Bug #22523
closedJewel10.2.10 cephfs journal corrupt,later event jump into previous position.
0%
Description
Hi all.
==============================
version: jewel 10.2.10 (professional rpms)
nodes : 3 centos7.3
cephfs : kernel client
pool : meta:3 replicas(2ssd*3), data:2replicas(26HDD*3)
network: 10gbs( 2 *3)
================================
In a enviroument, we have a testing HA (pull out and inserting optical cable).
because of mds status changed, mds replay journal(want from standy to active),
mds throw exception:
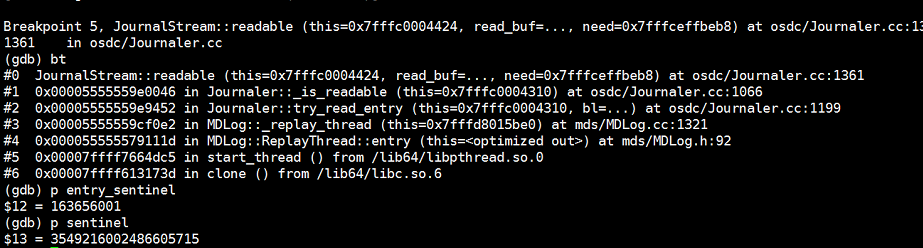
throw buffer::malformed_input("Invalid sentinel"); (src/osdc/Journaler.cc:1361)
all mds stop replay journal,and status stopped at standy. fs is not available ls/read/write
=================================
we used cephfs-journal-tool journal inspect found corrupet region.
cephfs-jounnal-tool event get list(add event time print)found the strange pos.:
event time:2017-12-16 03:50:32.543091
event time:2017-12-16 03:50:32.543180
event time:2017-12-16 03:50:32.543296
event time:2017-12-16 03:50:32.543393
event time:2017-12-16 03:50:32.543518
h1. event time:2017-12-16 03:14:44.205316
event time:2017-12-16 03:14:44.206388
event time:2017-12-16 03:14:44.207265
event time:2017-12-16 03:14:44.208103
there are 20 events(2017-12-16 03:50:32.*) before event 2017-12-16 03:14:44.
which should be display after 2017-12-16 03:50:31.*
======================
we erased the corrueption pos journal. mds coredump .
we modify two assert failed(osdmap version),and adjust argument (wip_session).
mds started, and fs is availalbe read and write.
==============
at last ,we changed to previous mds version. fs is ok.
but it seems like output so much dump inodes links.
======
journal and event list please referece to attachment file.
!!!!
!!!!!!
event list file :
h1. https://pan.baidu.com/s/1bo7rlwj
journal file:
h1. https://pan.baidu.com/s/1slV1zGh
Files
{kind=link}
{kind=link}
Updated by Jos Collin over 6 years ago
- Status changed from New to Need More Info
I don't see anything in the URLs provided. Additionally, this looks like a Support Case.
Updated by Yong Wang over 6 years ago
wangyong wang wrote:
Hi all. ==============================
version: jewel 10.2.10 (professional rpms)
nodes : 3 centos7.3
cephfs : kernel client
pool : meta:3 replicas(2ssd*3), data:2replicas(26HDD*3)
network: 10gbs( 2 *3) ================================
In a enviroument, we have a testing HA (pull out and inserting optical cable).
because of mds status changed, mds replay journal(want from standy to active),
mds throw exception:
throw buffer::malformed_input("Invalid sentinel"); (src/osdc/Journaler.cc:1361)all mds stop replay journal,and status stopped at standy. fs is not available ls/read/write
=================================
we used cephfs-journal-tool journal inspect found corrupet region.
cephfs-jounnal-tool event get list(add event time print)found the strange pos.:event time:2017-12-16 03:50:32.543091
event time:2017-12-16 03:50:32.543180
event time:2017-12-16 03:50:32.543296
event time:2017-12-16 03:50:32.543393
event time:2017-12-16 03:50:32.543518
h1. event time:2017-12-16 03:14:44.205316
event time:2017-12-16 03:14:44.206388
event time:2017-12-16 03:14:44.207265
event time:2017-12-16 03:14:44.208103there are 20 events(2017-12-16 03:50:32.*) before event 2017-12-16 03:14:44.
which should be display after 2017-12-16 03:50:31.*======================
we erased the corrueption pos journal. mds coredump .
we modify two assert failed(osdmap version),and adjust argument (wip_session).
mds started, and fs is availalbe read and write. ==============
at last ,we changed to previous mds version. fs is ok.
but it seems like output so much dump inodes links.======
journal and event list please referece to attachment file.
!!!!
!!!!!!event list file :
h1. https://pan.baidu.com/s/1bo7rlwjjournal file:
h1. https://pan.baidu.com/s/1slV1zGh
those below are journal event list and exported journal files.
Updated by Yong Wang over 6 years ago
Jos Collin wrote:
I don't see anything in the URLs provided. Additionally, this looks like a Support Case.
can you see buttion title like "下载46.7M" ?
https://pan.baidu.com/s/1bo7rlwj
https://pan.baidu.com/s/1slV1zGh
I can't upload those due to too large, is any something method?
Those faults effected mds can't work, and journal event time error,
corrupt region checked. I think it may be a* serious* bug.
I said HA just for why it happed.
Tks for your reply.
Updated by Zheng Yan over 6 years ago
- Project changed from Ceph to CephFS
- Category deleted (
129)
Updated by Zheng Yan over 6 years ago
please upload ceph cluster log. So I can check timestamp of mds failovers
Updated by 鹏 张 over 6 years ago
Zheng Yan wrote:
please upload ceph cluster log. So I can check timestamp of mds failovers
Dear zheng:
I have upload the log file. The first log happened in beijing time.the equation of time of second log is seven hours later.The event already occured twice up to now.First time occured is 2017-12-06 07:57. The second time is 2017-12-23 14:11. The second log we provided is added monitor by us to avoid journal damage.So you can not get more information about mds such as rank 0 damage.But you can get the useful message before journal damage.
链接:https://pan.baidu.com/s/1qYNwHXE
密码:c1c2
Updated by Zheng Yan over 6 years ago
can't any log for "2017-12-16". next time you do experiment,please set debug_ms=1 for mds
Updated by 鹏 张 over 6 years ago
Zheng Yan wrote:
can't any log for "2017-12-16". next time you do experiment,please set debug_ms=1 for mds
Dear zheng:
"2017-12-16"?”the mds log about "2017-12-06" is under the ducoment of node$numberlog.tar. It belong all ceph log about three node.I alwlays set the debug_ms = 1.You can see the ceph-mds.node1.log-20171207 of node1. It is the first time mds replay failed which occured at 07:57.
Updated by Zheng Yan over 6 years ago
can't find any 'osd_op ... write' in mds logs. So I can't find any clue how the corruption happened.
Updated by Yong Wang about 6 years ago
mds_blacklist_interval = 1440
We found that that arguments is too little for the HA testing, it should be adjusted large more.
Please help to closing this bug.
Tks a lot for YanZheng & Jos Collin .
Updated by Zheng Yan about 6 years ago
- Status changed from Need More Info to Closed