Bug #3702
closedOSD SIGABRT during startup
0%
Description
After conversion of OSD's from btrfs to XFS, some OSD's SIGABRT during their first startup on XFS:
2012-12-29 05:04:43.819403 7f4bdd0e6780 1 journal _open /dev/sda_vg/osd.131-journal fd 28: 2571108352 bytes, block size 4096 bytes, directio = 1, aio = 0
2012-12-29 05:04:43.834333 7f4bce987700 -1 ** Caught signal (Aborted) *
in thread 7f4bce987700
ceph version 0.48.2argonaut (commit:3e02b2fad88c2a95d9c0c86878f10d1beb780bfe)
1: /usr/bin/ceph-osd() [0x6edaba]
2: (()+0xfcb0) [0x7f4bdc583cb0]
3: (gsignal()+0x35) [0x7f4bdb15b425]
4: (abort()+0x17b) [0x7f4bdb15eb8b]
5: (_gnu_cxx::_verbose_terminate_handler()+0x11d) [0x7f4bdbaad69d]
6: (()+0xb5846) [0x7f4bdbaab846]
7: (()+0xb5873) [0x7f4bdbaab873]
8: (()+0xb596e) [0x7f4bdbaab96e]
9: (ceph::buffer::list::iterator::copy(unsigned int, char*)+0x127) [0x7a94f7]
10: (OSDMap::decode(ceph::buffer::list::iterator&)+0x3f) [0x7670ff]
11: (OSDMap::decode(ceph::buffer::list&)+0x3e) [0x7681fe]
12: (OSD::handle_osd_map(MOSDMap*)+0xa2f) [0x5d38bf]
13: (OSD::_dispatch(Message*)+0x43b) [0x5d755b]
14: (OSD::ms_dispatch(Message*)+0x153) [0x5d7bb3]
15: (SimpleMessenger::DispatchQueue::entry()+0x903) [0x785f43]
16: (SimpleMessenger::dispatch_entry()+0x24) [0x786ce4]
17: (SimpleMessenger::DispatchThread::entry()+0xd) [0x74692d]
18: (()+0x7e9a) [0x7f4bdc57be9a]
19: (clone()+0x6d) [0x7f4bdb218cbd]
NOTE: a copy of the executable, or `objdump -rdS <executable>` is needed to interpret this.Files
{kind=link}
{kind=link}
Updated by Justin Lott over 11 years ago
- File hpbs-c01-s01_loadavg.png hpbs-c01-s01_loadavg.png added
- File hpbs-c01-s01_memory.png hpbs-c01-s01_memory.png added
- File ceph-mon.a.log ceph-mon.a.log added
- File ceph-osd.0.log ceph-osd.0.log added
- File ceph-osd.131.log ceph-osd.131.log added
- File ceph-mon.b.log ceph-mon.b.log added
- File ceph-mon.c.log ceph-mon.c.log added
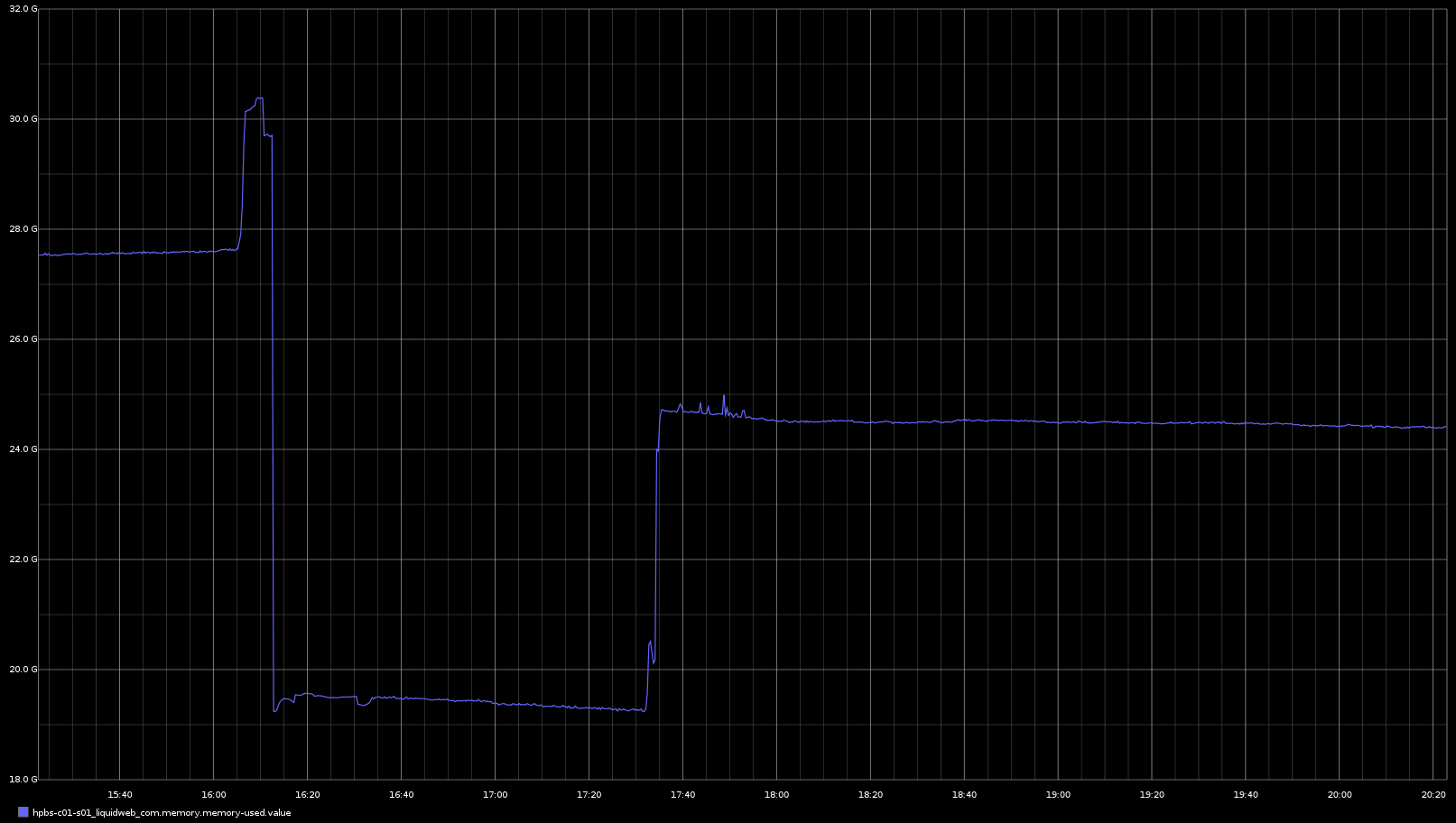
Attempting to start osd.131 (which was down due to the above noted problems) today resulted in quorum loss. Essentially, osd.131 was started, crashed within 5 seconds, memory usage for mon.a jumped up by 3G, and the load avg on the host for mon.a went from ~30 to ~70 causing quorum negotiation problems. It is unclear whether load avg on hpbs-c01-s01 (mon.a) jumped to 70 due to IO, CPU, or some combination. We had HEALTH_OK before these operations were carried out.
Resolution was to kill all mon processess and restart only mon.b and mon.c (which are on dedicated hosts).
Elapsed window of operational problems: 16:06:29 - 16:32:43 (26m 14s)
Chronology in UTC:
16:05:13.987275 osd.131 is started
16:05:17.640621 osd.131 crashes
16:06:00 (approximate)
load avg on the host for mon.a goes to ~70
ceph-mon.a process is using ~10G of RAM (up from ~7G moments before)
16:06:22.069945 mon.b briefly wins election
16:06:28.348332 osd.0 (same host as mon.a) starts experiencing slow requests. This OSD is eventually marked up/out automatically.
16:06:28.348332 7f34c88ab700 0 log [WRN] : 3 slow requests, 3 included below; oldest blocked for > 33.682273 secs
16:06:28.348341 7f34c88ab700 0 log [WRN] : slow request 33.682273 seconds old, received at 2013-01-02 16:05:54.666006: osd_op(client.709956.0:698084 VG00K4.rbd [watch 1~0] 3.e93333a1) v4 currently delayed
16:06:28.348345 7f34c88ab700 0 log [WRN] : slow request 33.674393 seconds old, received at 2013-01-02 16:05:54.673886: osd_op(client.711550.0:829803 VG00K4.rbd [watch 1~0] 3.e93333a1) v4 currently delayed
16:06:28.348349 7f34c88ab700 0 log [WRN] : slow request 33.640403 seconds old, received at 2013-01-02 16:05:54.707876: osd_op(client.707371.0:1429972 VG00K4.rbd [watch 1~0] 3.e93333a1) v4 currently delayed
16:06:29.639012 mon.a wins election (and keeps doing so) but continues to log 'we are not in quorum'
The cycle here is similar to this, almost certainly due to the high load avg on the mon.a host:
16:09:42.403013 7feba4313700 0 log [INF] : mon.a calling new monitor election
16:09:45.698009 7feba4313700 0 log [INF] : mon.a@0 won leader election with quorum 0,1,2
16:10:06.804522 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 28 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:06.804695 7feba4313700 0 log [INF] : mon.a calling new monitor election
16:10:08.950467 7feba4313700 1 mon.a@0(electing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:08.950549 7feba4313700 1 mon.a@0(electing) e1 discarding message auth(proto 0 28 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:08.950608 7feba4313700 1 mon.a@0(electing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:08.950651 7feba4313700 1 mon.a@0(electing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:08.950733 7feba4313700 1 mon.a@0(electing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:08.950778 7feba4313700 1 mon.a@0(electing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:08.950812 7feba4313700 1 mon.a@0(electing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:08.950928 7feba4313700 1 mon.a@0(electing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:11.314228 7feba4313700 0 log [INF] : mon.a@0 won leader election with quorum 0,1,2
16:10:26.275599 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 26 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.275672 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 28 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.275714 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 28 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.275778 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.275868 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 28 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.275917 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.275956 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 28 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.276056 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 28 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.276094 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.276155 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.276341 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 27 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.276387 7feba4313700 1 mon.a@0(probing) e1 discarding message auth(proto 0 28 bytes epoch 1) v1 and sending client elsewhere; we are not in quorum
16:10:26.330723 7feba4313700 0 log [INF] : mon.a calling new monitor election
16:10:28.587834 7feba4313700 0 log [INF] : mon.a@0 won leader election with quorum 0,1,2
16:10:40.286311 7feba4313700 0 log [INF] : mdsmap e1: 0/0/1 up
16:30:34.381083 mon.a is killed (kill $pid)
16:32:03.461784 mon.b is killed (service stop)
16:32:11.683827 mon.c is killed (service stop)
16:32:31.454440 mon.b is started (service start)
16:32:35.973086 mon.c is started (service start)
Updated by Sage Weil over 11 years ago
Was the monitor also running 0.48.2argonaut when osd.131 originally crashed? Or something else?
Updated by Sage Weil over 11 years ago
- Status changed from New to Need More Info
Updated by Justin Lott over 11 years ago
Sage Weil wrote:
Was the monitor also running 0.48.2argonaut when osd.131 originally crashed? Or something else?
Yes. Every node in this cluster is and always has been running 0.48.2argonaut.
Updated by Dan Mick over 11 years ago
Is this related to rbd, or should it be in category 'ceph'?
Updated by Justin Lott over 11 years ago
Dan Mick wrote:
Is this related to rbd, or should it be in category 'ceph'?
Ah, yes, it should. Thank you for changing it, Dan.
Updated by Ian Colle over 11 years ago
- Status changed from Need More Info to New
- Assignee changed from Sage Weil to Samuel Just
Updated by Samuel Just over 11 years ago
- Assignee changed from Samuel Just to Dan Mick
Updated by Samuel Just over 11 years ago
- Assignee changed from Dan Mick to Samuel Just
Updated by Samuel Just about 11 years ago
- Status changed from New to Can't reproduce