Bug #2219
closedOSD's commit suicide with 0.44
0%
Description
I noticed this myself today, but on IRC somebody else came along:
13:01 -!- mgalkiewicz [~mgalkiewi@194.28.49.118] has joined #ceph 13:05 < mgalkiewicz> Hello guys. I have a problem with dying osd http://pastie.org/3677343. I am using ceph 0.44.
This is what I saw in my logs:
2012-03-27 13:40:44.343841 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:499c]:0/16305 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x4a6728c0 con 0x49fc1b40 2012-03-27 13:40:44.343909 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:499c]:0/16405 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x30943c40 con 0x2546b40 2012-03-27 13:40:44.343974 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:499c]:0/16541 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x30f5c8c0 con 0x3dac5a00 2012-03-27 13:40:44.344040 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:498e]:0/10603 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x4c561c0 con 0x2e768c0 2012-03-27 13:40:44.344103 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:498e]:0/12398 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x4c960a80 con 0x3dac5640 2012-03-27 13:40:44.344166 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:498e]:0/10920 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x331bc40 con 0x2546780 2012-03-27 13:40:44.344232 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:498e]:0/11019 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x64f2a80 con 0x36e2140 2012-03-27 13:40:44.344297 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:49a4]:0/6223 -- osd_ping(heartbeat e0 as_of 27747) v1 -- ?+0 0x36b5e1c0 con 0x36e23c0 2012-03-27 13:40:44.344361 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:49a4]:0/6295 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x8fc6540 con 0x4a14aa00 2012-03-27 13:40:44.344423 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:49a4]:0/6369 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x344e5000 con 0x3dac58c0 2012-03-27 13:40:44.344487 7f541920a700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:6813/2579 --> [2a00:f10:11b:cef0:225:90ff:fe33:49a4]:0/6445 -- osd_ping(heartbeat e0 as_of 27658) v1 -- ?+0 0x34af8380 con 0xe93ca00 2012-03-27 13:40:44.377585 7f541db14700 -- [2a00:f10:11b:cef0:225:90ff:fe32:cf64]:0/2579 <== osd.29 [2a00:f10:11b:cef0:225:90ff:fe33:499c]:6802/16305 9958 ==== osd_ping(heartbeat e27757 as_of 27653) v1 ==== 39+0+0 (3980489496 0 0) 0x21749000 con 0x323fc80 2012-03-27 13:40:44.402194 7f5429b2c700 heartbeat_map is_healthy 'FileStore::op_tp thread 0x7f542131b700' had timed out after 60 2012-03-27 13:40:44.402264 7f5429b2c700 heartbeat_map is_healthy 'FileStore::op_tp thread 0x7f542131b700' had suicide timed out after 180 common/HeartbeatMap.cc: In function 'bool ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, const char*, time_t)' thread 7f5429b2c700 time 2012-03-27 13:40:44.402360 common/HeartbeatMap.cc: 78: FAILED assert(0 == "hit suicide timeout") ceph version 0.44-70-gc3dc6a6 (commit:c3dc6a6ebf0fc42dad3989a7e0f8a4184f93d396) 1: (ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, char const*, long)+0x21d) [0x766d0d] 2: (ceph::HeartbeatMap::is_healthy()+0x87) [0x7674e7] 3: (ceph::HeartbeatMap::check_touch_file()+0x16) [0x767706] 4: (CephContextServiceThread::entry()+0x57) [0x69a987] 5: (()+0x7efc) [0x7f542b7f6efc] 6: (clone()+0x6d) [0x7f5429e2789d] ceph version 0.44-70-gc3dc6a6 (commit:c3dc6a6ebf0fc42dad3989a7e0f8a4184f93d396) 1: (ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, char const*, long)+0x21d) [0x766d0d] 2: (ceph::HeartbeatMap::is_healthy()+0x87) [0x7674e7] 3: (ceph::HeartbeatMap::check_touch_file()+0x16) [0x767706] 4: (CephContextServiceThread::entry()+0x57) [0x69a987] 5: (()+0x7efc) [0x7f542b7f6efc] 6: (clone()+0x6d) [0x7f5429e2789d] *** Caught signal (Aborted) ** in thread 7f5429b2c700 ceph version 0.44-70-gc3dc6a6 (commit:c3dc6a6ebf0fc42dad3989a7e0f8a4184f93d396) 1: /usr/bin/ceph-osd() [0x6fd3f6] 2: (()+0x10060) [0x7f542b7ff060] 3: (gsignal()+0x35) [0x7f5429d7c3a5] 4: (abort()+0x17b) [0x7f5429d7fb0b] 5: (__gnu_cxx::__verbose_terminate_handler()+0x11d) [0x7f542a63ad7d] 6: (()+0xb9f26) [0x7f542a638f26] 7: (()+0xb9f53) [0x7f542a638f53] 8: (()+0xba04e) [0x7f542a63904e] 9: (ceph::__ceph_assert_fail(char const*, char const*, int, char const*)+0x200) [0x691b40] 10: (ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, char const*, long)+0x21d) [0x766d0d] 11: (ceph::HeartbeatMap::is_healthy()+0x87) [0x7674e7] 12: (ceph::HeartbeatMap::check_touch_file()+0x16) [0x767706] 13: (CephContextServiceThread::entry()+0x57) [0x69a987] 14: (()+0x7efc) [0x7f542b7f6efc] 15: (clone()+0x6d) [0x7f5429e2789d]
Within about 5 minutes I lost somewhere around 13 OSD's to this.
I first thought it was btrfs to blame, but on none of the OSD's I saw btrfs messages or whatsoever.
My machines are running 3.2.0 (from a couple of weeks ago), I don't know what mgalkiewicz is running.
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Updated by Wido den Hollander about 12 years ago
15:00 < mgalkiewicz> wido: 2.6.32-5 15:00 < mgalkiewicz> wido: not sure how to check btrfs 15:00 -!- joao [~JL@89.181.151.120] has joined #ceph 15:02 < wido> mgalkiewicz: Ok, 2.6.32, tnx :) 15:02 < wido> I'll add to the issue 15:02 < wido> are you running btrfs or ext4? 15:02 < mgalkiewicz> wido: btrfs
Updated by Sage Weil about 12 years ago
- Status changed from New to Need More Info
Can you look at the core file and 'thread apply all bt'?
Updated by Wido den Hollander about 12 years ago
I accidentally removed the core file(s) :(
Hope this one pops up again so I have a core file.
Updated by Sage Weil about 12 years ago
- Status changed from Need More Info to Can't reproduce
Let us know if you see this again! Thanks
Updated by Eric Dold almost 12 years ago
I just hit this with v0.47.1:
2012-05-23 13:33:08.958564 7fe61124d700 -1 common/HeartbeatMap.cc: In function 'bool ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, const char*, time_t)' thread 7fe61124d700 time 2012-05-23 13:33:06.572705
common/HeartbeatMap.cc: 78: FAILED assert(0 == "hit suicide timeout")ceph version 0.47.1 (commit:f5a9404445e2ed5ec2ee828aa53d73d4a002f7a5)
1: (ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, char const*, long)+0x460) [0x82a800]
2: (ceph::HeartbeatMap::is_healthy()+0x87) [0x82ae27]
3: (ceph::HeartbeatMap::check_touch_file()+0x23) [0x82b063]
4: (CephContextServiceThread::entry()+0x54) [0x7ad054]
5: (()+0x8ec6) [0x7fe6130a3ec6]
6: (clone()+0x6d) [0x7fe611d5051d]Updated by Sage Weil almost 12 years ago
Eric Dold wrote:
I just hit this with v0.47.1:
2012-05-23 13:33:08.958564 7fe61124d700 -1 common/HeartbeatMap.cc: In function 'bool ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, const char*, time_t)' thread 7fe61124d700 time 2012-05-23 13:33:06.572705
common/HeartbeatMap.cc: 78: FAILED assert(0 == "hit suicide timeout")ceph version 0.47.1 (f5a9404445e2ed5ec2ee828aa53d73d4a002f7a5)
1: (ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, char const*, long)+0x460) [0x82a800]
2: (ceph::HeartbeatMap::is_healthy()+0x87) [0x82ae27]
3: (ceph::HeartbeatMap::check_touch_file()+0x23) [0x82b063]
4: (CephContextServiceThread::entry()+0x54) [0x7ad054]
5: (()+0x8ec6) [0x7fe6130a3ec6]
6: (clone()+0x6d) [0x7fe611d5051d]
Anything in the kernel log (dmesg output)?
Updated by Sage Weil almost 12 years ago
Eric Dold wrote:
dmesg looks ok to me.
was the system heavily loaded?
do you have a core file?
this basically means that the daemon was stucking doing some writes to the fs for 600 seconds.. which usually indicates that the file system broke, in which case you'll usually see kernel messages. it depends on what debug options are enabled for your kernel, though.
if you have a core file, we could see what syscall we were stuck on. my guess, though, is a kernel issue.
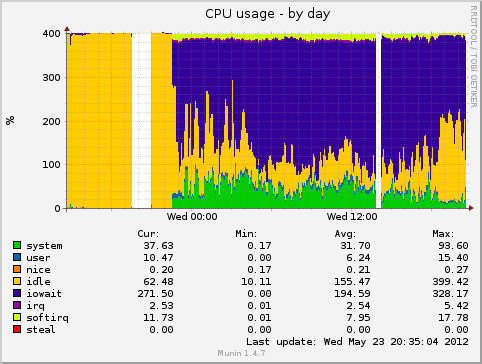
Updated by Eric Dold almost 12 years ago
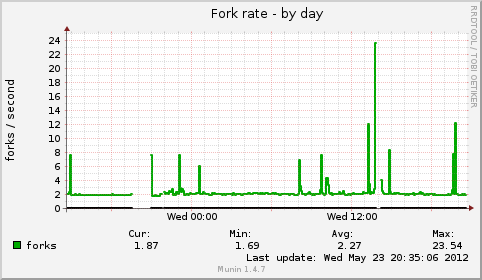
- File forks-day.png forks-day.png added
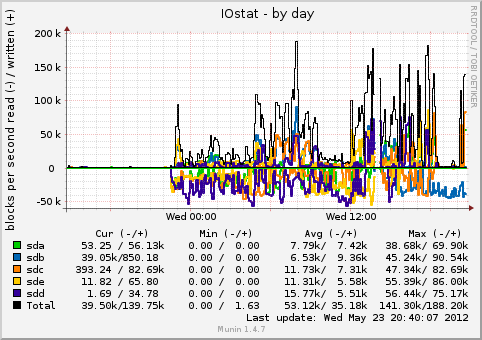
- File iostat-day.png iostat-day.png added
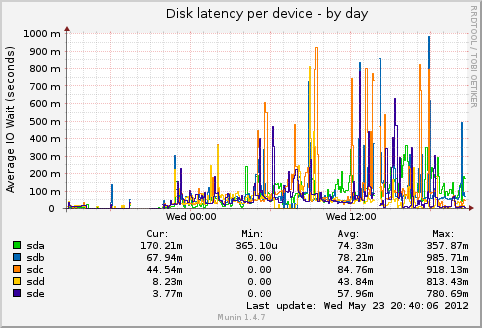
- File diskstats_latency-day.png diskstats_latency-day.png added
- File memory-day.png memory-day.png added
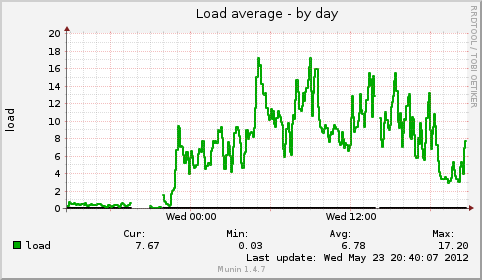
- File load-day.png load-day.png added
- File cpu-day.png cpu-day.png added
i added one node to my small test cluster. it has now totally three nodes. so rados is filling the new node.
the machine was not very responsive, but it was not that bad.
i had the bug on both old machines. not the new one.
the nodes have an intel i3 with 4 sata drives as osds (one osd per drive, btrfs). a ssd with 4 journal partitions and the system partitions. 8gb memory.
the kernel version is 3.4.0.
maybe it was the btrfs degradation. btrfs-clean was on the top in iotop.
sadly i have no coredump. but in the next few days i'll add another machine. i hope to catch it then.