Bug #48452
openpg merge explodes osdmap mempool size
0%
Description
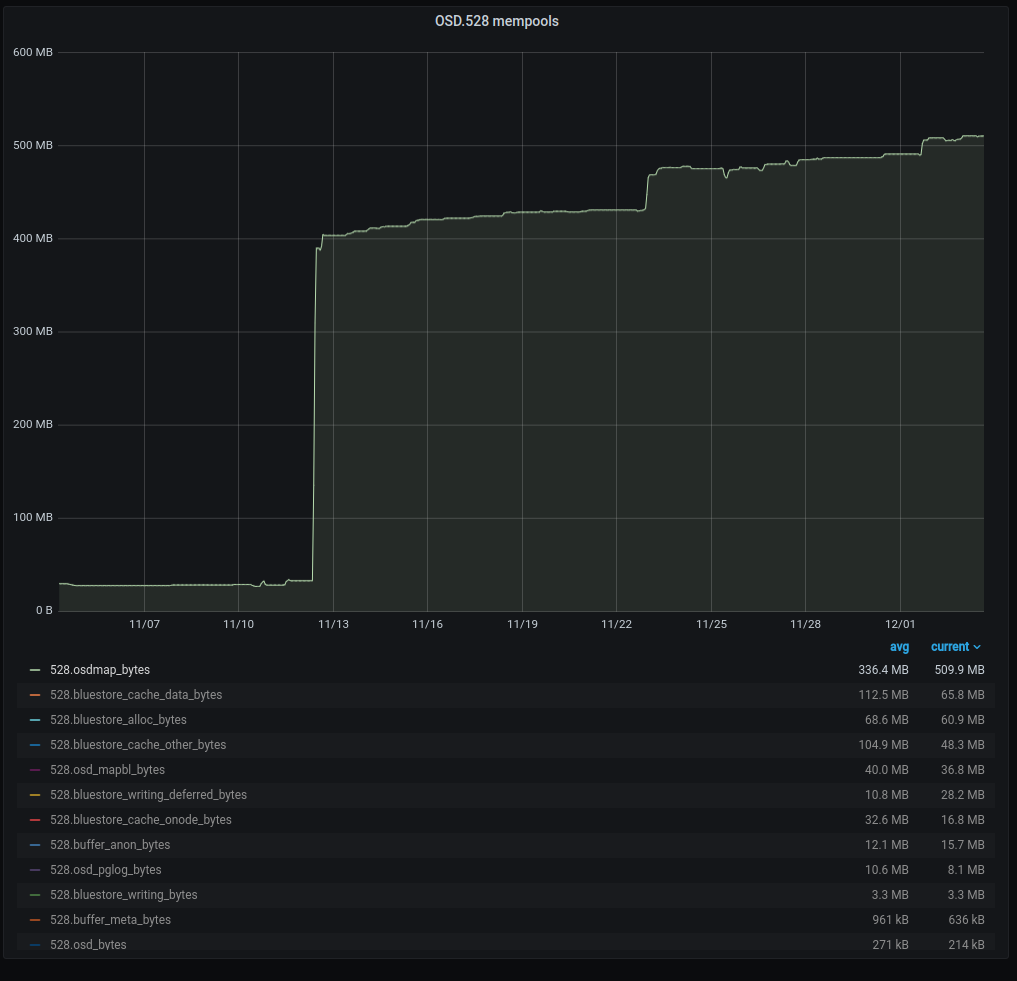
We have one cluster with several osds having >500MB osdmap mempools.
Here is one example from today:
"osdmap": {
"items": 20479405,
"bytes": 510621880
},
The osd is correctly trimming osdmaps; it keeps less than 1k maps:
# ceph daemon osd.528 status
{
"cluster_fsid": "03dfe28e-ecb1-4d03-b7d7-aac8e172319e",
"osd_fsid": "84af8d8e-3d63-4ab2-ab0c-1ddfb0c1656e",
"whoami": 528,
"state": "active",
"oldest_map": 200260,
"newest_map": 201001,
"num_pgs": 18
}
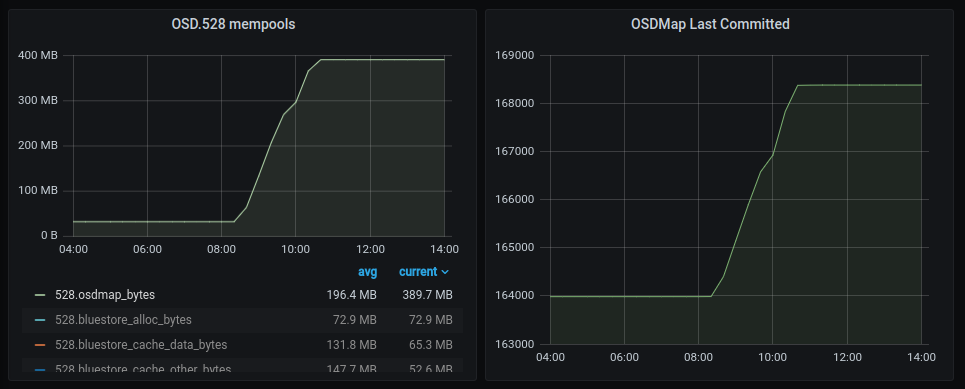
I traced the mempool usage back in our monitoring and found it started growing on Nov 12. See the attached plot of osdmap mempool bytes and osdmap last committed on Nov 12.
I have sent the ceph log and ceph.audit.log from that day.
ceph-post-file: 5b4985c0-8126-4da9-9d16-b2c336d826aa
ceph-post-file: c86c8952-5748-4d51-97e7-4bea604670e8
You will see that around 08:37 am we started decreasing pg_num for the default.rgw.users.swift pool. The merging took until 10:38, when the osdmaps stopped churning and mempool stopped growing.
But for the next two weeks (until I noticed today) the mempool kept growing. (see attached chart from today)
Seems there is a leaked ref to the osdmap in pg merging.
(P.S. in the audit log you will see that moments before we started the pg merging, we set some nodelete, etc flags on some pools; this may also be the root cause but I was thinking that pg merging is more likely.)
Files
{kind=link}
{kind=link}