Bug #48298
openhitting mon_max_pg_per_osd right after creating OSD, then decreases slowly
0%
Description
I just added OSDs to my cluster running 14.2.13.
mon_max_pg_per_osd = 300 osd_max_pg_per_osd_hard_ratio = 3
OSDs of comparable size have maybe 200 PGs on them.
This OSD now somehow has 907 > 300*3 PGs:
ceph daemon osd.422 status
{
"cluster_fsid": "xxx",
"osd_fsid": "yyy",
"whoami": 422,
"state": "booting",
"oldest_map": 454592,
"newest_map": 455185,
"num_pgs": 907
}
Thus PGs become stuck activating+remapped and the large parts of the cluster die.
The interesting thing is this: Now after I've increased the limit, it does of course boot and PGs become active.
Now, but the num_pgs have increased further to 969. But then they started to decrease, until the device has the expected number of PGs!
Another problem: There's absolutely no hint that the osd_max_pg_per_osd_hard_ratio has hit. You only get the warning when being over the soft limit.
tl;dr:
- More PGs are allocated on an OSD than there actually are once the remapping is done.
- There's no cluster error when a OSD does hit the hard limit.
Files
{kind=link}
Updated by Jonas Jelten over 3 years ago
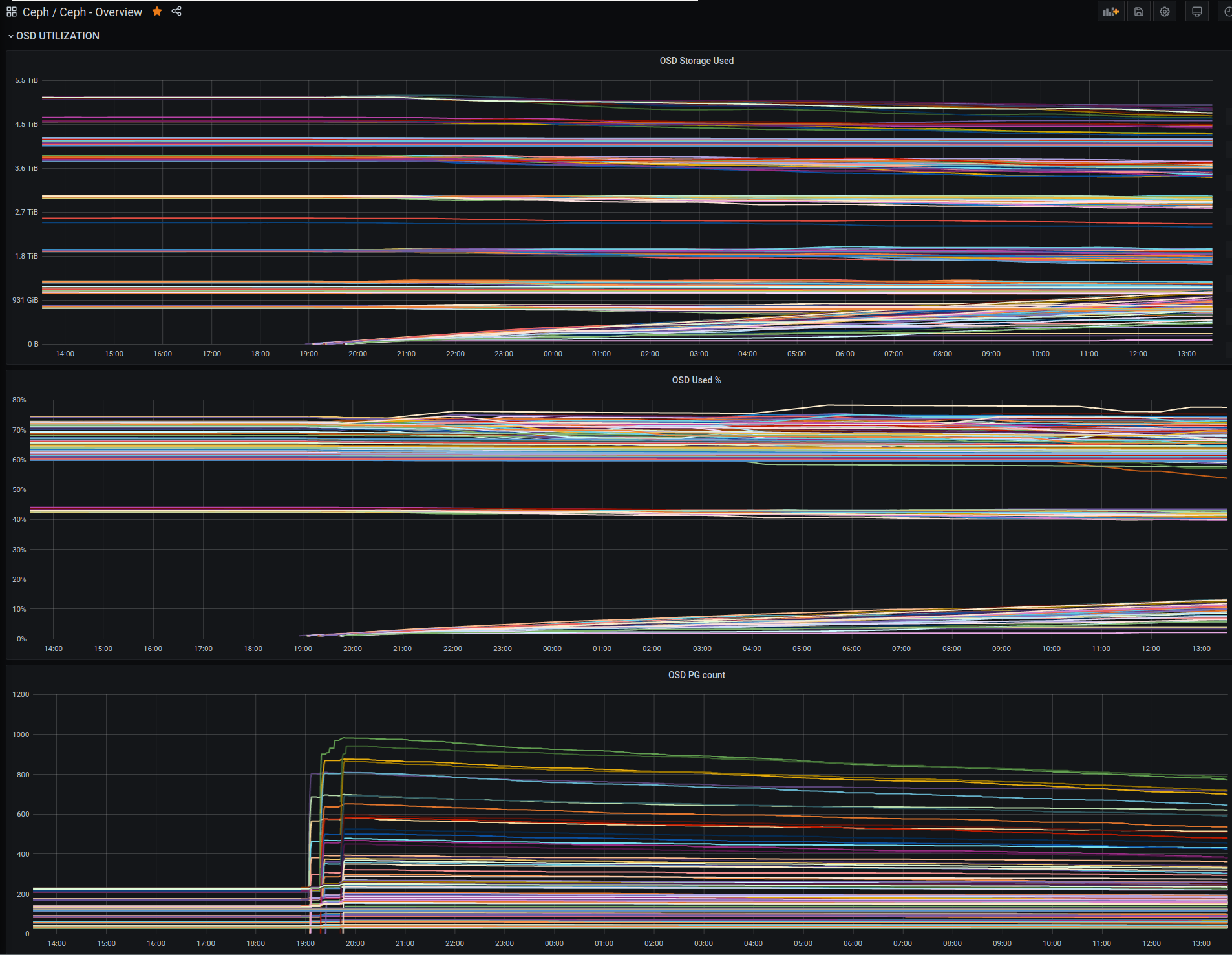
Another observation: The num_pgs is the highest if it was created first on the same host. Later-created devices (higher osdid) have lower num_pgs, but all the OSDs on this host are 9TiB devices.
osdid ceph-daemon status 437: "num_pgs": 941 438: "num_pgs": 863 439: "num_pgs": 692 440: "num_pgs": 595 441: "num_pgs": 524 442: "num_pgs": 448 443: "num_pgs": 385 444: "num_pgs": 367 445: "num_pgs": 348 446: "num_pgs": 267 447: "num_pgs": 286 448: "num_pgs": 233 449: "num_pgs": 228 450: "num_pgs": 186 451: "num_pgs": 136
All those OSDs were added within 10 minutes and have equal size and there's no special CRUSH rules (just host failure domain). Thus they all should have roughly an equal number of allocated PGs.
Updated by Jonas Jelten over 3 years ago
Now, about 18 hours later, the num_pg already has dropped quite a bit. These are the exact same OSDs. The balancer is/was off. No CRUSH stuff was changed.
osdid ceph-daemon status 437: "num_pgs": 786 438: "num_pgs": 716 439: "num_pgs": 589 440: "num_pgs": 505 441: "num_pgs": 452 442: "num_pgs": 378 443: "num_pgs": 338 444: "num_pgs": 326 445: "num_pgs": 318 446: "num_pgs": 242 447: "num_pgs": 272 448: "num_pgs": 221 449: "num_pgs": 221 450: "num_pgs": 182 451: "num_pgs": 136
Here's a screenshot of the PG count history. You can see I added 3 servers, and how the num_pgs decrease over time, even though the disks are filled up more.
Updated by Jonas Jelten about 3 years ago
Another observation: I have nobackfill set, and I'm currently adding 8 new OSDs.
The first of the newly added OSDs had num_pgs: 335 after 3/8 devices were added.
After adding the fourth, the first one has num_pgs: 381.
After adding the fifth, the first one has num_pgs: 403 (the fifth has 125 now)
etc
So each new disks adds more PGs to the previously added but not yet balanced devices.
What does help is restarting newly created OSDs. So when I restart the fifth device, the first (and all the others) suddenly has less PGs.
What also helps is setting the new OSDs down with ceph osd down $id, of course they will become up shortly after.
What does not help is restarting all OSDs on the new host. What also does not help is setting all these new OSDs down at once.
So a dirty hack that helps against the overallocation is repeer all those new OSDs one after the other:for id in {452..459}; do ceph osd down $id; sleep 15; done
Updated by Jonas Jelten over 2 years ago
- Affected Versions v15.2.15 added
still encountering on ceph octopus 15.2.15 :(
please add the HEALTH_ERROR when the limit is hit, then one at least knows why a pg remains in activating state.
Updated by Neha Ojha over 2 years ago
- Related to Bug #23117: PGs stuck in "activating" after osd_max_pg_per_osd_hard_ratio has been exceeded once added