Bug #37435
openmds operates hung at ceph_mdsc_do_request
0%
Description
we use kernel client to mount cephfs, operates like ls cmd on some dirs in cephfs hung for long time
mdsc
cat /sys/kernel/debug/ceph/d128c8dc-1d20-4b99-89e0-9ae813dfeec5.client4003418/mdsc 6 mds0 readdir #10000000b1c
process stack
cat /proc/4045/stack [<ffffffffc08513fd>] ceph_mdsc_do_request+0x12d/0x2e0 [ceph] [<ffffffffc0831e03>] ceph_readdir+0x233/0xf20 [ceph] [<ffffffff8121a216>] vfs_readdir+0xb6/0xe0 [<ffffffff8121a635>] SyS_getdents+0x95/0x120 [<ffffffff816c0715>] system_call_fastpath+0x1c/0x21 [<ffffffffffffffff>] 0xffffffffffffffff
how to solve this problem? Thanks
kernel version 3.10.0-693.21.1.el7.x86_64 ceph version 12.2.5 (cad919881333ac92274171586c827e01f554a70a) luminous (stable)
Files
Updated by Zheng Yan over 5 years ago
this is likely caused by mds.
run command 'ceph daemon mds.xx dump_blocked_ops' if you encounter this again.
Updated by dhacky du over 5 years ago
Recently we update ceph to version 13.2.2 (02899bfda814146b021136e9d8e80eba494e1126) mimic (stable)
when mds is under high request pressure, e.g. one mds request > 12K/s, some MDSs will report slow requests
mds.1: 57 slow requests are blocked > 30 secs mds.0: 55 slow requests are blocked > 30 secs
and
1 clients failing to respond to capability release
at that time I run command on one mds
#ceph daemon mds.$(hostname -s) dump_ops_in_flight | grep -B 5 "point\": \"failed" | grep client_request
"description": "client_request(client.726458:1747 mkdir #0x20000000be6/7975daa802f749d390d0f3cf475d0175 2018-11-29 17:17:08.215918 caller_uid=0, caller_gid=0{})",
"description": "client_request(client.813103:1246 mkdir #0x20000000be6/5eb321ff972248aaae276db6d27bc7fb 2018-11-29 17:25:39.272228 caller_uid=0, caller_gid=0{})",
"description": "client_request(client.473785:7510 mkdir #0x20000000be6/b422b39d0e6f4e84b80b823de3cd36d7 2018-11-29 18:07:37.856199 caller_uid=0, caller_gid=0{})",
"description": "client_request(client.481595:9781 mkdir #0x20000000be6/58968218b5a54d1a974e0ff69e1bc54e 2018-11-29 17:09:44.576685 caller_uid=0, caller_gid=0{})",
"description": "client_request(client.647879:2478 mkdir #0x20000000be6/d768c0a2df964fb5b4e87fa2ee5ba37a 2018-11-29 18:06:53.957206 caller_uid=0, caller_gid=0{})",
"description": "client_request(client.481595:10483 readdir #0x1000000339b 2018-11-29 18:10:28.125759 caller_uid=0, caller_gid=0{})",
"description": "client_request(client.508384:12777 mkdir #0x20000000be6/d101654ae2fb4ca9aaa33875c8ca83c0 2018-11-29 17:19:04.927509 caller_uid=0, caller_gid=0{})",
list some of flag point
"flag_point": "failed to authpin, subtree is being exported" "flag_point": "failed to rdlock, waiting" "flag_point": "failed to wrlock, waiting"
In mds log I found a Segmentation fault
2018-11-29 16:10:57.517 7f2317e13700 -1 *** Caught signal (Segmentation fault) **
in thread 7f2317e13700 thread_name:ms_dispatch
ceph version 13.2.2 (02899bfda814146b021136e9d8e80eba494e1126) mimic (stable)
1: (()+0x3ed0a0) [0x56240fd5f0a0]
2: (()+0xf5e0) [0x7f231f0365e0]
3: (MDCache::rejoin_send_rejoins()+0x2132) [0x56240fb7f242]
4: (MDCache::process_imported_caps()+0x1344) [0x56240fb83e94]
5: (MDCache::rejoin_open_ino_finish(inodeno_t, int)+0x3d0) [0x56240fb8a6d0]
6: (MDSInternalContextBase::complete(int)+0x67) [0x56240fce05f7]
7: (void finish_contexts<MDSInternalContextBase>(CephContext*, std::list<MDSInternalContextBase*, std::allocator<MDSInternalContextBase*> >&, int)+0x93) [0x56240fa760a3]
8: (MDCache::open_ino_finish(inodeno_t, MDCache::open_ino_info_t&, int)+0x82) [0x56240fb31a42]
9: (MDCache::handle_open_ino_reply(MMDSOpenInoReply*)+0x270) [0x56240fb61aa0]
10: (MDSRank::handle_deferrable_message(Message*)+0x139) [0x56240fa7b339]
11: (MDSRank::_dispatch(Message*, bool)+0x7db) [0x56240fa87f9b]
12: (MDSRankDispatcher::ms_dispatch(Message*)+0x15) [0x56240fa88585]
13: (MDSDaemon::ms_dispatch(Message*)+0xc3) [0x56240fa737f3]
14: (DispatchQueue::entry()+0xb7a) [0x7f23214700ca]
15: (DispatchQueue::DispatchThread::entry()+0xd) [0x7f232150fd2d]
16: (()+0x7e25) [0x7f231f02ee25]
17: (clone()+0x6d) [0x7f231e11134d]
On some cephfs kernel mount client, I can see so many WARNINGs e.g.
ceph: mdsc_handle_session bad op 11 mds4 [ +0.000712] ------------[ cut here ]------------ [ +0.000025] WARNING: CPU: 62 PID: 53965 at fs/ceph/mds_client.c:2701 dispatch+0x6c5/0xb50 [ceph] [ +0.000003] Modules linked in: ceph(OE) libceph dns_resolver ip_vs cfg80211 rfkill fuse nf_conntrack_netlink veth ipmi_si xt_set xt_multiport [ +0.000070] mei lpc_ich shpchp ipmi_devintf ipmi_msghandler acpi_power_meter wmi ip_tables xfs libcrc32c sd_mod crc_t10dif crct10dif_generic [ +0.000036] CPU: 62 PID: 53965 Comm: kworker/62:2 Tainted: G W OE ------------ T 3.10.0-693.5.2.el7.x86_64 #1 [ +0.000002] Hardware name: Dell Inc. PowerEdge R630/02C2CP, BIOS 2.4.3 01/17/2017 [ +0.000020] Workqueue: ceph-msgr ceph_con_workfn [libceph] [ +0.000002] 0000000000000000 00000000e94e90a7 ffff88142a73bc38 ffffffff816a3e51 [ +0.000005] ffff88142a73bc78 ffffffff810879d8 00000a8d2a73bc58 ffff8845e36f3800 [ +0.000003] ffff881373db82d0 ffff886ce1bf1000 000000000000000b ffff88414df293e0 [ +0.000005] Call Trace: [ +0.000012] [<ffffffff816a3e51>] dump_stack+0x19/0x1b [ +0.000009] [<ffffffff810879d8>] __warn+0xd8/0x100 [ +0.000005] [<ffffffff81087b1d>] warn_slowpath_null+0x1d/0x20 [ +0.000013] [<ffffffffc07b4625>] dispatch+0x6c5/0xb50 [ceph] [ +0.000010] [<ffffffff8156a90a>] ? kernel_recvmsg+0x3a/0x50 [ +0.000011] [<ffffffffc0671f1f>] try_read+0x4df/0x1240 [libceph] [ +0.000009] [<ffffffff810ce55e>] ? dequeue_task_fair+0x41e/0x660 [ +0.000009] [<ffffffffc0672d39>] ceph_con_workfn+0xb9/0x650 [libceph] [ +0.000035] [<ffffffff810a882a>] process_one_work+0x17a/0x440 [ +0.000004] [<ffffffff810a94f6>] worker_thread+0x126/0x3c0 [ +0.000005] [<ffffffff810a93d0>] ? manage_workers.isra.24+0x2a0/0x2a0 [ +0.000004] [<ffffffff810b099f>] kthread+0xcf/0xe0 [ +0.000005] [<ffffffff8108ddfb>] ? do_exit+0x6bb/0xa40 [ +0.000004] [<ffffffff810b08d0>] ? insert_kthread_work+0x40/0x40 [ +0.000007] [<ffffffff816b4fd8>] ret_from_fork+0x58/0x90 [ +0.000003] [<ffffffff810b08d0>] ? insert_kthread_work+0x40/0x40 [ +0.000007] ---[ end trace aaf0c9301a403a94 ]---
WARNING: CPU: 56 PID: 80411 at fs/ceph/inode.c:567 ceph_fill_file_size+0x1f1/0x220 [ceph]
Workqueue: ceph-msgr ceph_con_workfn [libceph]
0000000000000000 00000000bbaa4da9 ffff882c3db1f9f0 ffffffff816a3e51
ffff882c3db1fa30 ffffffff810879d8 0000023720446400 ffff882276823550
0000000000000002 0000000000000100 000000001fffffe2 00000000000034dd
Call Trace:
[<ffffffff816a3e51>] dump_stack+0x19/0x1b
[<ffffffff810879d8>] __warn+0xd8/0x100
[<ffffffff81087b1d>] warn_slowpath_null+0x1d/0x20
[<ffffffffc06fcb61>] ceph_fill_file_size+0x1f1/0x220 [ceph]
[<ffffffffc06fd2d3>] fill_inode.isra.13+0x253/0xd70 [ceph]
[<ffffffffc06fdf35>] ceph_fill_trace+0x145/0xa00 [ceph]
[<ffffffffc071eb5a>] handle_reply+0x3ea/0xc80 [ceph]
[<ffffffffc06d11ad>] ? ceph_x_encrypt+0x4d/0x80 [libceph]
[<ffffffffc07211e9>] dispatch+0xd9/0xb00 [ceph]
[<ffffffff8156a90a>] ? kernel_recvmsg+0x3a/0x50
[<ffffffffc06b8f1f>] try_read+0x4df/0x1240 [libceph]
[<ffffffff81033619>] ? sched_clock+0x9/0x10
[<ffffffffc06b9d39>] ceph_con_workfn+0xb9/0x650 [libceph]
[<ffffffff810a882a>] process_one_work+0x17a/0x440
[<ffffffff810a94f6>] worker_thread+0x126/0x3c0
[<ffffffff810a93d0>] ? manage_workers.isra.24+0x2a0/0x2a0
[<ffffffff810b099f>] kthread+0xcf/0xe0
[<ffffffff810b08d0>] ? insert_kthread_work+0x40/0x40
[<ffffffff816b4fd8>] ret_from_fork+0x58/0x90
[<ffffffff810b08d0>] ? insert_kthread_work+0x40/0x40
---[ end trace 4ba8f0e0bd63865c ]---
How to fix this problem?
We try to reduce the pressure of mds by adding some MDSs, the number from 3 to 7, even to 30
but we noticed an another problem, the MDSs had unbalanced load
Rank State Activity Dentries Inodes 0 active Reqs: 1.653k /s 8.7761M 8.6766M 1 active Reqs: 37.8 /s 1.1744M 1.1744M 2 active Reqs: 0.8 /s 5.0758M 5.0758M 3 active Reqs: 0.4 /s 185.162k 185.165k 4 active Reqs: 0 /s 147.842k 147.852k 5 active Reqs: 0 /s 8.358k 8.367k 6 active Reqs: 0 /s 1.353k 1.381k
Then We use
setfattr -n ceph.dir.pin -v 5 pathto split subtrees to some idle MDSs
this can relief a little request pressure.
The following figure is mds load after adjust manually.
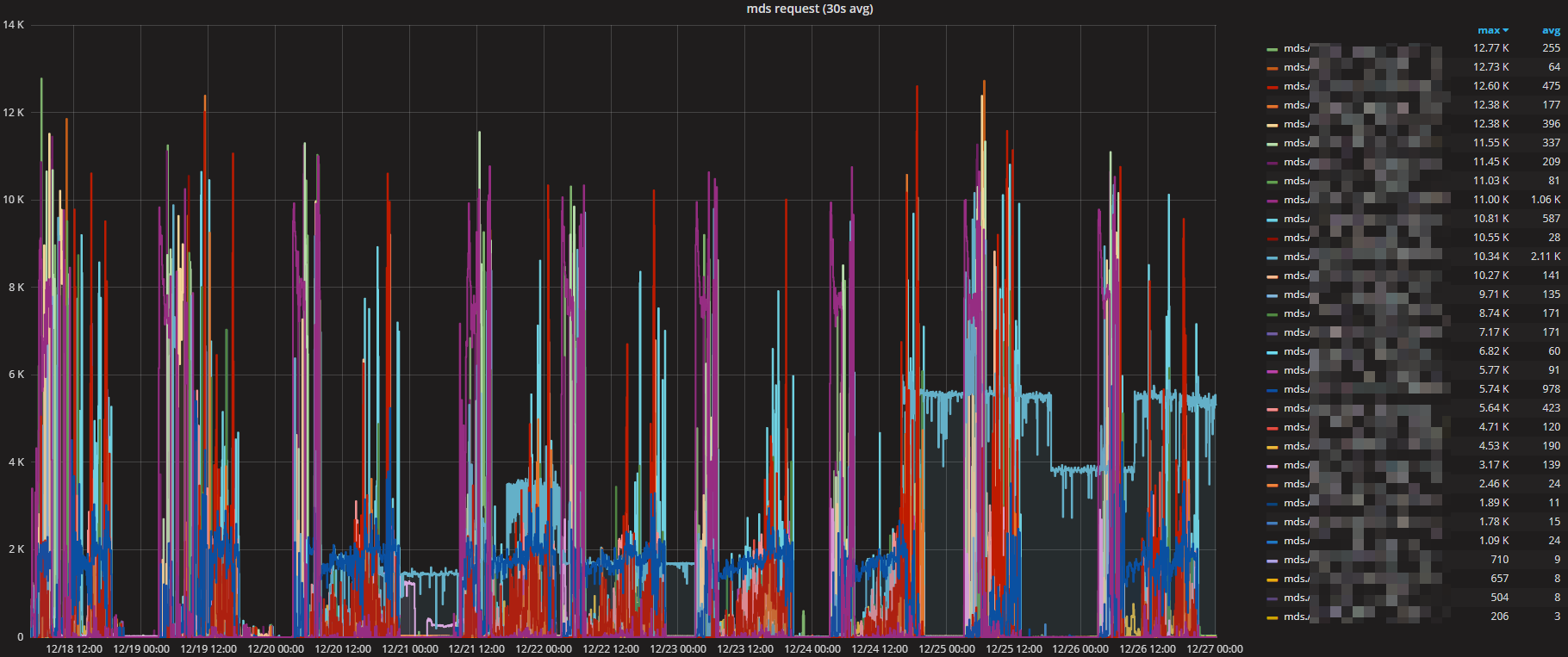
But there is so many and big dirs in cephfs, we can't handle the mds load manually. And when clients requests heavily to MDSs, MDSs will occur so much slow requests yet.
So how to config MDSs or clients to split or merge subtrees which allows dividing the metadata load across the MDS ranks automatically and dynamically?
Thanks!