Bug #3275
closedMonitors unable to recover after network line card replacement
0%
Description
Roughly around the time that several line cards were replaced the ceph monitors stopped working and were not able to recover on their own from the network event. Monitors returned to normal after restarting them, one OOM'd shortly after and needed to be started up one more time
2012-10-05 04:28:25.573948 mon.0 [2607:f298:4:2243::5752]:6789/0 2787133 : [INF] mon.peon5752 calling new monitor election
2012-10-05 04:28:31.257698 mon.0 [2607:f298:4:2243::5752]:6789/0 2787134 : [INF] mon.peon5752@0 won leader election with quorum 0,2
2012-10-05 04:28:32.148894 mon.0 [2607:f298:4:2243::5752]:6789/0 2787135 : [INF] mdsmap e1: 0/0/1 up
2012-10-05 04:28:32.192594 mon.0 [2607:f298:4:2243::5752]:6789/0 2787136 : [INF] osdmap e230741: 890 osds: 887 up, 887 in
2012-10-05 04:28:32.504294 mon.0 [2607:f298:4:2243::5752]:6789/0 2787137 : [INF] monmap e9: 3 mons at
{peon5752=[2607:f298:4:2243::5752]:6789/0,peon5753=[2607:f298:4:2243::5753]:6789/0,peon5754=[2607:f298:4:2243::5754]:6789/0}
2012-10-05 04:27:13.426198 mon.2 [2607:f298:4:2243::5754]:6789/0 157 : [INF] mon.peon5754 calling new monitor election
2012-10-05 04:27:23.809158 mon.2 [2607:f298:4:2243::5754]:6789/0 158 : [INF] mon.peon5754 calling new monitor election
2012-10-05 04:28:07.688839 mon.2 [2607:f298:4:2243::5754]:6789/0 159 : [INF] mon.peon5754 calling new monitor election
2012-10-05 04:28:35.863162 mon.0 [2607:f298:4:2243::5752]:6789/0 2787138 : [INF] pgmap v10558653: 133128 pgs: 133128 active+clean; 21779 GB data, 77777 GB used, 2120 TB / 2196 TB avail
2012-10-05 04:28:44.458902 mon.0 [2607:f298:4:2243::5752]:6789/0 2787139 : [INF] pgmap v10558654: 133128 pgs: 133128 active+clean; 21779 GB data, 77777 GB used, 2120 TB / 2196 TB avail
[4849886.685087] Out of memory: Kill process 8743 (ceph-mon) score 818 or sacrifice child
[4849886.685150] Killed process 8743 (ceph-mon) total-vm:10904880kB, anon-rss:2678320kB, file-rss:0kB
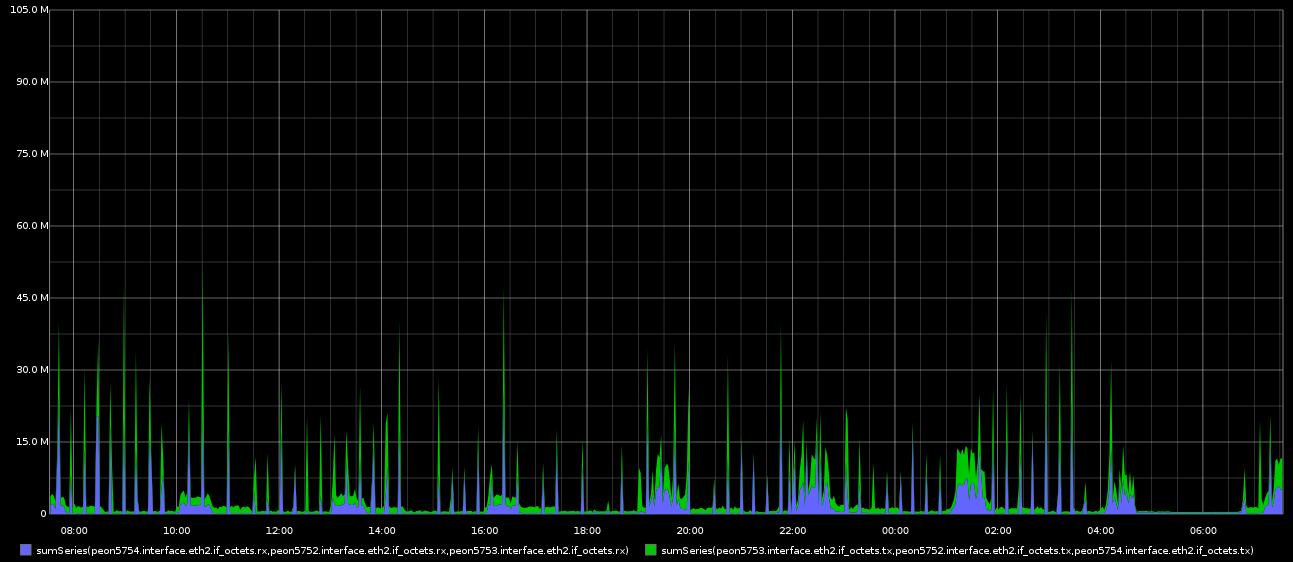
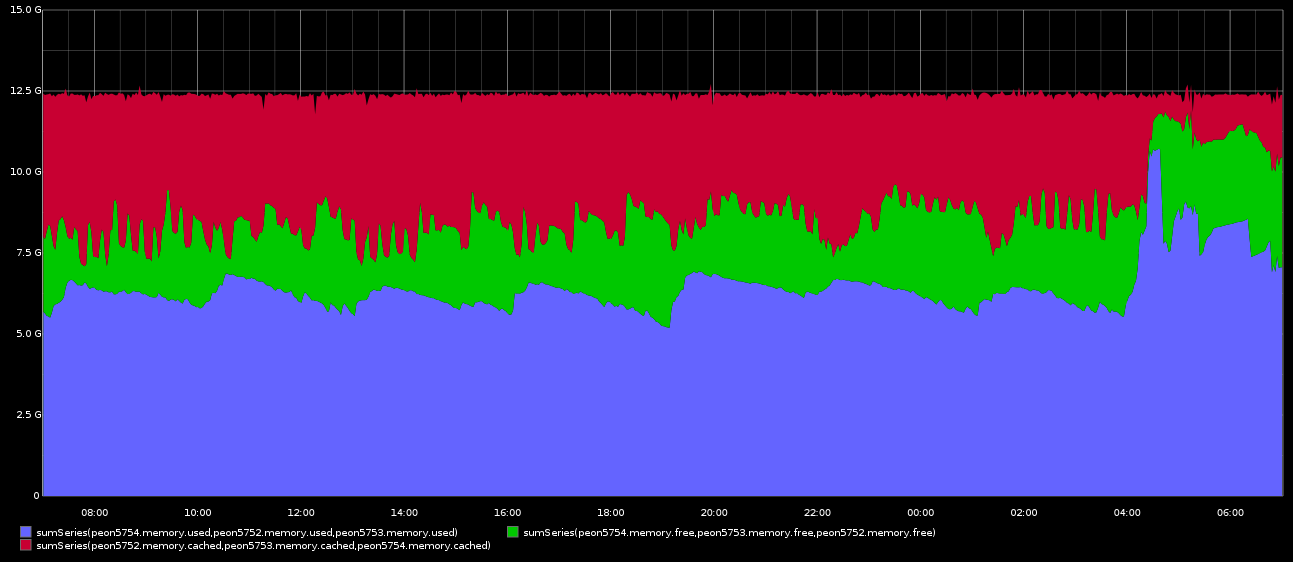
Attached are several graphs, I saved a copy of the cluster log in case that is useful as well.
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Updated by JuanJose Galvez over 11 years ago
I'm contacting Kyle about the log and will upload a copy to this bug as soon as I get it.
Updated by Joao Eduardo Luis over 11 years ago
On which version was this triggered on?
Updated by JuanJose Galvez over 11 years ago
Their cluster is currently running:
ceph version 0.48.1argonaut-9-g657ca11 (657ca118a7658617b9117311d9ee1cbe00103c06)
I should note that we're currently waiting to see if this issue repeats. Sage had responded with:
Looked at the logs. peon5752 and 5753 ceph-mon daemons crashed or stopped (logging stopped), but no core files were found. No other useful evidence. Came up when restarted.
We should:
- enable the core logging to /var/core
- change the log rotation to daily so that we have more history (disks are now huge)
- wait!
Updated by Sage Weil about 11 years ago
- Status changed from New to Can't reproduce