Support #36614
closedCluster uses substantially more space after rebalance (erasure codes)
0%
Description
Hi
After I recreated one OSD + increased pg count of my erasure-coded (2+1) pool (which was way too low, only 100 for 9 osds) the cluster started to eats additional disk space.
First I thought that was caused by the moved PGs using additional space during unfinished backfills. I pinned most of new PGs to old OSDs via `pg-upmap` and indeed it freed some space in the cluster.
Then I reduced osd_max_backfills to 1 and started to remove upmap pins in small portions which allowed Ceph to finish backfills for these PGs.
HOWEVER, used capacity still grows! It drops after moving each PG, but still grows overall.
It has grown +1.3TB yesterday. In the same period of time clients have written only ~200 new objects (~800 MB, there are RBD images only).
Why, what's using such big amount of additional space?
// Additional question is why ceph df / rados df tells there is only 16 TB actual data written, but it uses 29.8 TB (now 31 TB) of raw disk space. Shouldn't it be 16 / 2*3 = 24 TB ?
Files
{kind=link}
{kind=link}
Updated by Vitaliy Filippov over 5 years ago
- File photo_2018-10-29_14-10-38.jpg photo_2018-10-29_14-10-38.jpg added
- File photo_2018-10-29_14-10-43.jpg photo_2018-10-29_14-10-43.jpg added
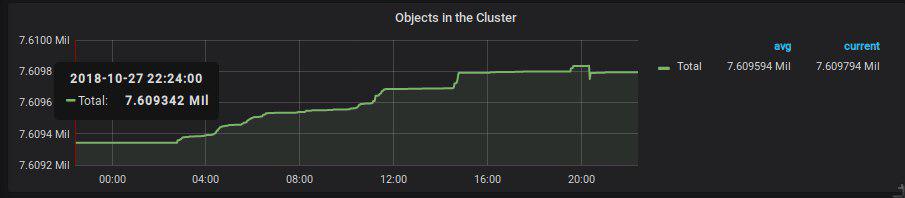
Proofs from our prometheus monitoring. Two graphs from yesterday: one with number of objects in cluster and other with used capacity.
Updated by Vitaliy Filippov over 5 years ago
ceph df output:
[root@sill-01 ~]# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
38 TiB 6.9 TiB 32 TiB 82.03
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
ecpool_hdd 13 16 TiB 93.94 1.0 TiB 7611672
rpool_hdd 15 9.2 MiB 0 515 GiB 92
fs_meta 44 20 KiB 0 515 GiB 23
fs_data 45 0 B 0 1.0 TiB 0
Updated by Vitaliy Filippov over 5 years ago
How to heal it? If I don't heal it I'll need to purge the whole cluster? O_o...
Updated by Greg Farnum over 5 years ago
- Tracker changed from Bug to Support
- Status changed from New to Closed
The mailing list is a better place to resolve this. My guess is data hasn't been cleaned up from its old locations yet, but shrug.
Updated by Vitaliy Filippov over 5 years ago
Thanks for the response, I wrote to the mailing list ceph-users (is it the correct place?) :)
Updated by Vitaliy Filippov over 5 years ago
In fact it doesn't seem that it will self-heal, and nobody seems to care about it in the mailing list by now...)
Currently I have NO PGs that are in the process of moving. All are active+clean. So they shouldn't use extra space. But it seems they do...
As I understand if I remove all pg-upmaps and let backfill finish the cluster will just eat all the space and stop. If that's not a bug... I think I misunderstand the concept of a bug :)
OK if some kind of "garbage collection" will come in action at some point, but it doesn't seem so. I tried to search for any mentions of something similar in the documentation and code and I only found bluestore_gc_* which seems to be only relevant for compressed pools.
Updated by Ben England over 5 years ago
How are you writing these objects? Most sites that used EC were using RGW, but I don't see all the pools that go with RGW in ceph df. So are you using EC with RBD? That's what I'm guessing. Cephfs pools look empty. So how big are the total RBD volume sizes that you created and have you overcommitted RBD volumes? For example, RBD volumes are thinly provisioned (space is not allocated when you create the volume, only when you write to it), so is it possible that existing RBD volumes are just getting written to and this is using more space? It appears that the RADOS objects are approx 2 MB in size on average.
Updated by Vitaliy Filippov over 5 years ago
Yes, I'm using EC with RBD and partial overwrites enabled. CephFS pools are only created recently for tests and do not hold any data.
RBDs are thin provisioned, biggest ones are one ~14TB base image and one ~2TB base image with several clones and snapshots. The supposed usage is to put a big DB in Ceph, create clones, run tests on the clones, then either discard failed clones or merge good clones back into the base image. I patched rbd export-diff to allow to export clone diffs without parent data for that, it works, however it's not yet integrated into our CI scripts.
RADOS objects are 4 MB (we didn't change RBD default), but probably split in 2 parts with EC...
As I understand, new RADOS objects are created when an RBD image (or even clone) is written to. So clients writing +1.3 TB should be noticeable on the graph (see attached picture). But according to the graph, clients have only written +200 objects in that time...
Even if we suppose that Bluestore is smart enough to share some data between objects of parent and child RBD images at OSD level (although it looks very nontrivial for me) and this connection breaks during rebalance and "COW" clones become not really "COW"... I think even this case shouldn't lead to +1.3TB storage increase, because I've recently been re-importing them into RBD using my patched rbd export-diff/import-diff and they occupied only ~100GB in total.
By the way, 1.3TB is Sunday's number, Monday's is +500GB more. I.e. now roughly the same amount of data as it was on Sunday morning uses 1.8TB more raw storage...
Updated by Vitaliy Filippov over 5 years ago
OK, I looked into OSD datastore using ceph-objectstore-tool and I see that for almost every object there are two copies, like:
2#13:080008d8:::rbd_data.15.3d3e1d6b8b4567.0000000000361a96:28# 2#13:080008d8:::rbd_data.15.3d3e1d6b8b4567.0000000000361a96:head#
And more interesting is the fact that these two copies don't differ (!).
So the space is taken up by unneeded snapshot copies.
rbd_data.15.3d3e1d6b8b4567 is the prefix of the biggest (14 TB) base image we have. This image has 1 snapshot:
[root@sill-01 ~]# rbd info rpool_hdd/rms-201807-golden
rbd image 'rms-201807-golden':
size 14 TiB in 3670016 objects
order 22 (4 MiB objects)
id: 3d3e1d6b8b4567
data_pool: ecpool_hdd
block_name_prefix: rbd_data.15.3d3e1d6b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten, data-pool
op_features:
flags:
create_timestamp: Tue Aug 7 13:00:10 2018
[root@sill-01 ~]# rbd snap ls rpool_hdd/rms-201807-golden
SNAPID NAME SIZE TIMESTAMP
37 initial 14 TiB Tue Aug 14 12:42:48 2018
The problem is this image has NEVER been written to after importing it to Ceph with RBD. All writes go only to its clones.
So I have 2 questions:
1) Why base image snapshot is "provisioned" while the image isn't written to? May it be related to `rbd snap revert`? (i.e. does rbd snap revert just copy all snapshot data into the image itself?)
2) If all parent snapshots seem to be forcefully provisioned on write: Is there a way to disable this behaviour? Maybe if I make the base image readonly its snapshots will stop to be "provisioned"?
3) Even if there is no way to disable it: why does Ceph create extra copy of equal snapshot data during rebalance?
4) What's ":28" in rados objects? Snapshot id is 37. Even in hex 0x28 = 40, not 37. Or does RADOS snapshot id not need to be equal to RBD snapshot ID?
5) Am I safe to "unprovision" the snapshot? (for example, by doing `rbd snap revert`?)
Updated by Vitaliy Filippov over 5 years ago
Oops. That's more than 2 questions. But anyway :)
Updated by Ben England over 5 years ago
- Project changed from Ceph to rbd
since you've identified that this is an RBD workload, assigning it to that project so that RBD team notices it. HTH.
Updated by Jason Dillaman over 5 years ago
- Project changed from rbd to RADOS
Back-and-forth question answering like this is probably better for the mailing list (the ticket is currently closed FYI).
Also moving this back to RADOS since it's not really related to RBD.
However, ...
Vitaliy Filippov wrote:
OK, I looked into OSD datastore using ceph-objectstore-tool and I see that for almost every object there are two copies, like:
[...]
And more interesting is the fact that these two copies don't differ (!).
So the space is taken up by unneeded snapshot copies.
rbd_data.15.3d3e1d6b8b4567 is the prefix of the biggest (14 TB) base image we have. This image has 1 snapshot:
[...]
The problem is this image has NEVER been written to after importing it to Ceph with RBD. All writes go only to its clones.
So I have 2 questions:
1) Why base image snapshot is "provisioned" while the image isn't written to? May it be related to `rbd snap revert`? (i.e. does rbd snap revert just copy all snapshot data into the image itself?)
If you run "rbd snap revert", you will copy all the data from the snapshot to the HEAD version.
2) If all parent snapshots seem to be forcefully provisioned on write: Is there a way to disable this behaviour? Maybe if I make the base image readonly its snapshots will stop to be "provisioned"?
Not sure what what you are referring to here.
3) Even if there is no way to disable it: why does Ceph create extra copy of equal snapshot data during rebalance?
I suspect it shouldn't.
4) What's ":28" in rados objects? Snapshot id is 37. Even in hex 0x28 = 40, not 37. Or does RADOS snapshot id not need to be equal to RBD snapshot ID?
Did you delete a snapshot on that image before w/ the snapshot id of 40?
5) Am I safe to "unprovision" the snapshot? (for example, by doing `rbd snap revert`?)
That's will only re-copy the data to the HEAD revision.
Updated by Vitaliy Filippov over 5 years ago
I suspect it shouldn't.
But it does exactly that.
That's will only re-copy the data to the HEAD revision.
And it seems it provisions the whole image, even non-written-to regions.
I'll try to reproduce both and file a more concrete bug.