Bug #65656
openReduce default thread pool size
0%
Description
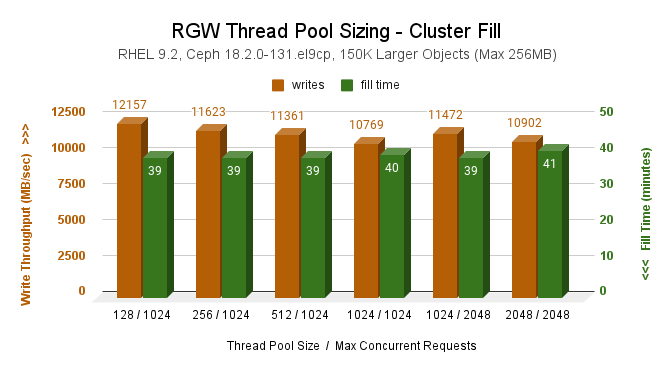
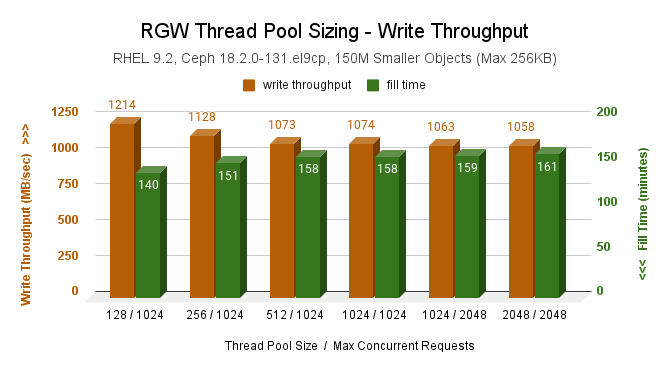
Our recent RGW thread pool size profiling (RHEL 9.2, Ceph 18.2.0-131) revealed that for both smaller (max 256KB) and larger (max 256MB) object sizes, the default rgw_thread_pool_size and rgw_max_concurrent_requests settings of 512 & 1024 do not achieve optimal throughput for the cluster fill (write only). That workload performed better (7% for small and 12% for larger objs) with a smaller thread pool of 128. For hybrid workloads (reads, writes, stats, deletes), altering either setting had no discernable impact on throughput performance.
Files
{kind=link}
{kind=link}
Updated by Tim Wilkinson 10 days ago
Test env:
---------
3x MON/MGR nodes
Dell R630
2x E5-2683 v3 (28 total cores, 56 threads)
128 GB RAM
8x OSD/RGW nodes
Supermicro 6048R
2x Intel E5-2660 v4 (28 total cores, 56 threads)
256 GB RAM
192x OSDs (bluestore): 24 2TB HDD and 2x 800G NVMe for WAL/DB per node
Pool: default.rgw.buckets.data = EC 4+2
5x Dell R630 driver nodes each running multiple warp clients
Pool Sizing (PGs)
4096 data
256 index
128 log/control/meta
Non-default cluster settings
----------------------------
log_to_file true
mon_cluster_log_to_file true
osd_memory_target 7877291758
osd_memory_target_autotune false
OSD node swap disabled
ceph balancer off
noscrub, nodeep-scrub
Updated by Casey Bodley 9 days ago
- Subject changed from Thread pool size benchmarking to Reduce default thread pool size
Updated by Casey Bodley 3 days ago
- Status changed from New to Fix Under Review
- Pull request ID set to 57167