Bug #18924
closedkraken-bluestore 11.2.0 memory leak issue
0%
Description
Hi All,
On all our 5 node cluster with ceph 11.2.0 we encounter memory leak issues.
Cluster details : 5 node with 24/68 disk per node , EC : 4+1 , RHEL 7.2
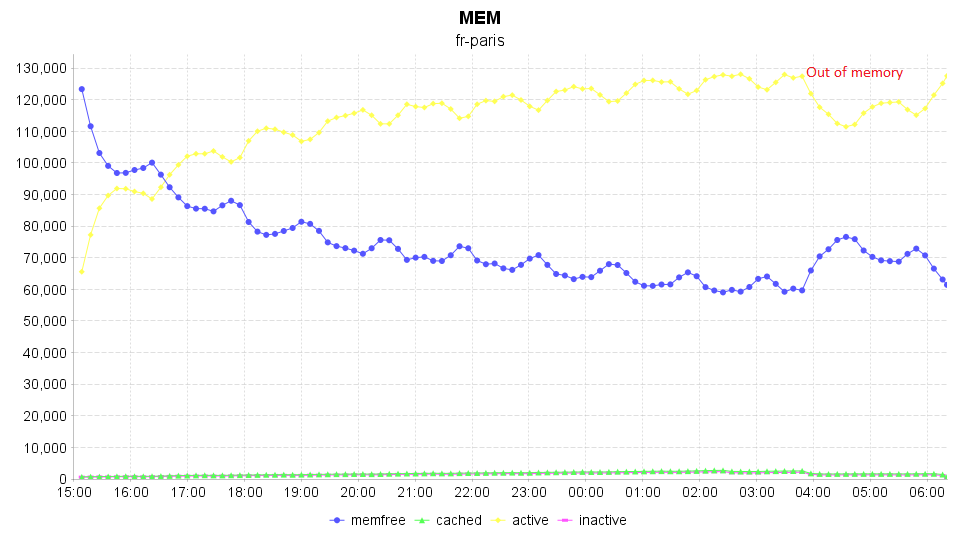
Some traces using sar are below and attached the memory utilisation graph .
(16:54:42)[cn2.c1 sa] # sar -r
07:50:01 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
10:20:01 32077264 132754368 80.54 16176 3040244 77767024 47.18 51991692 2676468 260
10:30:01 32208384 132623248 80.46 16176 3048536 77832312 47.22 51851512 2684552 12
10:40:01 32067244 132764388 80.55 16176 3059076 77832316 47.22 51983332 2694708 264
10:50:01 30626144 134205488 81.42 16176 3064340 78177232 47.43 53414144 2693712 4
11:00:01 28927656 135903976 82.45 16176 3074064 78958568 47.90 55114284 2702892 12
11:10:01 27158548 137673084 83.52 16176 3080600 80553936 48.87 56873664 2708904 12
11:20:01 26455556 138376076 83.95 16176 3080436 81991036 49.74 57570280 2708500 8
11:30:01 26002252 138829380 84.22 16176 3090556 82223840 49.88 58015048 2718036 16
11:40:01 25965924 138865708 84.25 16176 3089708 83734584 50.80 58049980 2716740 12
11:50:01 26142888 138688744 84.14 16176 3089544 83800100 50.84 57869628 2715400 16
...
...
In the attached graph, there is increase in memory utilisation by ceph-osd during soak test. And when it reaches the system limit of 128GB RAM , we could able to see the below dmesg logs related to memory out when the system reaches close to 128GB RAM. OSD.3 killed due to Out of memory and started again.
[Tue Feb 14 03:51:02 2017] tp_osd_tp invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0
[Tue Feb 14 03:51:02 2017] tp_osd_tp cpuset=/ mems_allowed=0-1
[Tue Feb 14 03:51:02 2017] CPU: 20 PID: 11864 Comm: tp_osd_tp Not tainted 3.10.0-327.13.1.el7.x86_64 #1
[Tue Feb 14 03:51:02 2017] Hardware name: HP ProLiant XL420 Gen9/ProLiant XL420 Gen9, BIOS U19 09/12/2016
[Tue Feb 14 03:51:02 2017] ffff8819ccd7a280 0000000030e84036 ffff881fa58f7528 ffffffff816356f4
[Tue Feb 14 03:51:02 2017] ffff881fa58f75b8 ffffffff8163068f ffff881fa3478360 ffff881fa3478378
[Tue Feb 14 03:51:02 2017] ffff881fa58f75e8 ffff8819ccd7a280 0000000000000001 000000000001f65f
[Tue Feb 14 03:51:02 2017] Call Trace:
[Tue Feb 14 03:51:02 2017] [<ffffffff816356f4>] dump_stack+0x19/0x1b
[Tue Feb 14 03:51:02 2017] [<ffffffff8163068f>] dump_header+0x8e/0x214
[Tue Feb 14 03:51:02 2017] [<ffffffff8116ce7e>] oom_kill_process+0x24e/0x3b0
[Tue Feb 14 03:51:02 2017] [<ffffffff8116c9e6>] ? find_lock_task_mm+0x56/0xc0
[Tue Feb 14 03:51:02 2017] [<ffffffff8116d6a6>] out_of_memory+0x4b6/0x4f0
[Tue Feb 14 03:51:02 2017] [<ffffffff81173885>] __alloc_pages_nodemask+0xa95/0xb90
[Tue Feb 14 03:51:02 2017] [<ffffffff811b792a>] alloc_pages_vma+0x9a/0x140
[Tue Feb 14 03:51:02 2017] [<ffffffff811976c5>] handle_mm_fault+0xb85/0xf50
[Tue Feb 14 03:51:02 2017] [<ffffffff811957fb>] ? follow_page_mask+0xbb/0x5c0
[Tue Feb 14 03:51:02 2017] [<ffffffff81197c2b>] __get_user_pages+0x19b/0x640
[Tue Feb 14 03:51:02 2017] [<ffffffff8119843d>] get_user_pages_unlocked+0x15d/0x1f0
[Tue Feb 14 03:51:02 2017] [<ffffffff8106544f>] get_user_pages_fast+0x9f/0x1a0
[Tue Feb 14 03:51:02 2017] [<ffffffff8121de78>] do_blockdev_direct_IO+0x1a78/0x2610
[Tue Feb 14 03:51:02 2017] [<ffffffff81218c40>] ? I_BDEV+0x10/0x10
[Tue Feb 14 03:51:02 2017] [<ffffffff8121ea65>] __blockdev_direct_IO+0x55/0x60
[Tue Feb 14 03:51:02 2017] [<ffffffff81218c40>] ? I_BDEV+0x10/0x10
[Tue Feb 14 03:51:02 2017] [<ffffffff81219297>] blkdev_direct_IO+0x57/0x60
[Tue Feb 14 03:51:02 2017] [<ffffffff81218c40>] ? I_BDEV+0x10/0x10
[Tue Feb 14 03:51:02 2017] [<ffffffff8116af63>] generic_file_aio_read+0x6d3/0x750
[Tue Feb 14 03:51:02 2017] [<ffffffffa038ad5c>] ? xfs_iunlock+0x11c/0x130 [xfs]
[Tue Feb 14 03:51:02 2017] [<ffffffff811690db>] ? unlock_page+0x2b/0x30
[Tue Feb 14 03:51:02 2017] [<ffffffff81192f21>] ? __do_fault+0x401/0x510
[Tue Feb 14 03:51:02 2017] [<ffffffff8121970c>] blkdev_aio_read+0x4c/0x70
[Tue Feb 14 03:51:02 2017] [<ffffffff811ddcfd>] do_sync_read+0x8d/0xd0
[Tue Feb 14 03:51:02 2017] [<ffffffff811de45c>] vfs_read+0x9c/0x170
[Tue Feb 14 03:51:02 2017] [<ffffffff811df182>] SyS_pread64+0x92/0xc0
[Tue Feb 14 03:51:02 2017] [<ffffffff81645e89>] system_call_fastpath+0x16/0x1b
Feb 14 03:51:40 fr-paris kernel: Out of memory: Kill process 7657 (ceph-osd) score 45 or sacrifice child
Feb 14 03:51:40 fr-paris kernel: Killed process 7657 (ceph-osd) total-vm:8650208kB, anon-rss:6124660kB, file-rss:1560kB
Feb 14 03:51:41 fr-paris systemd: ceph-osd@3.service: main process exited, code=killed, status=9/KILL
Feb 14 03:51:41 fr-paris systemd: Unit ceph-osd@3.service entered failed state.
Feb 14 03:51:41 fr-paris systemd: ceph-osd@3.service failed.
Feb 14 03:51:41 fr-paris systemd: cassandra.service: main process exited, code=killed, status=9/KILL
Feb 14 03:51:41 fr-paris systemd: Unit cassandra.service entered failed state.
Feb 14 03:51:41 fr-paris systemd: cassandra.service failed.
Feb 14 03:51:41 fr-paris ceph-mgr: 2017-02-14 03:51:41.978878 7f51a3154700 -1 mgr ms_dispatch osd_map(7517..7517 src has 6951..7517) v3
Feb 14 03:51:42 fr-paris systemd: Device dev-disk-by\x2dpartlabel-ceph\x5cx20block.device appeared twice with different sysfs paths /sys/devices/pci0000:00/0000:00:03.2/0000:03:00.0/host0/target0:0:0/0:0:0:9/block/sdj/sdj2 and /sys/devices/pci0000:00/0000:00:03.2/0000:03:00.0/host0/target0:0:0/0:0:0:4/block/sde/sde2
Feb 14 03:51:42 fr-paris ceph-mgr: 2017-02-14 03:51:42.992477 7f51a3154700 -1 mgr ms_dispatch osd_map(7518..7518 src has 6951..7518) v3
Feb 14 03:51:43 fr-paris ceph-mgr: 2017-02-14 03:51:43.508990 7f51a3154700 -1 mgr ms_dispatch mgrdigest v1
Feb 14 03:51:48 fr-paris ceph-mgr: 2017-02-14 03:51:48.508970 7f51a3154700 -1 mgr ms_dispatch mgrdigest v1
Feb 14 03:51:53 fr-paris ceph-mgr: 2017-02-14 03:51:53.509592 7f51a3154700 -1 mgr ms_dispatch mgrdigest v1
Feb 14 03:51:58 fr-paris ceph-mgr: 2017-02-14 03:51:58.509936 7f51a3154700 -1 mgr ms_dispatch mgrdigest v1
Feb 14 03:52:01 fr-paris systemd: ceph-osd@3.service holdoff time over, scheduling restart.
Feb 14 03:52:02 fr-paris systemd: Starting Ceph object storage daemon osd.3...
Feb 14 03:52:02 fr-paris systemd: Started Ceph object storage daemon osd.3.
Feb 14 03:52:02 fr-paris numactl: 2017-02-14 03:52:02.307106 7f1e499bb940 -1 WARNING: the following dangerous and experimental features are enabled: bluestore,rocksdb
Feb 14 03:52:02 fr-paris numactl: 2017-02-14 03:52:02.317687 7f1e499bb940 -1 WARNING: the following dangerous and experimental features are enabled: bluestore,rocksdb
Feb 14 03:52:02 fr-paris numactl: starting osd.3 at - osd_data /var/lib/ceph/osd/ceph-3 /var/lib/ceph/osd/ceph-3/journal
Feb 14 03:52:02 fr-paris numactl: 2017-02-14 03:52:02.333522 7f1e499bb940 -1 WARNING: experimental feature 'bluestore' is enabled
Feb 14 03:52:02 fr-paris numactl: Please be aware that this feature is experimental, untested,
Feb 14 03:52:02 fr-paris numactl: unsupported, and may result in data corruption, data loss,
Feb 14 03:52:02 fr-paris numactl: and/or irreparable damage to your cluster. Do not use
Feb 14 03:52:02 fr-paris numactl: feature with important data.
This seems to happen only in 11.2.0 and not in 11.1.x . Could you please help us in resolving this issue by means of any config change to limit the memory use on ceph-osd or a bug in the current kraken release.
Thanks,
Muthu
Files
{kind=link}
Updated by Marek Panek about 7 years ago
We observe the same effect in 11.2. After some time OSDs consume ~6G RAM memory (12 OSDs per 64G RAM server) and finally got killed by OOM.
8700 ceph 20 0 6687476 5,286g 0 S 6,0 8,4 453:41.07 ceph-osd
8525 ceph 20 0 6531072 5,286g 0 S 3,3 8,4 410:53.50 ceph-osd
8921 ceph 20 0 6403132 5,178g 0 S 3,3 8,2 478:13.86 ceph-osd
8942 ceph 20 0 6360136 5,147g 0 S 4,0 8,2 463:37.74 ceph-osd
8841 ceph 20 0 6387304 5,141g 0 S 6,3 8,2 479:56.43 ceph-osd
8625 ceph 20 0 6439932 5,132g 0 S 4,0 8,2 485:43.86 ceph-osd
8703 ceph 20 0 6366108 5,114g 0 S 2,0 8,1 433:00.83 ceph-osd
8621 ceph 20 0 6366424 5,082g 0 S 12,3 8,1 499:04.82 ceph-osd
8577 ceph 20 0 6398816 5,036g 0 S 3,6 8,0 390:14.41 ceph-osd
8551 ceph 20 0 6274940 4,969g 0 S 5,0 7,9 417:29.32 ceph-osd
5105 ceph 20 0 6016388 4,898g 0 S 5,6 7,8 200:36.20 ceph-osd
27040 ceph 20 0 5793032 4,685g 0 S 6,6 7,5 211:34.08 ceph-osdThey are 4TB OSDs.
Updated by Marek Panek about 7 years ago
Marek Panek wrote:
We observe the same effect in 11.2 with bluestore. After some time OSDs consume ~6G RAM memory (12 OSDs per 64G RAM server) and finally got killed by OOM.
8700 ceph 20 0 6687476 5,286g 0 S 6,0 8,4 453:41.07 ceph-osd
8525 ceph 20 0 6531072 5,286g 0 S 3,3 8,4 410:53.50 ceph-osd
8921 ceph 20 0 6403132 5,178g 0 S 3,3 8,2 478:13.86 ceph-osd
8942 ceph 20 0 6360136 5,147g 0 S 4,0 8,2 463:37.74 ceph-osd
8841 ceph 20 0 6387304 5,141g 0 S 6,3 8,2 479:56.43 ceph-osd
8625 ceph 20 0 6439932 5,132g 0 S 4,0 8,2 485:43.86 ceph-osd
8703 ceph 20 0 6366108 5,114g 0 S 2,0 8,1 433:00.83 ceph-osd
8621 ceph 20 0 6366424 5,082g 0 S 12,3 8,1 499:04.82 ceph-osd
8577 ceph 20 0 6398816 5,036g 0 S 3,6 8,0 390:14.41 ceph-osd
8551 ceph 20 0 6274940 4,969g 0 S 5,0 7,9 417:29.32 ceph-osd
5105 ceph 20 0 6016388 4,898g 0 S 5,6 7,8 200:36.20 ceph-osd
27040 ceph 20 0 5793032 4,685g 0 S 6,6 7,5 211:34.08 ceph-osdThey are 4TB OSDs.
Updated by Wido den Hollander about 7 years ago
- Category set to 107
- Source set to Community (user)
- Tags set to bluestore,kraken,memory
This was discussed during Yesterday's performance meeting and Sage suggested that this is indeed a memory leak.
Although lowering bluestore_cache_size seems to fix it it only masquerades the real issue.
bluestore_cache_size is also not a setting per shard, but it's divided by the amount of shards inside the code.
Try running with 'debug_mempools = true' and then run:
ceph daemon osd.X dump_mempools
Updated by Nathan Cutler about 7 years ago
- Related to Bug #18926: Why osds do not release memory? added
Updated by Jaime Ruiz about 7 years ago
Fixed with the following commands:
The memory is released by applying the following commands in a content node:
968 28/03/17 12:51:28 systemctl start ceph-mgr@cn5.service
969 28/03/17 12:51:33 systemctl status ceph-mgr@cn5.service
972 28/03/17 12:52:37 systemctl stop ceph-mgr@cn5.service
We can see how the memory is released here:
cn5.vn1ldv1c1.cdn ~# sar -r 1 -f /var/log/sa/sa28 | grep PM
12:00:02 PM 26310136 369715512 93.36 354416 1753244 376096532 94.97 288524784 854352 32
12:10:01 PM 30571164 365454484 92.28 1146264 1861208 370760812 93.62 283487992 1661652 48
12:20:01 PM 29749384 366276264 92.49 1641044 1863668 370914752 93.66 283952176 2013512 188
12:30:01 PM 29285088 366740560 92.61 2174092 1794624 371147340 93.72 284120960 2328764 32
12:40:01 PM 28929392 367096256 92.70 2389656 1802116 371380628 93.78 284346764 2394176 40
12:50:01 PM 28524076 367501572 92.80 2349836 1796560 371526164 93.81 284879696 2197292 40
01:00:01 PM 160678156 235347492 59.43 2859676 1806632 371668548 93.85 152318728 2561288 516
01:10:01 PM 154097068 241928580 61.09 8666108 1804952 373251920 94.25 155266968 6171812 32
01:20:01 PM 153453208 242572440 61.25 8883900 1916188 373617584 94.34 156084024 5992300 16
01:30:01 PM 153278356 242747292 61.30 8734576 1925748 373754680 94.38 156598692 5622352 8
01:40:01 PM 153312836 242712812 61.29 8087932 1928984 374131420 94.47 157366324 4794936 32
01:50:01 PM 154681508 241344140 60.94 6972484 1934452 374446920 94.55 156447128 4292416 8
02:00:01 PM 154454348 241571300 61.00 7026772 1938780 374585740 94.59 156656448 4277764 8
02:10:01 PM 154680956 241344692 60.94 7001188 1942524 374724676 94.62 156383224 4289180 8
02:20:01 PM 154634124 241391524 60.95 6920016 1935084 374887256 94.66 156468928 4223128 8
Updated by Jaime Ruiz about 7 years ago
We decided to stop the ceph-mgr service in all the nodes because is using lot of CPU and we understood that this service was not required.
Updated by Muthusamy Muthiah about 7 years ago
Hi Jaime,
The issue not fixed with this workaround, and we will address this workaround in another issue related to ceph-mgr
http://tracker.ceph.com/issues/18994. Clearly the above updates are side effects of stopping ceph-mgr due to high CPU utilisation.
This ticket is still valid , has to solve the memory leak issue and the current workaround is to reduce bluestore_cache_size from 1GB to 100MB.
Regards,
Muthu
Updated by Nokia ceph-users about 7 years ago
This is a bug with the ceph-mgr service -->> http://tracker.ceph.com/issues/19407 and currently set to need review state.
Updated by Nokia ceph-users about 7 years ago
sorry wrong window . ignore my previous comment
Updated by Aaron T about 7 years ago
I'm experiencing this runaway memory issue as well. It only appeared a couple of days ago. I tried setting the bluestore cache directive to ~100MB ( "bluestore_cache_size": "107374182") but this has not had a noticeable effect on the problem. Two OSD hosts with 64GiB RAM and ~13 bluestore OSDs have suddenly been OOM killing ceph-osd procs when memory pressure is exceeding 128GiB (RAM+swap)...
This 11.2.0 cluster has been running just fine for ~2 months before this issue suddenly appeared, with no discernible change in usage patterns and no hardware/software reconfiguration. Very strange.
Updated by Greg Farnum almost 7 years ago
- Project changed from Ceph to RADOS
- Category changed from 107 to Performance/Resource Usage
- Component(RADOS) BlueStore added
Updated by Sage Weil almost 7 years ago
- Status changed from New to Fix Under Review
https://github.com/ceph/ceph/pull/15792
should help
Updated by Sage Weil almost 7 years ago
- Status changed from Fix Under Review to Pending Backport
Updated by Nathan Cutler almost 7 years ago
master PR: https://github.com/ceph/ceph/pull/15295
kraken backport PR: https://github.com/ceph/ceph/pull/15792
Updated by Nathan Cutler almost 7 years ago
- Copied to Backport #20366: kraken: kraken-bluestore 11.2.0 memory leak issue added
Updated by Nathan Cutler almost 7 years ago
- Status changed from Pending Backport to Resolved