Bug #48212
closedpoollast_epoch_clean floor is stuck after pg merging
100%
Description
We just merged a pool (id 36) from 1024 to 64 PGs, and after this was done the cluster osdmaps were no longer trimmed.
I found that this was because the merged pool's last_epoch_clean floor (in OSDMonitor.cc) was stuck at the epoch before merging started (e163735).
# ceph report | grep committed
"osdmap_first_committed": 163735,
"osdmap_last_committed": 168376,
# ceph report | jq .osdmap_clean_epochs.last_epoch_clean
"osdmap_clean_epochs": {
"min_last_epoch_clean": 168375,
"last_epoch_clean": {
"per_pool": [
{
"poolid": 3,
"floor": 168375
},
...
{
"poolid": 35,
"floor": 168375
},
{
"poolid": 36,
"floor": 163735
}
]
},
To workaround I restarted the mon leader, after which the pool 36 min_epoch_clean caught up with the other pools and osdmaps were trimmed.
Is this a bug? Or was I perhaps too impatient after the merge. (Maybe all the merged PGs need a deep scrub or something like that before the l_e_c will catch up?)
Thanks!
Files
Updated by Dan van der Ster over 3 years ago
I did a wrong copy and paste -- the ceph report had
"min_last_epoch_clean": 163735,Updated by David Herselman over 3 years ago
- File kvm7_mon_usage.png kvm7_mon_usage.png added
We're running Ceph Octopus 15.2.8 with the same problem. Our monitors ran out of space after enabling autoscale as osdmaps are not pruned until the leading monitor is restarted. Whilst the merging process is safe, in that it only decrements pg_num again once misplaced objected are moved around, due to it not trimming osdmaps as it regains full health it leads to situations were clusters would be inaccessible due to monitors running out of space.
Restarting the leading monitor during a merge does not trim the osdmap, how would one recover in a situation where monitors are offline due to them having run out of space?
We have another pool that we would also like to reduce placement group numbers on and can reproduce the problem at will by simply reducing pg_num by 100 (was 1024, target is 64). For example if the current pg_num is 800, cluster is healthy and monitors are using <3 GiB:
[admin@kvm7b ~]# ceph osd pool set ec_hdd pg_num 700
After some hours everything completes but store grows to 23 GiB:

After reducing from 800 to 700 pg_num:
[admin@kvm7b ~]# ceph osd dump | grep ec_hdd
pool 8 'ec_hdd' erasure profile ec32_hdd size 5 min_size 4 crush_rule 3 object_hash rjenkins pg_num 700 pgp_num 700 autoscale_mode warn last_change 77572 lfor 384/77572/77570 flags hashpspool,ec_overwrites,selfmanaged_snaps tiers 10 read_tier 10 write_tier 10 stripe_width 12288 application rbd
[admin@kvm7b ~]# ceph -s
cluster:
id: cf07a431-7d5c-45df-ab7d-7c92ea7b5cd1
health: HEALTH_WARN
mons kvm7a,kvm7b,kvm7e are using a lot of disk space
1 pool(s) have non-power-of-two pg_num
2 pools have too many placement groups
services:
mon: 3 daemons, quorum kvm7a,kvm7b,kvm7e (age 80m)
mgr: kvm7e(active, since 3d), standbys: kvm7b, kvm7a
mds: cephfs:1 {0=kvm7b=up:active} 2 up:standby
osd: 60 osds: 59 up (since 3d), 59 in (since 6M)
rgw: 3 daemons active (radosgw.kvm7a, radosgw.kvm7b, radosgw.kvm7e)
tcmu-runner: 12 daemons active (kvm7a:iscsi/vm-169-disk-2, kvm7b:iscsi/vm-169-disk-2, kvm7e:iscsi/vm-169-disk-2)
task status:
data:
pools: 15 pools, 1629 pgs
objects: 18.92M objects, 20 TiB
usage: 40 TiB used, 268 TiB / 308 TiB avail
pgs: 1626 active+clean
3 active+clean+scrubbing
io:
client: 8.1 KiB/s rd, 693 KiB/s wr, 7 op/s rd, 49 op/s wr
[admin@kvm7b ~]# ceph daemon osd.200 status
{
"cluster_fsid": "cf07a431-7d5c-45df-ab7d-7c92ea7b5cd1",
"osd_fsid": "71d27d56-59bf-4b89-ab19-a43602fee8cf",
"whoami": 200,
"state": "active",
"oldest_map": 70170,
"newest_map": 77656,
"num_pgs": 41
}
[admin@kvm7b ~]# ceph report | jq .osdmap_first_committed
report 2501770158
70170
[admin@kvm7b ~]# ceph report | jq .osdmap_last_committed
report 2229346450
77656
[admin@kvm7b ~]# ceph report | grep "min_last_epoch_clean"
report 535617613
"min_last_epoch_clean": 0,
[admin@kvm7b ~]# ceph report | jq '.osdmap_manifest.pinned_maps | length'
report 1861220632
0
[admin@kvm7b ~]# ceph report | jq .osdmap_clean_epochs
report 1705570990
{
"min_last_epoch_clean": 0,
"last_epoch_clean": {
"per_pool": []
},
"osd_epochs": []
}
[admin@kvm7b ~]# du -sh /var/lib/ceph/mon/ceph-kvm7b/store.db
23G /var/lib/ceph/mon/ceph-kvm7b/store.db
After then running 'systemctl restart ceph-mon@kvm7a/b/c' it immediately starts trimming. 2 minutes later:
[admin@kvm7b ~]# du -sh /var/lib/ceph/mon/ceph-kvm7b/store.db
1.8G /var/lib/ceph/mon/ceph-kvm7b/store.db
[admin@kvm7b ~]# ceph daemon osd.200 status
{
"cluster_fsid": "cf07a431-7d5c-45df-ab7d-7c92ea7b5cd1",
"osd_fsid": "71d27d56-59bf-4b89-ab19-a43602fee8cf",
"whoami": 200,
"state": "active",
"oldest_map": 70170,
"newest_map": 77656,
"num_pgs": 41
}
[admin@kvm7b ~]# ceph report | jq .osdmap_first_committed
report 1859194375
77156
[admin@kvm7b ~]# ceph report | jq .osdmap_last_committed
report 3598010931
77656
[admin@kvm7b ~]# ceph report | grep "min_last_epoch_clean"
report 3944254309
"min_last_epoch_clean": 77655,
[admin@kvm7b ~]# ceph report | jq '.osdmap_manifest.pinned_maps | length'
report 1361140713
0
[admin@kvm7b ~]# ceph report | jq .osdmap_clean_epochs
report 2361317492
{
"min_last_epoch_clean": 0,
"last_epoch_clean": {
"per_pool": []
},
"osd_epochs": []
}
Updated by David Herselman over 3 years ago
Apologies, the leading monitor bit is miss leading. The osdmap data is immediately trimmed the moment the last monitor is restarted. We restarted the first, second and then waited 5 minutes before restarting that third. At that point one of the restarted monitors was the leader, not the last monitor we restarted after which it immediately pruned the osdmaps.
Updated by David Herselman over 3 years ago
Reproduced on another merge cycle. Restarting only the leading mon, waiting 5 minutes and then creating a new epoch results in osdmaps immediately being purged.
[admin@kvm7a ~]# ceph tell mon.kvm7a mon_status | jq .state "leader" [admin@kvm7a ~]# systemctl restart ceph-mon@kvm7a [admin@kvm7a ~]# sleep 300 [admin@kvm7a ~]# ceph osd set noup [admin@kvm7a ~]# ceph osd unset noup
Updated by David Herselman over 3 years ago
- File ceph-mon_free.png ceph-mon_free.png added
We got a little relief by reducing mon_osdmap_full_prune_min from the default 10,000 to 1,000 but osdmaps still grew to 15K+ whilst merging. kvm7b was the first to fill to 100% and couldn't be started again until we'd cleared all old log files. This gave it 2% free disc space so the service still wouldn't start. Running just a 'list' cleared up another GiB but running compact shrunk the store.db folder from 54 GiB to 1.4 GiB instantly:
[root@kvm7b ~]# systemctl stop ceph-mon@kvm7b [root@kvm7b ~]# systemctl reset-failed [root@kvm7b ~]# sudo -u ceph ceph-kvstore-tool rocksdb /var/lib/ceph/mon/kvm7b/store.db list [root@kvm7b ~]# sudo -u ceph ceph-kvstore-tool rocksdb /var/lib/ceph/mon/kvm7b/store.db compact [root@kvm7b ~]# systemctl start ceph-mon@kvm7b
Reducing mon_osdmap_full_prune_min results in the rocksdb monitor store being pruned constantly, resulting in the saw tooth pattern in the grows below, but overall utilisation still grows until the leading monitor is restarted. This doesn't release all space though and on occasion appears to result in monitors not purging osdmaps resulting in the sudden increase which started at about 22:15: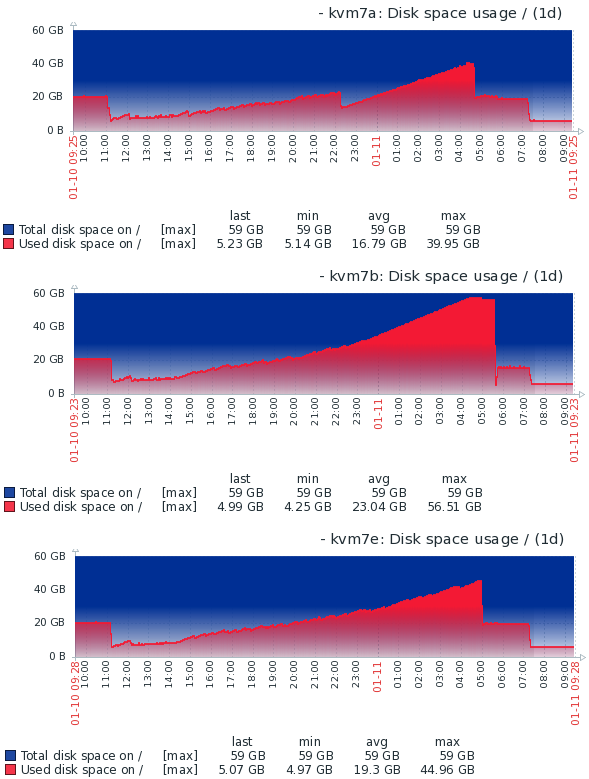
Updated by Theofilos Mouratidis about 3 years ago
We reduced the pg/pgp size of our pool to keep the 100 pgs per osd after we decommissioned a lot of osd hosts. When the merge finished we had this output
[11:31][root@xxx ~]# ceph daemon osd.250 status
{
"oldest_map": 930746,
"newest_map": 1066681
}
I uploaded my `ceph report` output at: 1a1a6f05-4c57-4745-a395-56840bf247b9
We use 14.2.19 currently.
Updated by Dan van der Ster almost 3 years ago
I suspect the cause is that there's a leftover epoch value for the now-deleted PG in `epoch_by_pg` in `void LastEpochClean::Lec::report(ps_t ps, epoch_t last_epoch_clean)`.
This means that this check is stuck forever until the leader is restarted:
auto new_floor = std::min_element(std::begin(epoch_by_pg),
std::end(epoch_by_pg));
So we need to change this to only look at the first pg_num entries, or better, to resize epoch_by_pg if is larger than pg_num.
BTW, it appears we already handle the case of splitting PGs -- we just need to add a case for merging:
void LastEpochClean::Lec::report(ps_t ps, epoch_t last_epoch_clean)
{
if (epoch_by_pg.size() <= ps) {
epoch_by_pg.resize(ps + 1, 0);
}
...
Updated by Dan van der Ster almost 3 years ago
Dan van der Ster wrote:
I suspect the cause is that there's a leftover epoch value for the now-deleted PG in `epoch_by_pg` in `void LastEpochClean::Lec::report(ps_t ps, epoch_t last_epoch_clean)`.
This means that this check is stuck forever until the leader is restarted:
[...]So we need to change this to only look at the first pg_num entries, or better, to resize epoch_by_pg if is larger than pg_num.
BTW, it appears we already handle the case of splitting PGs -- we just need to add a case for merging:
[...]
Updated by Dan van der Ster almost 3 years ago
- Status changed from New to Fix Under Review
- Pull request ID set to 42136
Updated by Kefu Chai almost 3 years ago
- Status changed from Fix Under Review to Pending Backport
- Backport set to octopus, pacific
Updated by Backport Bot almost 3 years ago
- Copied to Backport #51568: pacific: pool last_epoch_clean floor is stuck after pg merging added
Updated by Backport Bot almost 3 years ago
- Copied to Backport #51569: octopus: pool last_epoch_clean floor is stuck after pg merging added
Updated by Konstantin Shalygin over 2 years ago
- Category set to Performance/Resource Usage
- Source set to Community (user)
- Backport changed from octopus, pacific to nautilus octopus pacific
- Affected Versions v14.2.22, v15.2.9 added
- Affected Versions deleted (
v14.2.12, v14.2.13)
Updated by Konstantin Shalygin over 2 years ago
- Copied to Backport #52644: nautilus: pool last_epoch_clean floor is stuck after pg merging added
Updated by Konstantin Shalygin over 1 year ago
- Subject changed from pool last_epoch_clean floor is stuck after pg merging to poollast_epoch_clean floor is stuck after pg merging
- Status changed from Pending Backport to Resolved
- % Done changed from 0 to 100
Nautilus is EOL