space
0%
Description
We're seeing something strange currently. Our cluster is filling up faster than it should, and I assume it has something to do with the upgrade from Nautilus to Pacific.
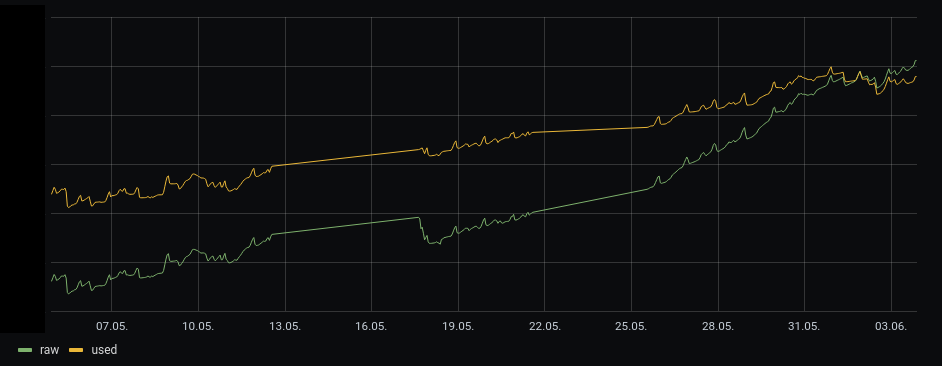
Attached is a graph of .pgmap.data_bytes (yellow) and .pgmap.bytes_used (green), the latter multiplied by 3 because most pools have size=3 (some have size=2) over the last 30 days. As you can see, the raw capacity is increasing significantly faster than the "real", used capacity.
Most of the "real" increase is in CephFS, and we haven't upgraded the MDS yet. Maybe that matters.
How can I find out where the capacity is vanishing?
Files
{kind=link}
{kind=link}
{kind=link}
Updated by Jan-Philipp Litza almost 3 years ago
- File wasted space.png wasted space.png added
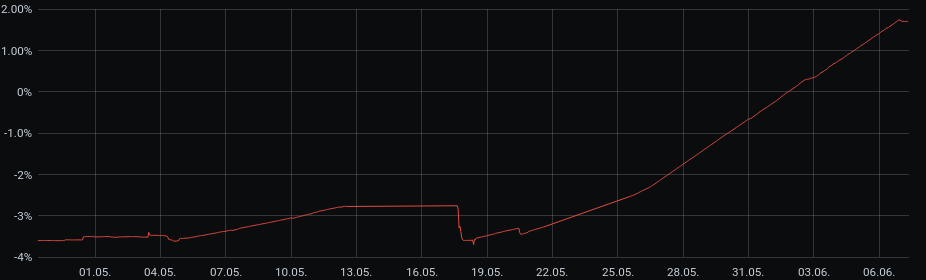
Yesterday evening we finally managed to upgrade the MDS daemons as well, and that seems to have stopped the space waste. Attached is a graph of $bytes_used - 3*$data_bytes (in percentage of total cluster capacity), which should be <=0 in our cluster (due to size<=3) but surpassed that threshold on 2021-06-02. After the upgrade yesterday, the quite steady increase stopped abruptly.
Also, the increase started quite precisely the day we started upgrading OSDs (2021-05-04) and accelerated the more OSDs were upgraded. I have no idea what we did to make it dip around 2021-05-18, but it sure would be nice to reclaim these 6% of our total storage capacity. Can a cephfs scrub help with that?
Updated by Neha Ojha almost 3 years ago
- Project changed from RADOS to CephFS
Patrick: do you understand how upgrading the MDS daemons helped in this case? There is nothing in the osd/bluestore side that would attribute to this. Also, could please answer https://tracker.ceph.com/issues/51083#note-2, feel to move it back to RADOS after that.
Updated by Patrick Donnelly almost 3 years ago
Jan-Philipp Litza wrote:
Yesterday evening we finally managed to upgrade the MDS daemons as well, and that seems to have stopped the space waste. Attached is a graph of
$bytes_used - 3*$data_bytes(in percentage of total cluster capacity), which should be <=0 in our cluster (due to size<=3) but surpassed that threshold on 2021-06-02. After the upgrade yesterday, the quite steady increase stopped abruptly.Also, the increase started quite precisely the day we started upgrading OSDs (2021-05-04) and accelerated the more OSDs were upgraded. I have no idea what we did to make it dip around 2021-05-18, but it sure would be nice to reclaim these 6% of our total storage capacity. Can a cephfs scrub help with that?
Scrub is unlikely to help. Can you share the following:
ceph df
ceph status
ceph osd dump
ceph tell mds.<fsname>:0 perf dump
I don't have an idea why the space usage would stop with the upgrade.
Updated by Jan-Philipp Litza almost 3 years ago
- File ceph_osd_dump.out ceph_osd_dump.out added
- File ceph_mds_perf_dump.out ceph_mds_perf_dump.out added
- File ceph_df.out ceph_df.out added
- File ceph_status.out ceph_status.out added
Patrick Donnelly wrote:
Scrub is unlikely to help.
I came to the same conclusion after reading the documentation, but it was the only CephFS-related "cleanup" I could find.
Can you share the following:
ceph df
ceph status
ceph osd dump
ceph tell mds.<fsname>:0 perf dump
Attached.
Let me add that I wasn't able to attribute the increase to any specific pool. I think you can even see it in the output of ceph df (although I cheated by using the JSON format):
$ ceph df -f json | jq '.stats.total_used_bytes - (.pools | map(.stats.bytes_used) | add)' 33322936487494 (=30.3 TiB)
To my understanding, this should be 0. If so, this indeed seems to be an issue with RADOS that was triggered by CephFS.
Updated by Patrick Donnelly almost 3 years ago
- Project changed from CephFS to RADOS
I don't have any ideas from the logs. Moving this back to RADOS. I doubt it has anything to do with CephFS.
Updated by Jan-Philipp Litza almost 3 years ago
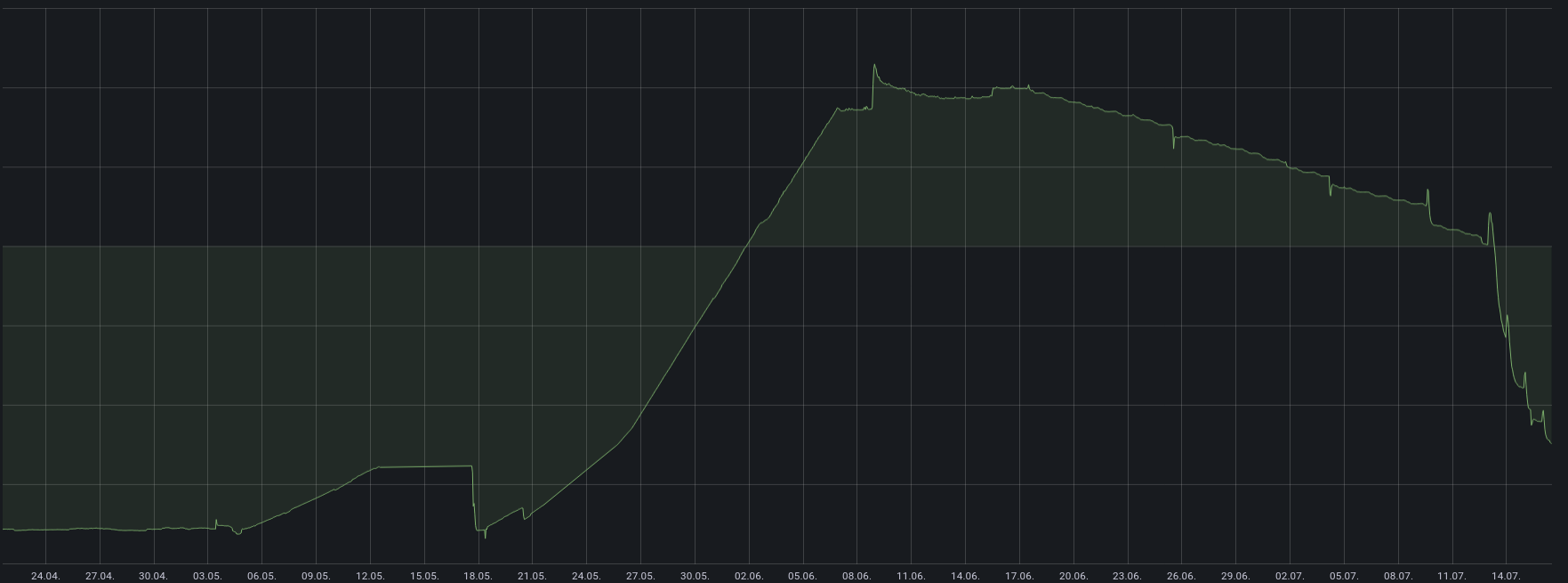
So apparently "arbitrary" changes to the CRUSH map are able to free up the space again:
A few days ago, we activated the balancer module. Each optimization run gradually freed up part of the wasted space, and we already reclaimed almost all of it by now.
In the attached graph, you can see that some space also got reclaimed quite steadily over the last weeks, but not nearly as fast as the balancer did it. And it happened so continuously that I doubt it was caused by any other changes we did to the cluster during the time.
I guess it will remain a mystery, what caused this phenomenon, but I'm glad we have that space back.
Updated by Neha Ojha over 2 years ago
- Status changed from New to Need More Info
Moving to need more info, please let us know if it happens again.