Bug #42594
closedold bucket index shard removal is too aggressive
0%
Description
When deleting old index shards post resharding or using `radosgw-admin reshard stale-instances rm` the process is to rm the RADOS objects one at a time.
For very large shards this will make index OSDs miss HBs and flap until the radosgw-admin CLI exits.
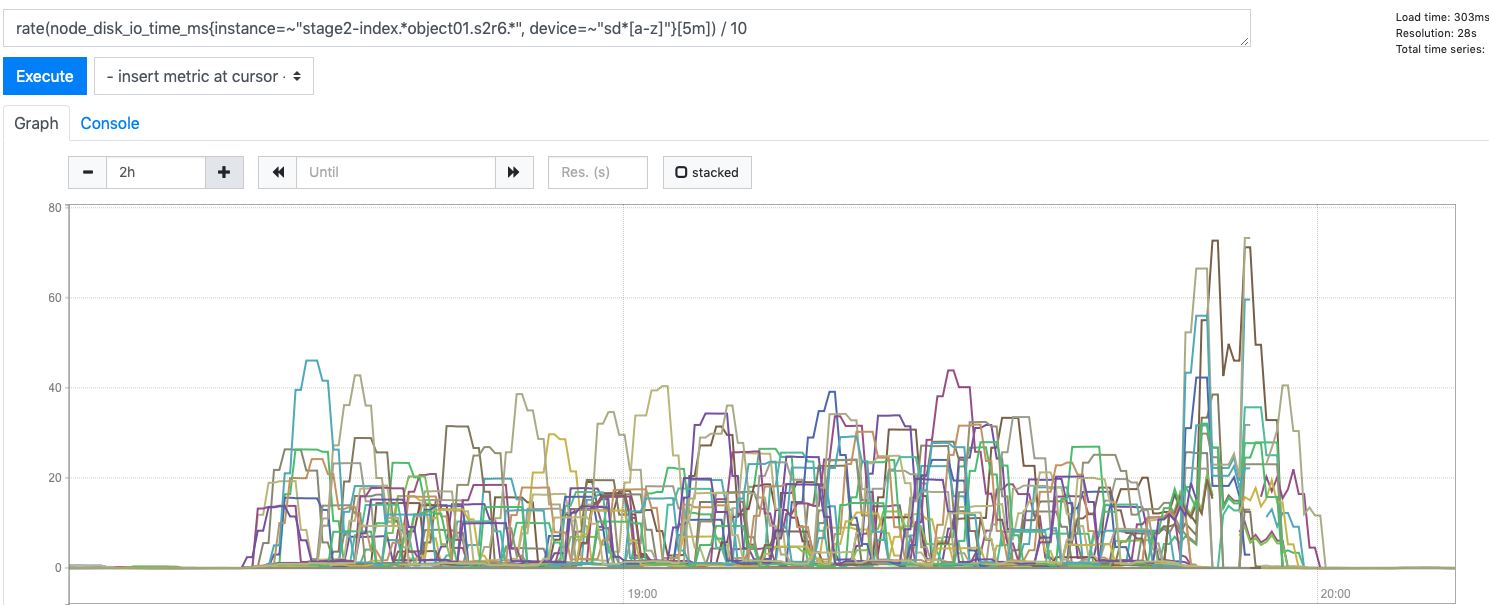
Below is some data on a bucket with 100M entries and 32 shards on an idle test cluster.
A capture of disk %util during resharding is attached. We can clearly 2 phases:
- First is the resharding itself, disk util is moderate, cluster is stable
- Second is the old shard removal. disk util is very high. Note that the exporter appeared to have become unresponsive during that time, hence why some lines are truncated
During the shard removal we can see OSDs flapping, all with missed HB, no actual crash:
# grep boot /var/log/ceph/ceph.log 2019-10-31 19:48:53.582739 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311228 : cluster [INF] osd.263 10.116.45.140:6807/3376872 boot 2019-10-31 19:48:53.582874 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311229 : cluster [INF] osd.259 10.116.45.139:6800/1587770 boot 2019-10-31 19:48:57.724469 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311236 : cluster [INF] osd.246 10.116.45.140:6800/3377060 boot 2019-10-31 19:49:04.327580 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311244 : cluster [INF] osd.258 10.116.45.139:6802/1587805 boot 2019-10-31 19:49:21.582825 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311268 : cluster [INF] osd.247 10.116.45.16:6810/1099439 boot 2019-10-31 19:50:10.346451 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311319 : cluster [INF] osd.260 10.116.45.140:6802/3376868 boot 2019-10-31 19:51:11.733870 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311424 : cluster [INF] osd.258 10.116.45.139:6802/1587805 boot 2019-10-31 19:51:16.587290 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311445 : cluster [INF] osd.263 10.116.45.140:6807/3376872 boot 2019-10-31 19:52:34.159245 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311536 : cluster [INF] osd.261 10.116.45.140:6806/3376871 boot 2019-10-31 19:53:55.086459 mon.stage2-mon01-object01 mon.0 10.116.45.12:6789/0 311650 : cluster [INF] osd.258 10.116.45.139:6802/1587805 boot
Until the radosgw-admin reshard CLI exits:
2019-10-31 19:49:33.463928 7fd63effd700 -1 RGWWatcher::handle_error cookie 140558646832448 err (107) Transport endpoint is not connected 2019-10-31 19:49:48.950496 7fd63effd700 -1 RGWWatcher::handle_error cookie 140558646810496 err (107) Transport endpoint is not connected 2019-10-31 19:49:48.950548 7fd63effd700 -1 RGWWatcher::handle_error cookie 140558646857216 err (107) Transport endpoint is not connected 2019-10-31 19:50:06.279199 7fd63effd700 -1 RGWWatcher::handle_error cookie 140558646854368 err (107) Transport endpoint is not connected 2019-10-31 19:50:49.271941 7fd63effd700 -1 RGWWatcher::handle_error cookie 140558646902144 err (107) Transport endpoint is not connected 2019-10-31 19:51:11.402284 7fd63effd700 -1 RGWWatcher::handle_error cookie 140558646922896 err (107) Transport endpoint is not connected 2019-10-31 19:52:17.818702 7fd63effd700 -1 RGWWatcher::handle_error cookie 140558646856032 err (107) Transport endpoint is not connected 2019-10-31 19:52:41.263411 7fd63effd700 -1 RGWWatcher::handle_error cookie 140558646879248 err (107) Transport endpoint is not connected 2019-10-31 19:52:47.828530 7fd63effd700 -1 RGWWatcher::handle_error cookie 140554616704352 err (107) Transport endpoint is not connected
I think a better approach to shard removal would be to removes X omap keys at a time, pause, repeat, until no omap keys are left, then rm the RADOS object.
Files
{kind=link}
Updated by Casey Bodley over 4 years ago
- Related to Feature #19975: RFE: expose OP_OMAP_RMKEYRANGE in librados and cls added
Updated by Casey Bodley over 4 years ago
- Status changed from New to Triaged
- Tags set to omap
Work was done to support bulk deletion of omap entries in the osd, and I think that's the only reasonable solution to this issue.
Updated by Alexandre Marangone about 1 year ago
- Status changed from Triaged to Closed