Bug #12979
closedCeph lost it's repair ability after repeatedly flapping
Description
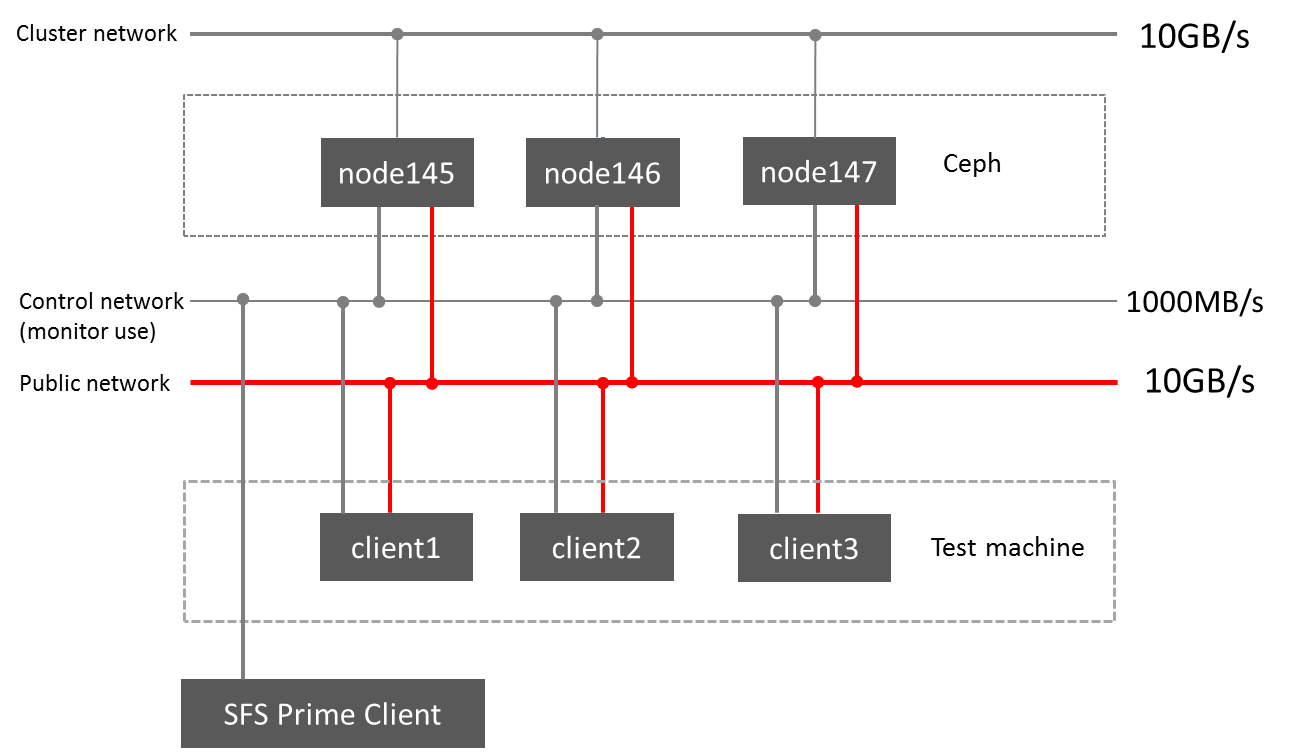
I have a ceph performance test cluster, you can see the ceph network diagram in the attachments(ceph-network-diagram.png).
It's state show as blow in the event of a problem before:
cluster 2f6f7e9e-9167-4ac5-889b-d18680fa4c04
health HEALTH_OK
monmap e1: 3 mons at {node145=172.16.38.145:6789/0,node146=172.16.38.146:6789/0,node147=172.16.38.147:6789/0}
election epoch 16, quorum 0,1,2 node145,node146,node147
osdmap e390: 63 osds: 63 up, 63 in
pgmap v28044: 2048 pgs, 2 pools, 258 GB data, 74552 objects
638 GB used, 69432 GB / 70070 GB avail
2048 active+clean
client io 822 MB/s wr, 2726 op/s
Then I have a test about ceph flapping, you can see more info in the official website:
I do it over and over again, make the cluster flapping by disable the cluster network card of one host, but the public network is enable.
my ceph.conf:
[global]
fsid = 2f6f7e9e-9167-4ac5-889b-d18680fa4c04
mon_initial_members = node145, node146, node147
mon_host = 172.16.38.145,172.16.38.146,172.16.38.147
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
filestore_xattr_use_omap = true
public network = 192.168.38.0/24
cluster network = 172.16.138.0/24 // I disabled this network of one host to make the cluster flapping
[client]
admin socket=/var/run/ceph/rbd-$pid-$name-$cctid.asok
log file = /var/log/ceph/ceph.client.admin.log
finally, I find the cluster can not repair it's self anymore.
I restart ceph-all in all the host(node145,node146,node147).
(1) at the begining it's ok, all osd is up.
(2) and 3 minutes after, two osd(A,B) is down.
(3) and another 5 minutes after, maybe A is up, and other osd(C,F,H) is down.
(4) and it's flapping a long time, may be 10 hours.
(5) at last, most osd is down, only few osd is up.
like this:
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 68.66977 root default
-2 22.88992 host node145
0 1.09000 osd.0 down 0 1.00000
1 1.09000 osd.1 down 0 1.00000
2 1.09000 osd.2 down 0 1.00000
3 1.09000 osd.3 down 0 1.00000
4 1.09000 osd.4 down 0 1.00000
5 1.09000 osd.5 down 0 1.00000
6 1.09000 osd.6 down 0 1.00000
7 1.09000 osd.7 down 0 1.00000
8 1.09000 osd.8 down 0 1.00000
9 1.09000 osd.9 down 0 1.00000
10 1.09000 osd.10 down 0 1.00000
11 1.09000 osd.11 down 0 1.00000
12 1.09000 osd.12 down 0 1.00000
13 1.09000 osd.13 down 0 1.00000
14 1.09000 osd.14 down 0 1.00000
15 1.09000 osd.15 down 0 1.00000
16 1.09000 osd.16 down 0 1.00000
17 1.09000 osd.17 down 0 1.00000
18 1.09000 osd.18 down 0 1.00000
19 1.09000 osd.19 down 0 1.00000
20 1.09000 osd.20 down 0 1.00000
-3 22.88992 host node146
21 1.09000 osd.21 down 0 1.00000
22 1.09000 osd.22 down 0 1.00000
23 1.09000 osd.23 down 1.00000 1.00000
24 1.09000 osd.24 down 1.00000 1.00000
25 1.09000 osd.25 down 0 1.00000
26 1.09000 osd.26 up 1.00000 1.00000
27 1.09000 osd.27 down 0 1.00000
28 1.09000 osd.28 down 0 1.00000
29 1.09000 osd.29 up 1.00000 1.00000
30 1.09000 osd.30 up 1.00000 1.00000
31 1.09000 osd.31 down 0 1.00000
32 1.09000 osd.32 up 1.00000 1.00000
33 1.09000 osd.33 down 0 1.00000
34 1.09000 osd.34 down 1.00000 1.00000
35 1.09000 osd.35 down 0 1.00000
36 1.09000 osd.36 down 0 1.00000
37 1.09000 osd.37 down 0 1.00000
38 1.09000 osd.38 down 0 1.00000
39 1.09000 osd.39 down 0 1.00000
40 1.09000 osd.40 down 1.00000 1.00000
41 1.09000 osd.41 down 1.00000 1.00000
-4 22.88992 host node147
42 1.09000 osd.42 down 1.00000 1.00000
43 1.09000 osd.43 down 0 1.00000
44 1.09000 osd.44 up 1.00000 1.00000
45 1.09000 osd.45 down 0 1.00000
46 1.09000 osd.46 down 0 1.00000
47 1.09000 osd.47 up 1.00000 1.00000
48 1.09000 osd.48 up 1.00000 1.00000
49 1.09000 osd.49 down 0 1.00000
50 1.09000 osd.50 up 1.00000 1.00000
51 1.09000 osd.51 down 0 1.00000
52 1.09000 osd.52 up 1.00000 1.00000
53 1.09000 osd.53 down 0 1.00000
54 1.09000 osd.54 up 1.00000 1.00000
55 1.09000 osd.55 up 1.00000 1.00000
56 1.09000 osd.56 up 1.00000 1.00000
57 1.09000 osd.57 up 1.00000 1.00000
58 1.09000 osd.58 up 1.00000 1.00000
59 1.09000 osd.59 up 1.00000 1.00000
60 1.09000 osd.60 up 1.00000 1.00000
61 1.09000 osd.61 up 1.00000 1.00000
62 1.09000 osd.62 up 1.00000 1.00000
and the "ceph -s" print:
cluster 2f6f7e9e-9167-4ac5-889b-d18680fa4c04
health HEALTH_WARN
3 pgs degraded
898 pgs down
1021 pgs peering
446 pgs stale
3 pgs stuck degraded
1024 pgs stuck inactive
397 pgs stuck stale
1024 pgs stuck unclean
3 pgs stuck undersized
3 pgs undersized
5459 requests are blocked > 32 sec
8/26 in osds are down
monmap e1: 3 mons at {node145=172.16.38.145:6789/0,node146=172.16.38.146:6789/0,node147=172.16.38.147:6789/0}
election epoch 570, quorum 0,1,2 node145,node146,node147
osdmap e32575: 63 osds: 18 up, 26 in; 4 remapped pgs
pgmap v506758: 1024 pgs, 1 pools, 18 bytes data, 1 objects
30706 MB used, 21102 GB / 21132 GB avail
386 stale+down+peering
294 down+peering
218 creating+down+peering
56 stale+peering
41 creating+peering
22 peering
3 stale+remapped+peering
1 undersized+degraded+peered
1 activating+undersized+degraded
1 remapped+peering
1 stale+activating+undersized+degraded
And I uploading the log of three host, hope that helps.
Files
{kind=link}
Updated by bo cai over 8 years ago
sorry, My Company limited the network, I need to do some processing and later upload the log file.
Updated by Sage Weil over 8 years ago
- Status changed from New to Need More Info
bo cai wrote:
sorry, My Company limited the network, I need to do some processing and later upload the log file.
You can use 'ceph-post-file <dir or file>' to upload the logs.
Thanks!
Updated by bo cai over 8 years ago
I try to upload the file in home, but I get a nginx error: "413 Request Entity Too Large"
Is this redmine can not upload large file(18M)?
I upload the log file here:
https://github.com/caibo2014/CC
Updated by bo cai over 8 years ago
Sage Weil wrote:
bo cai wrote:
sorry, My Company limited the network, I need to do some processing and later upload the log file.
You can use 'ceph-post-file <dir or file>' to upload the logs.
Thanks!
Thank you for your suggestion.
I try to use this command , but the following error occurred?
/usr/bin/ceph-post-file: upload tag 03f8a1f3-5ff7-4c53-8f07-41ce641bf663
/usr/bin/ceph-post-file: user: cai.bo@h3c.com
/usr/bin/ceph-post-file: will upload file ceph-lost-repair-ability-log.rar
ssh_exchange_identification: Connection closed by remote host
Couldn't read packet: Connection reset by peer
But I find another way to upload the log file , upload it to my github.
https://github.com/caibo2014/CC
By the way,Redmine seems like can not upload large files , though it shows that they can upload files 70M.
Updated by Sage Weil over 8 years ago
- Status changed from Need More Info to Closed
from the logs this looks like a networking problem:
2015-09-06 09:39:38.124069 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.0 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124090 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.1 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124116 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.2 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124124 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.3 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124131 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.4 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124138 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.5 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124144 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.6 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124151 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.7 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124164 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.8 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124171 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.9 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124178 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.10 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124197 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.11 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124204 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.12 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124211 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.14 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124219 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.15 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124225 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.16 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124232 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.17 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124239 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.18 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067) 2015-09-06 09:39:38.124248 7f361bb43700 -1 osd.42 29309 heartbeat_check: no reply from osd.20 ever on either front or back, first ping sent 2015-09-06 09:39:07.506021 (cutoff 2015-09-06 09:39:18.124067)
it can't talk to any other osd on either the cluster or client network (not sure which without higher log level). make sure your machines can all reach each other...
Updated by bo cai over 8 years ago
Sage Weil wrote:
from the logs this looks like a networking problem:
[...]
it can't talk to any other osd on either the cluster or client network (not sure which without higher log level). make sure your machines can all reach each other...
I am sure the network is ok.
I think the reason of osd.1 dose not reply is osd.1 is killed by osd.42 obliquely.
Updated by bo cai over 8 years ago
In order to more clearly illustrate this problem , I 'll build a very simple cluster, only have one monitor and three osd.
For eaxmple, On the three hosts three hosts: osd.1, osd.2, osd.3 , respectively.
Then I disable the cluster network of osd.3's host, sometime(about 30%) you will see finally osd.3 kill osd.1 and osd.2.
In practice, however , it should be osd.3 die, is not it?
I will upload our testing log later...
Updated by Greg Farnum over 8 years ago
It sounds like you need to adjust the mon_osd_min_down_reporters (default apparently 1) and mon_osd_min_down_reports (default 3) values so that a single node can't mark down all the other OSDs. We generally recommend that for multi-node systems the mon_osd_min_down_reporters be set to 1 more than the number of OSDs in a node.