Bug #38738
closedceph ssd osd latency increase over time, until restart
0%
Description
We register disk latency for VMs on SSD pool increase over time.
The VM disk latency normally is 0.5-3 ms.
The VM disk latency worst cases is 50-500 ms.
Even small load (20-30 Mbyte/s) in that case can significally increase disk latences for all VMs.
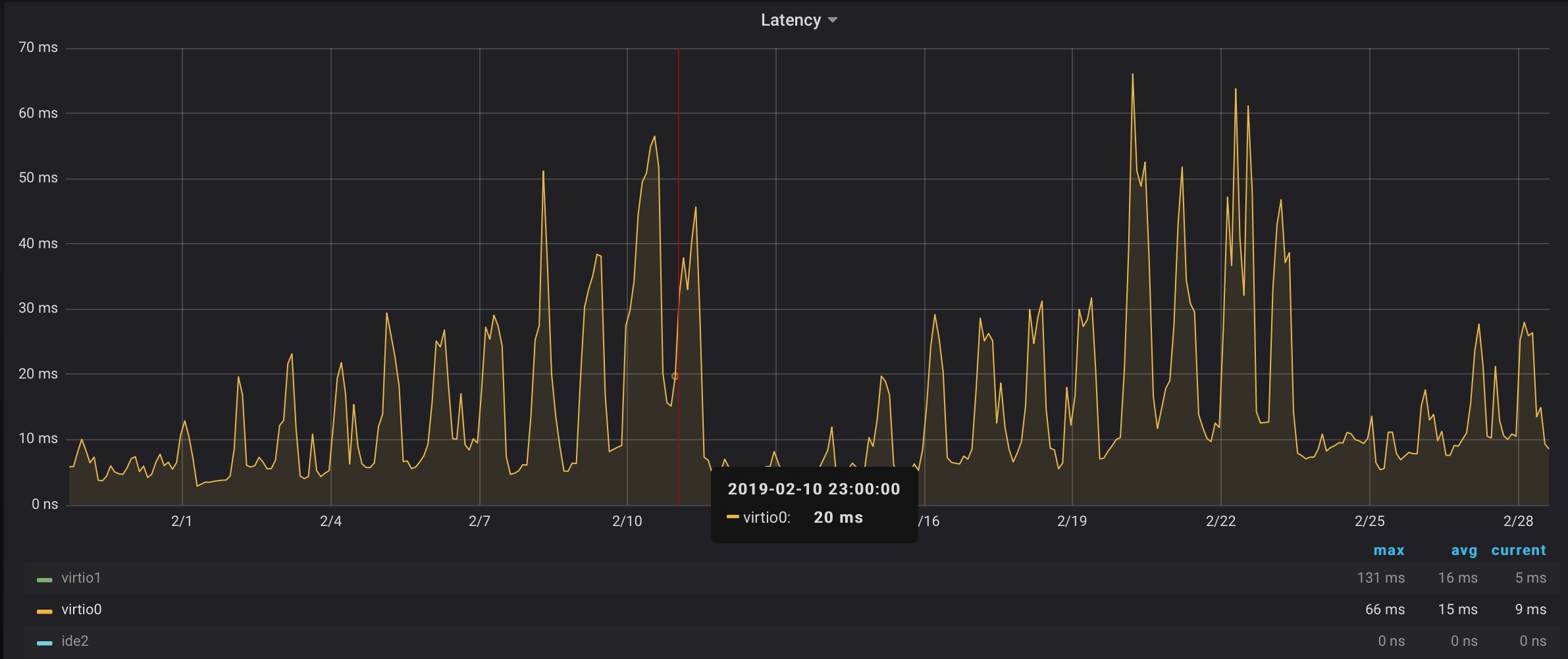
The attached picture represents latency for one of the VMs (VM on KVM ssd rbd pool) in one month.
the disk latencies of all VMs are rising up when the backup on one of the servers is started (It reads 25 Mbyte/s and writes 25 Mbyte/s simultaneously).
And every next day the latencies are higher than in the previous day (during the backup process).
Somtimes simple file copying leads to the same effect.
The same situation is observed on all of the servers.
The OSD restart reduces disk latencies only temporarly.
After 30 minutes from the restart the same backup doesn't increase disk latencies of other VMs.
After 24 hours from the restart the same backup increases disk latencies of other VMs.
We have checked network. Network speed is 10 Gbit/s. The ports utilization is 50-200 Mbit/s
We have checked SSD. util=5-10%. svctime, rawait,wawait are very small.
We have checked CPU. USR + SYS = 10-15%
We observed osd perf at time of high latencies (see the following ssd_root):
ceph osd perf | grep -E "^ 39|^ 12|^ 24|^ 3|^ 16|^ 42|^ 27|^ 64|^ 29|^ 9|^ 18|^ 61|^ 55|^ 45|^ 54|^ 65|^ 6 |^ 51" | sort -n
3 8 8
6 0 0
9 5 5
12 55 55
16 2 2
18 0 0
24 5 5
27 15 15
29 0 0
39 13 13
42 0 0
45 0 0
51 1 1
54 1 1
55 3 3
61 1 1
64 1 1
65 1 1
In other situations where such high latencies occured, al thel OSDs from this tree had 0 values, but one or two OSDs had 10-60 ms latencies.
One of the OSDs has high commit_latency for several seconds, then another OSD, then another one.
In a normal situation commit_latency (ms) and apply_latency (ms) are all 0.
We ran perf top -p `pidof osd.65` during high latencies:
Samples: 185K of event 'cycles:ppp', Event count (approx.): 18527322443
Overhead Shared Object Symbol ◆
30.14% ceph-osd [.] btree::btree_iterator<btree::btree_node<btree::btree_map_params<unsigned long, unsigned long, std::less<unsigned long>, mempool::pool_allocator<(mempool::pool_index_t)1, std::pair<unsigned long▒
24.90% ceph-osd [.] StupidAllocator::_aligned_len ▒
18.25% ceph-osd [.] StupidAllocator::allocate_int ▒
1.44% libtcmalloc.so.4.2.6 [.] operator new ▒
1.03% ceph-osd [.] crc32_iscsi_00 ▒
We use tcmalloc library.
All ceph-osd processes have the environment variable:
cat /proc/${pid}/environ
one of them is:
TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES=134217728
We use:
ceph version 12.2.7 (3ec878d1e53e1aeb47a9f619c49d9e7c0aa384d5) luminous (stable)
Our SSDs are:
3.8TBytes
used 78%
bluestore.
We have found the same issue on ceph 13.2.1:
https://www.spinics.net/lists/ceph-devel/msg44274.html
But we did't find any solution for the issue of high latencies.
Files
{kind=link}
{kind=link}
Updated by Igor Fedotov about 5 years ago
- Status changed from New to 12
Anton,
there is a thread named "ceph osd commit latency increase over time, until
restart" at ceph-users mail list which covers similar issue.
In short it looks like StupidAllocator fragmentation which increases over time.
I've got a POC patch to reset it periodically - https://github.com/ceph/ceph/commits/wip-ifed-reset-allocator-luminous.
But this is to prove the above analysis rather than the final fix.
Currently the idea is to backport new bitmap allocator to Luminous as a final solution. Will do once the above is confirmed.
Updated by hoan nv about 5 years ago
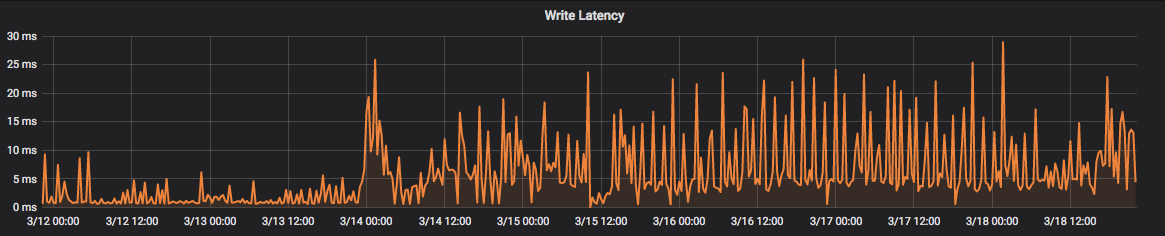
- File Grafana - Thor-Storage 2019-03-18 22-13-13.png Grafana - Thor-Storage 2019-03-18 22-13-13.png added
i have same issue
Updated by hoan nv about 5 years ago
hoan nv wrote:
i have same issue
Version's ceph is 13.2.2
Updated by hoan nv about 5 years ago
do you have temporary solutions for this issue.
I tried move device class from ssd to hdd but no luck.
My cluster have 2 pool but only ssd has slow latency.
Thanks
Updated by Igor Fedotov about 5 years ago
hoan nv wrote:
do you have temporary solutions for this issue.
I tried move device class from ssd to hdd but no luck.
My cluster have 2 pool but only ssd has slow latency.
Thanks
New bitmap allocator backports are coming:
https://github.com/ceph/ceph/pull/26979
https://github.com/ceph/ceph/pull/26983
Hopefully they'll fix the issue.
Updated by Igor Fedotov about 5 years ago
- Pull request ID set to 26983
- Affected Versions v13.2.1 added
Updated by Igor Fedotov about 5 years ago
- Status changed from In Progress to Resolved
Updated by Igor Fedotov about 5 years ago
The solution is to switch to new bitmap allocator that has been merged into both luminous and mimic.